Describe the problem/error/question
Hi, first post so go easy ![]() I have been using n8n and loving it but cant workout how to pull all the nodes from a JSON request. I have tried searching the forum and found lots of other help but nothing on this.
I have been using n8n and loving it but cant workout how to pull all the nodes from a JSON request. I have tried searching the forum and found lots of other help but nothing on this.
I am trying to take a Google Slides file (although the question is generic), find all nodes that match a specific type and return them. Example:
Root
–Page
—PageId: 12
—Text
----Content: TEST123
----Stuff
----Stuff
-----Other
—Text
----Content: TEST321
----Stuff
----Stuff
-----Other
— Shape
–Page
—PageId: 123
—Text
----Stuff
----Stuff2
–Page
—PageId: 1234
—Text
----Content: TEST11
----Stuff
----Stuff
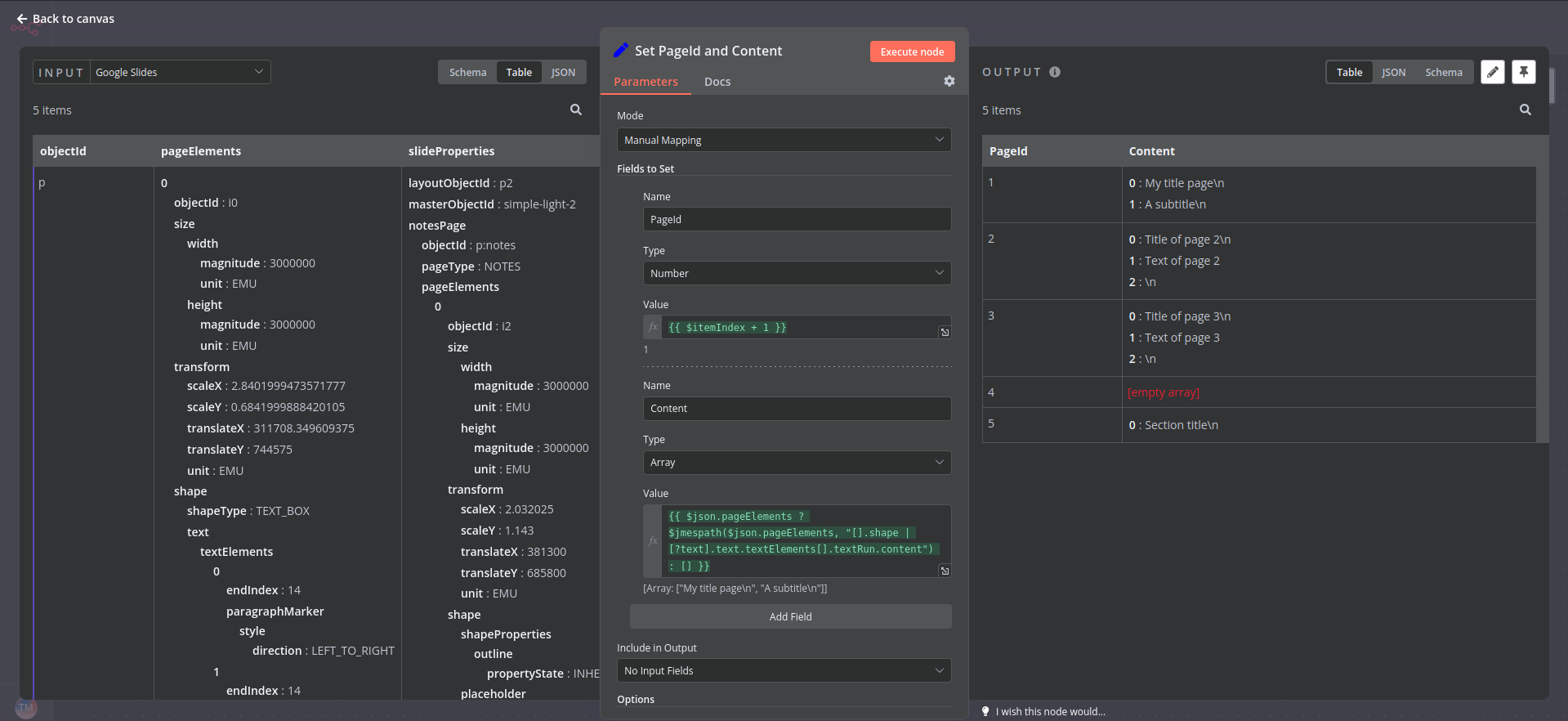
I would like get a response with the PageId any any content whenever it exists. In the above it would
PageId: 12,Content: TEST123
PageId: 12,Content: TEST321
PageId: 1234,Content: TEST11
I know i can pull the first one by using direct links in the expression:
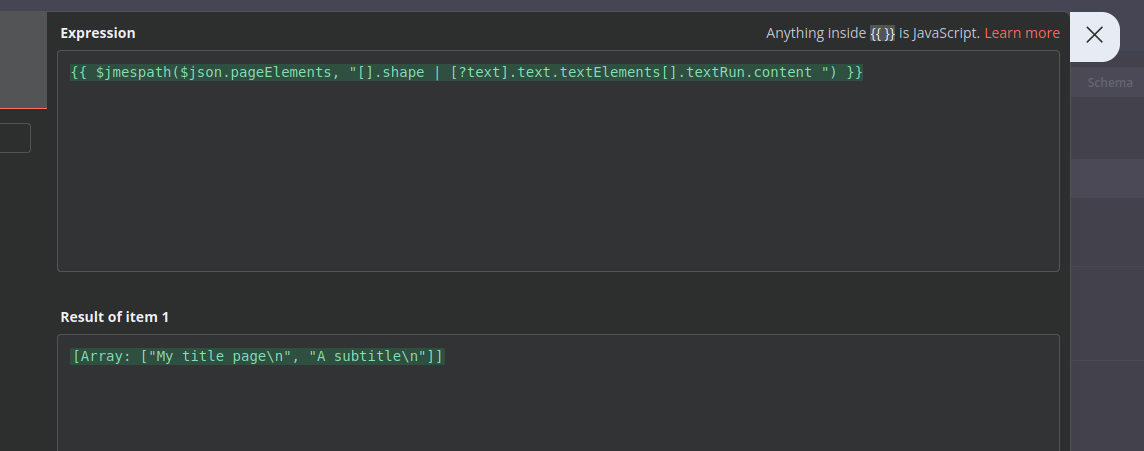
e.g. {{ $json.Root[0].Page[0].Text[0].content }}
The real names are: “content” and “objectId”
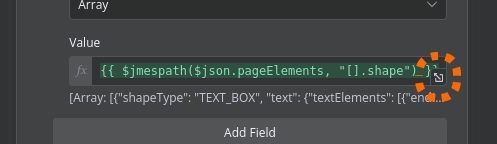
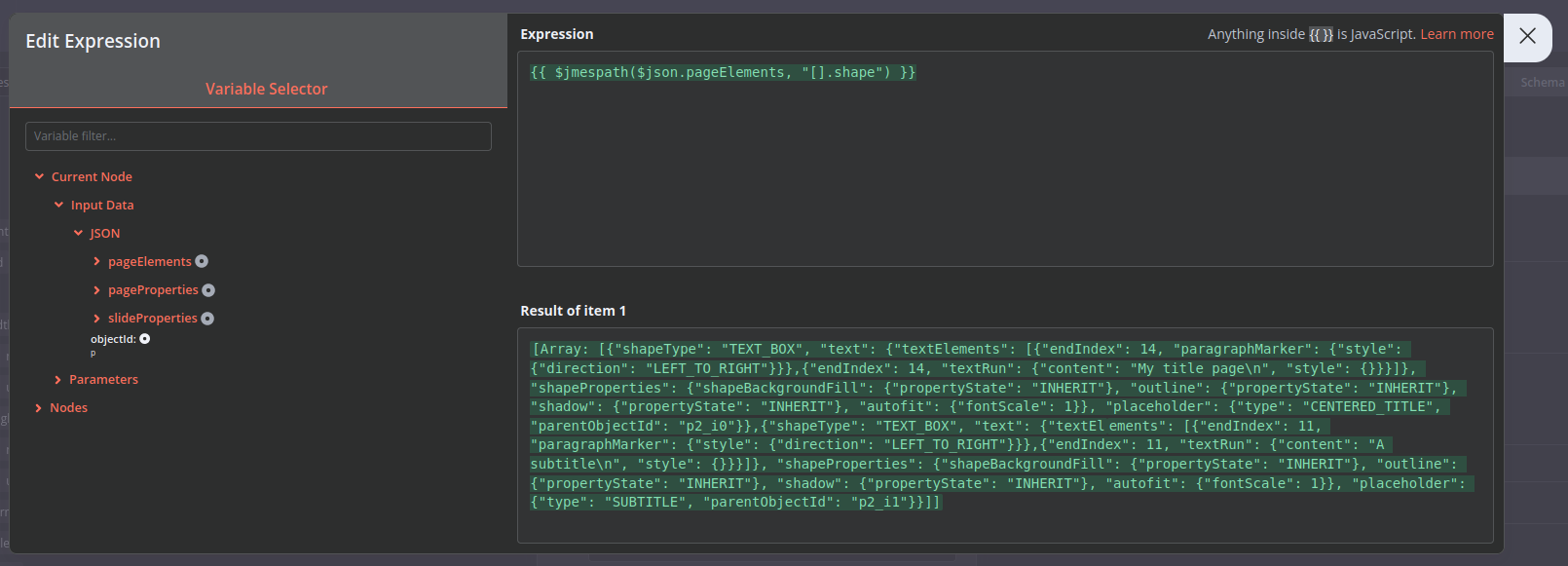
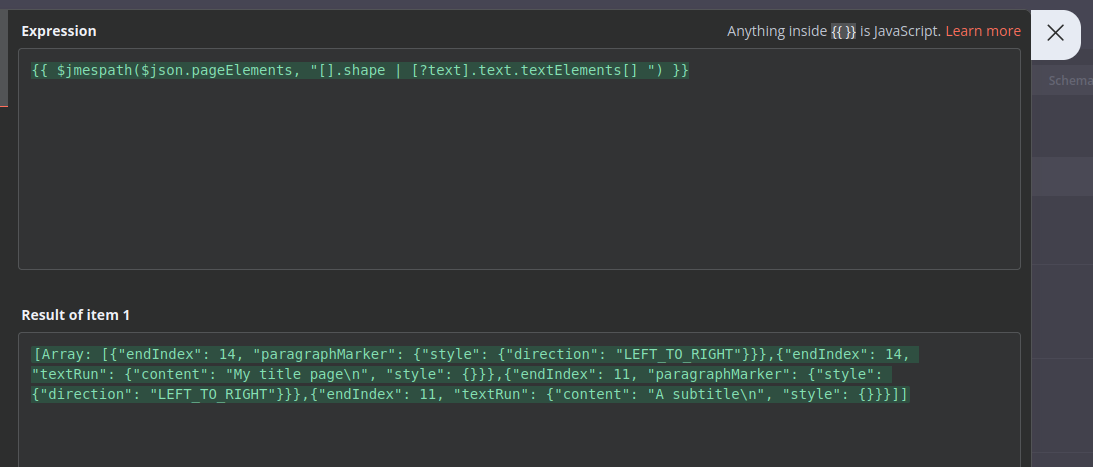
slides[0].pageElements[0].shape.text.textElements[1].textRun.content
slides[0].pageElements[0].objectId
So i guess the real question is can I change the array locations to be “all” instead of a number?
Please share your workflow
Share the output returned by the last node
Output from the node is very large so its on justpaste: https://justpaste.it/cra3z
Information on your n8n setup
- n8n version: Cloud