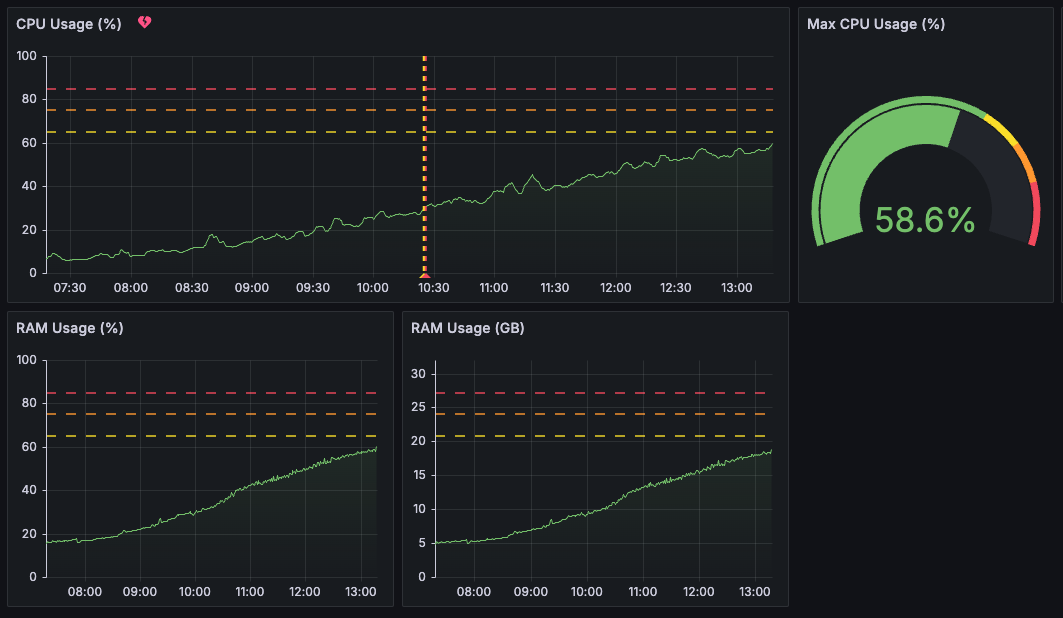
Describe the problem/error/question
I’m experiencing a gradual increase in CPU usage on my n8n worker instances over time.
My n8n setup is configured in queue mode with the following architecture:
• 1 main instance (version 1.76.1)
• 3 worker instances (version 1.76.1) with 20 parallel executions each
• 1 RabbitMQ instance
• 1 Redis instance
• 1 PostgreSQL instance
The issue is that the CPU usage of the workers steadily grows, even when the workload remains consistent. Eventually, this leads to performance degradation and requires restarting the workers to stabilize the CPU usage again.
I’d appreciate any insights into potential causes for this behavior and suggestions on how to mitigate or debug the issue.
What is the error message (if any)?
I’m not facing any error message.
The only weird behavior is my Redis bull/jobs showing approximatelly 493 registers and some of them with errors like:
“job stalled more than allowable limit”
“Connection terminated due to connection timeout”
“timeout exceeded when trying to connect”