Hi,
I think I’ve found a way to handle it. Before I proceed, could you share what the table structure looks like (e.g. column names and sample data)?
Also, could you clarify what exactly you would like the AI to analyze or check in each row?
And what kind of results should we collect back — a summary, a specific flag, or something else?
Let me explain what I’m trying to achieve in more detail:
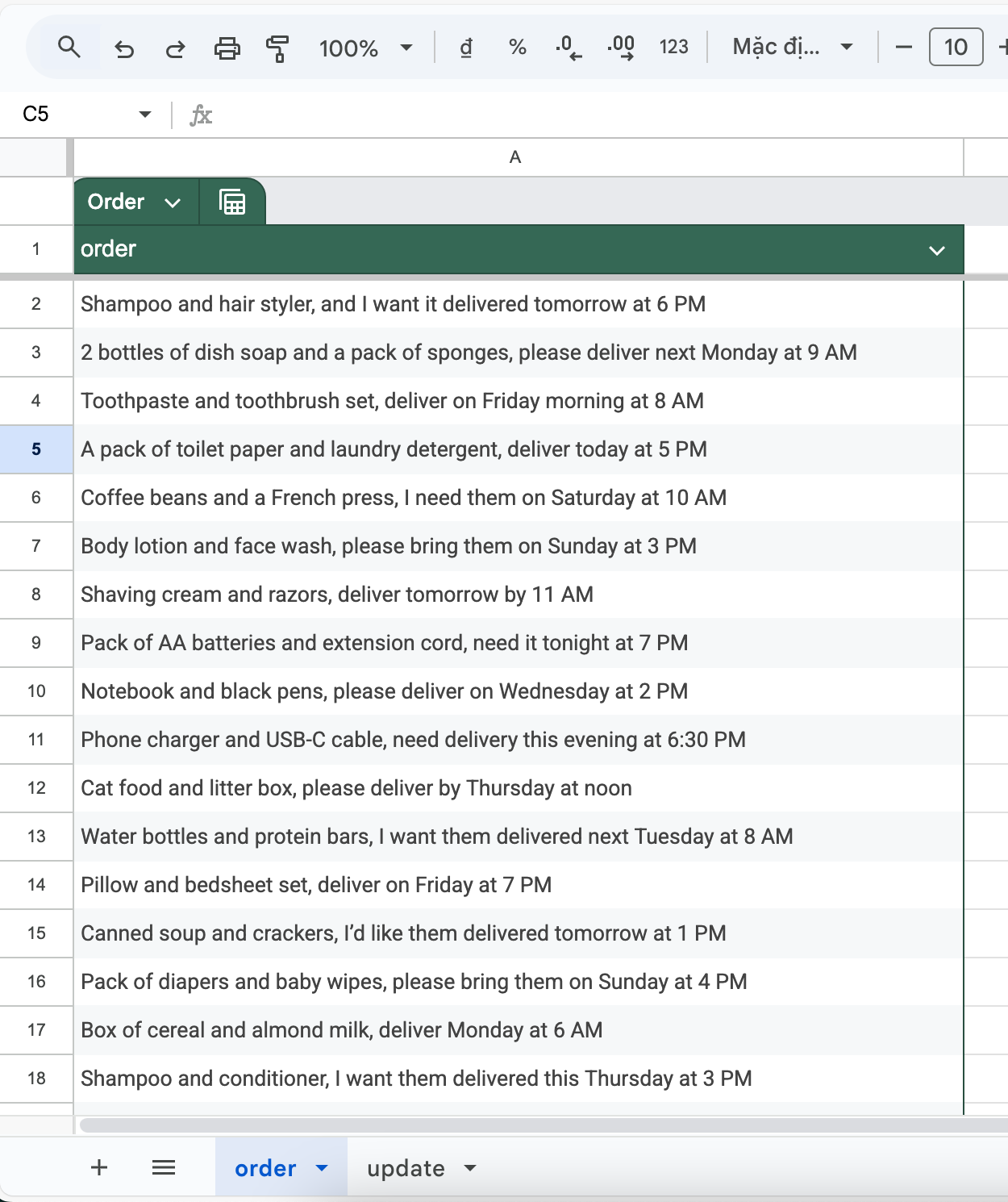
I have a Google Sheet with one main column called order which contains free-text user requests.
Example:
Shampoo and hair styler, and I want it delivered tomorrow at 6 PM
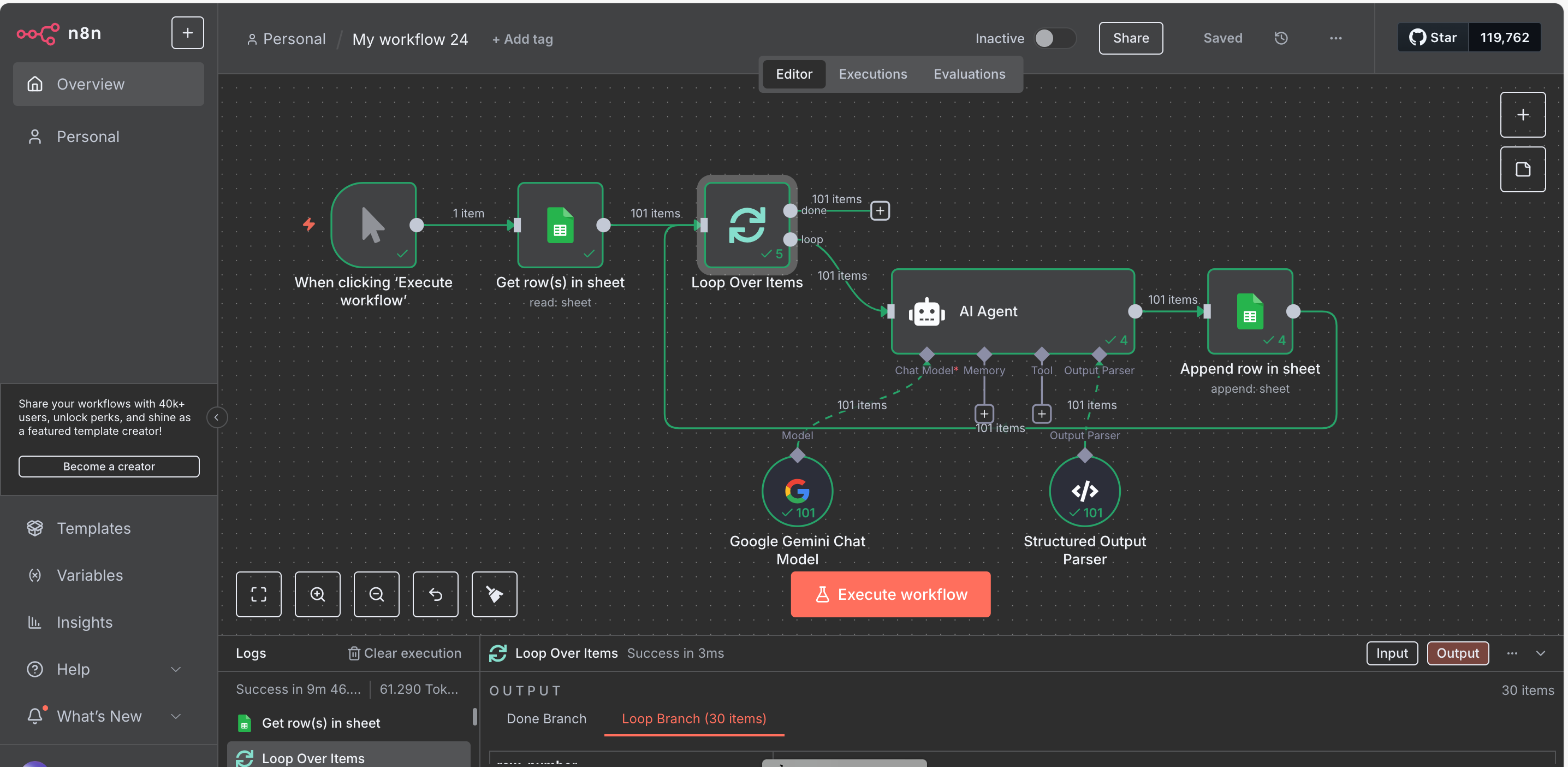
There could be hundreds of orders, so I want to process them in batches of 30 to make it efficient and avoid rate limits or token issues.
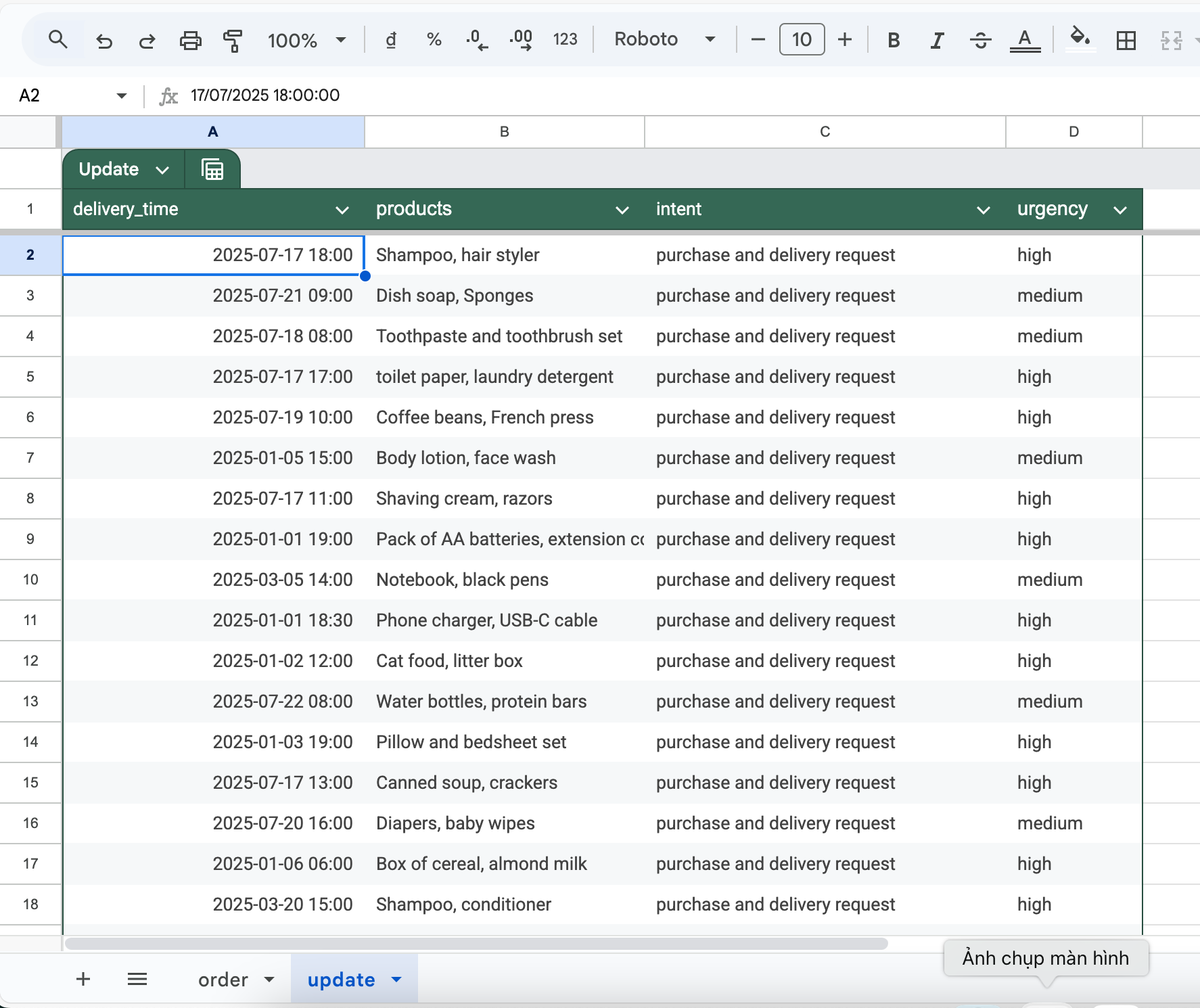
I already have a working system to analyze each order using an LLM (Large Language Model).
Each input gets parsed and returned as a JSON object like this:
I truly appreciate your effort, and the solution you provided is indeed correct — I had actually considered it as well. However, I apologize that I won’t be able to share this specific information with you.
The reason is that the number of input tokens in OpenAI is limited — It’s around 4000 tokens — and I’m concerned that if I have more than 200 orders, the total token count might exceed this limit, which could cause issues on my side.
That’s why I’m thinking of sending the orders to OpenAI one by one to avoid hitting the token limit.
I also tried using a loop with a batch size of 30, and inside that loop I added another loop to process each of the 30 rows individually. However, on the second batch, the inner loop ran 60 times instead of 30.
I also experimented with SplitInBatches, but in the second iteration it seems to stop, possibly because the previous state is being stored or not reset properly.
I was also stuck in a similar issue. One possible solution is to maintain a column for execution tracking annd update it to true or something and read the column for the ones not executed and process them one by one and update. The loop over in my case was not working properly.
“The reason is that the number of input tokens in OpenAI is limited — It’s around 4000 tokens — and I’m concerned that if I have more than 200 orders, the total token count might exceed this limit, which could cause issues on my side.”
If you’re concerned, you can add a status column and schedule the workflow to run every 15 minutes. Each run can process ~100 items, then update their status and result.
@alexhuy Do you have any solution to my problem: So the issue is there is complex logic involved and when I’m looping back after processing 20 items , the logi still holds the data of previous execution and all the output is wrong eventually. Any way to reset everything after every batch process?