Describe the problem/error/question
I cannot understand how upstream values work when processing items. Please help!
It is VERY common for me to have a downstream module that needs to access some of the info from upstream. For example, after an API query or SQL query, I want to do something that depends on both the parameters that were fed to the query and the results of the query.
What is the problem?
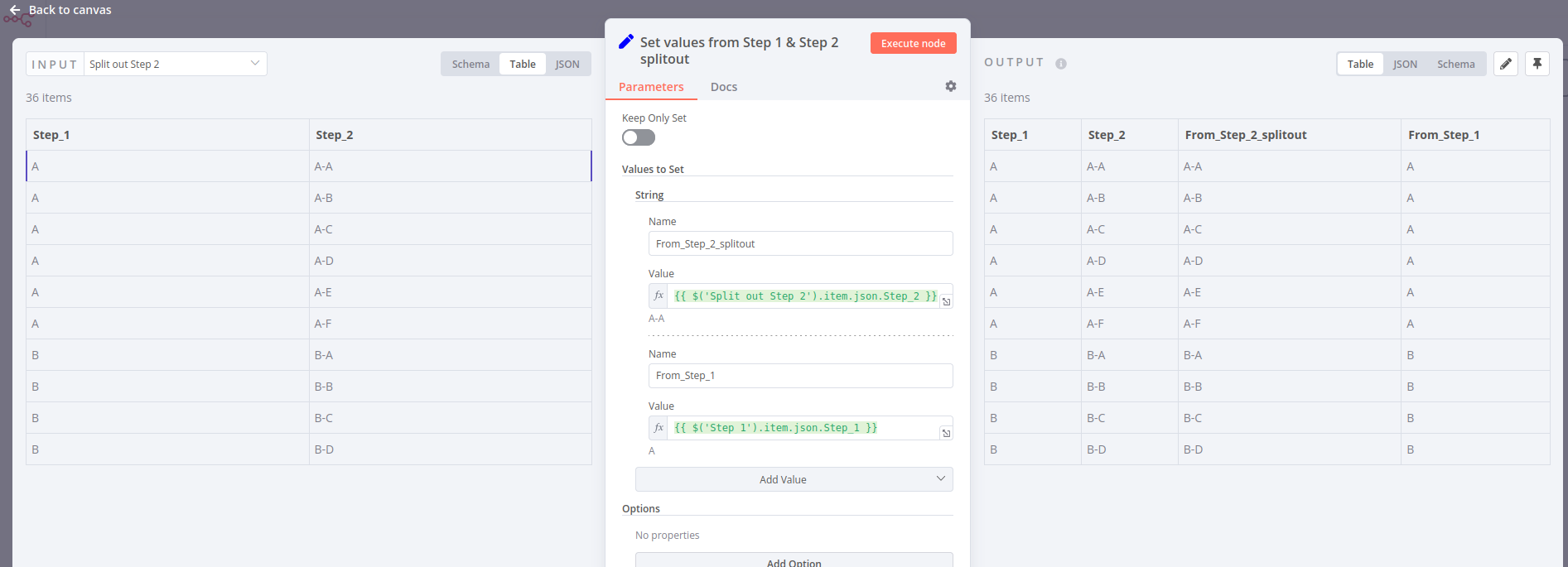
The problem is that my intuition is failing me! This example has 6 parameters which each return 6 values, so we get 36 items. Downstream, I’d like to do something with each of those 36 results that relies on the original 6 parameters. But the linkage seems to get lost after the HTTP or SQL module. I’ve tried all kinds of complicated schemes to get around this. I’m not sure why this is hard. Shouldn’t upstream results just be “carried along”, or at least easily referenced?
Someone please help me understand what’s happening?
Please share your workflow
This example should run with any MySQL credential. If you don’t happen to have a MySQL database, the same query will probably work in other SQL modules and will probably have the same effect.
Share the output returned by the last node
The final Set module tries to pull upstream values. My intuition says that the values it sets for “From_Step_2_Splitout” and “From_Step_1” should be the same as the values in MySQL_Step_1 and MySQL_Step_2. But they’re always just the first values output by those upstream steps.
Why? How do I access the upstream values that generated the specific downstream values that I’m processing for each item?
[
{
"sql": "select 'A' as MySQL_Step_1, 'A-A' as MySQL_Step_2",
"data": {
"MySQL_Step_1": "A",
"MySQL_Step_2": "A-A"
},
"From_Step_2_splitout": "A-A",
"From_Step_1": "A"
},
{
"sql": "select 'A' as MySQL_Step_1, 'A-B' as MySQL_Step_2",
"data": {
"MySQL_Step_1": "A",
"MySQL_Step_2": "A-B"
},
"From_Step_2_splitout": "A-A",
"From_Step_1": "A"
},
{"..."}
{
"sql": "select 'B' as MySQL_Step_1, 'B-D' as MySQL_Step_2",
"data": {
"MySQL_Step_1": "B",
"MySQL_Step_2": "B-D"
},
"From_Step_2_splitout": "A-A",
"From_Step_1": "A"
},
{"..."}
{
"sql": "select 'F' as MySQL_Step_1, 'F-F' as MySQL_Step_2",
"data": {
"MySQL_Step_1": "F",
"MySQL_Step_2": "F-F"
},
"From_Step_2_splitout": "A-A",
"From_Step_1": "A"
}
]
Information on your n8n setup
- n8n version: 0.236.2
- Database (default: SQLite): MySQL
- n8n EXECUTIONS_PROCESS setting (default: own, main): own
- Running n8n via (Docker, npm, n8n cloud, desktop app): npm & pm2
- Operating system: Ubuntu