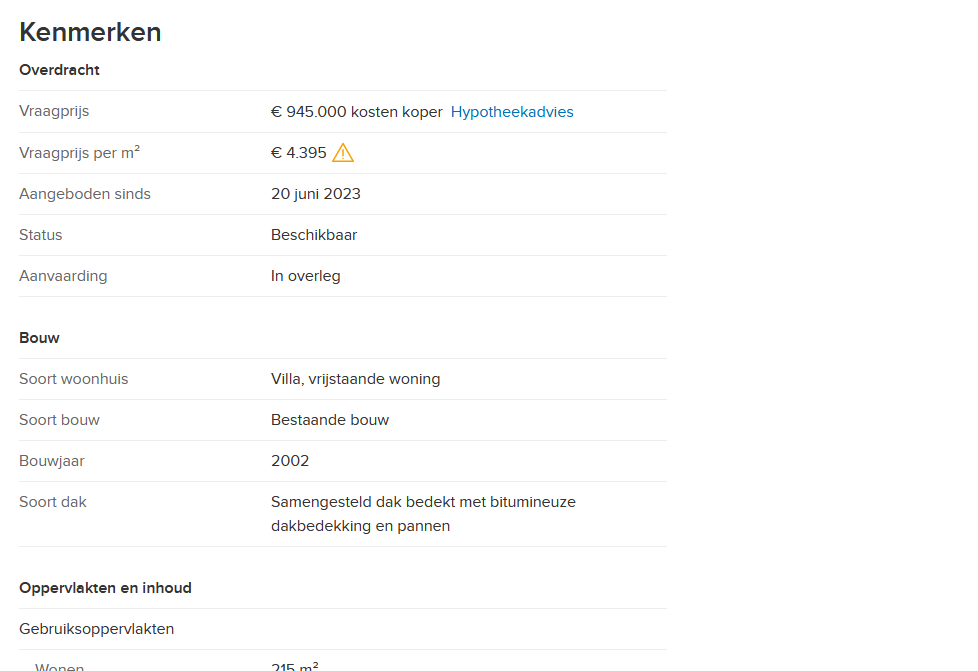
Is there a more experienced N8N user around that can give me a lead on how to convert the html into a nice list of labels and values (without section headers)?
At the moment I have attempted to extract the list of labels and values from this page:
At a glance, the url you want to extract data from protects the browser queries through a temporary cookie. So if you don’t include those values, the html that your example HTTP node is fetching doesn’t include the data you precisely want to extract.