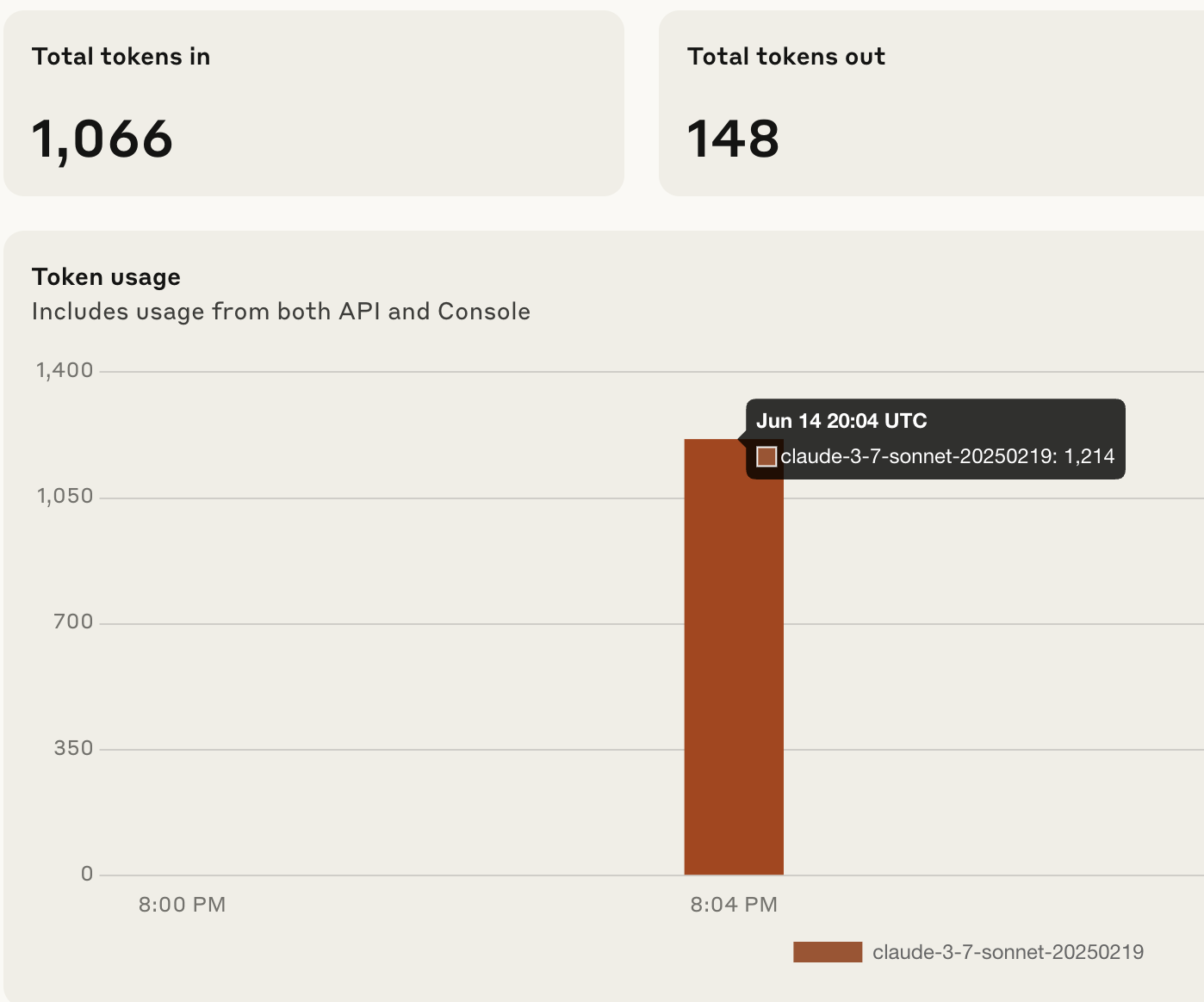
I’m wondering how tokens for each LLM are calculated.
Based on a few tests, it looks accurate with OpenAI (not exact, but quite accurate), but with Claude, it’s completely off - see screenshots.
435 tokens estimated by n8n vs 1214 in Claude console.
Yes, brand new API key, only used in 1 workflow → 1 agent → 2 runs.
How are the tokens estimated? Would there be a way to get a more accurate number?
While I have not looked at the code (which you can do to see except how since it’s source available) I can make a pretty good assumption since I’m familiar with the ai apis
Every one I used gives information about how many tokens you have used in the response and even breaks it down by category. I’m sure they would be using that info
Are you sure you aren’t running the agent multiple times by accident? That is a common issue. If multiple items are passed into the agent it will run once for each item (unless set other wise in the node settings)
If it’s not that, considering the large difference there they might have some logical error in the way they’re adding up the tokens
I’ve looked into the codebase with GH copilot.
In some cases, the actual token count is not returned by Claude (didn’t find why) so n8n makes an estimate. My test was with an AI Agent, so that might be the reason.
This is clearly stated by n8n in the GUI and API actually - see screenshot in initial post: tokenUsageEstimate vs normally tokenUsage
Here is the Copilot response:
If the model does not return exact counts, n8n estimates token usage.
The estimation is done by serializing the relevant object (such as the prompt or schema) to JSON, measuring its string length, and dividing by an average token length.
The average token length is a configurable value (not hardcoded here), and this method gives an approximate token count.
An issue could be the averageTokenLength variable that doesn’t work well for Claude’s tokenization (not sure how different it is from OpenAI’s for instance)