Dear all,
I have questions regarding how langchain and n8n handle deterministic JSON output for OpenAI and MistralAI.
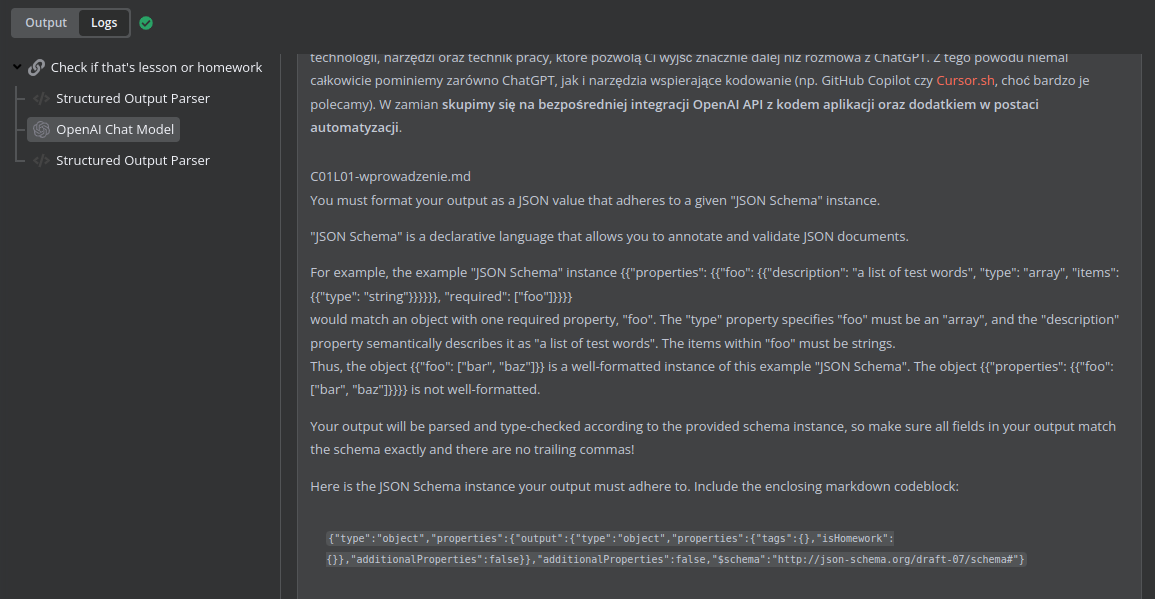
From what I understand. OpenAI used to take a JSON schema as input parameter but it is not the case anymore !? We have to explicitly ask the LLM to output a JSON.
But how can I make sure it is deterministic ?
How does langchain and n8n handle it ?
Should I use function calling instead ?
yes, that’s possible especially for GPT 3.5, for GPT4 I did not experience that.
There is also auto fix sub node, did not use it yet, but if you need to be sure that execution will not fail that might be worth to have a look:
Let say that the model gives 1% incorrect json format:
If I use auto-fixing output format, it lowers the probability without removing it : 0.01 * 0.01 = 0.0001
If I use retry on fail with max tries to 3: 0.01^3 = 0.000001
It is not deterministic.
What about using function calling for deterministic JSON output format ?
The workflow I am planning to do will process up to 10000 requests and I cannot afford a single fail… If I increase the max tries variable, it could become expensive regarding the number of requests.
Maybe someone else will be able to help you better. I can only say that for GPT-3.5, it sometimes generates incorrect JSON. A good prompt makes a big difference, but AI is by design not deterministic, so I think that you will not be able to make sure that the AI returns correct JSON in 100% of cases. However, you could use the autofix subnode, which might make it happen, but I don’t have experience with that
You mentioned function calling, so do you know about the AI Agent node that can gather tools and make decisions by itself which to use? I also haven’t used it much, but maybe that could help you somehow
You mentioned function calling, so do you know about the AI Agent node that can gather tools and make decisions by itself which to use? I also haven’t used it much, but maybe that could help you somehow
Yes I have already used it but the way langchain is integrated in n8n won’t allow me to access the JSON output between LLM and the actual call of the tool in n8n. I want to have access to the raw output like: