You do realize that this is exactly why service owners use cloudflare in the first place, right? If they require human verification, they do not wish their services to be exposed to automated systems / crawlers.
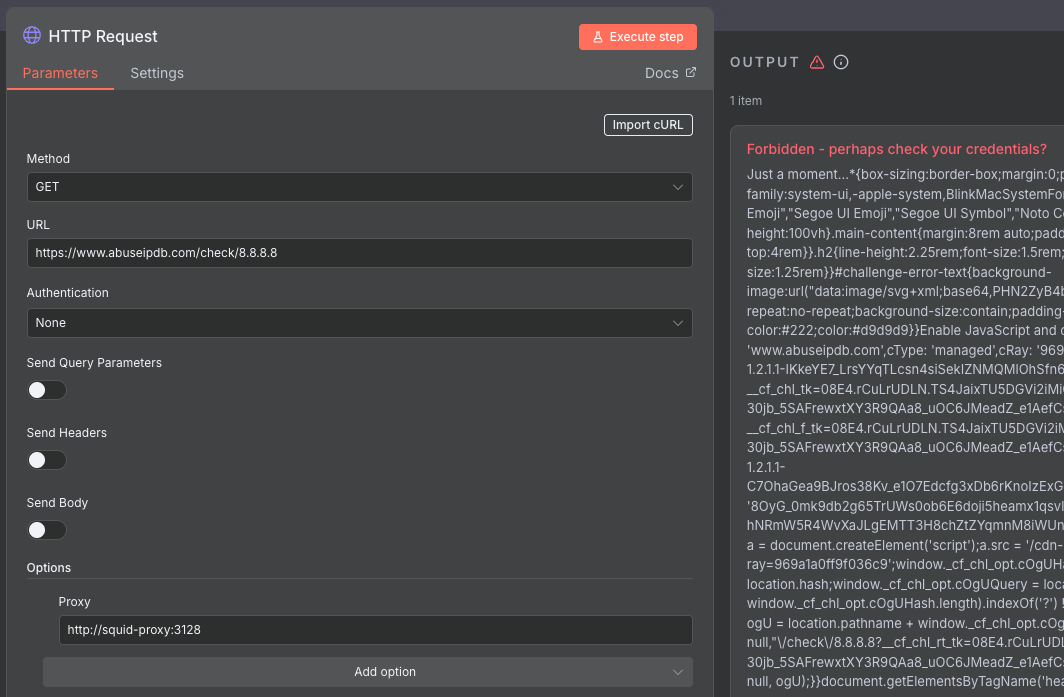
Out of curiosity, I tried routing requests through squid. In my opinion using squid is not sufficient to overcome very comprehensive cloudflare protection, so this topic caught my eye.
What I did.
I copied your configuration of the squid.conf
(by the way, 172.18.0.0/16 is a subnet of 172.0.0.0/8, which makes the localnet source of 172.18.0.0/16… redundant?)
brought up the squid container within my compose infrastructure
Why I think squid may not be the best way to go about bypassing cloudflare protection (not that anyone should, khm-khm):
To start with, squid doesn’t offer any IP rotation or residential proxy - the proxy still uses the same public IP of the host machine. If that IP is flagged or rate-limited, nothing changes.
Squid provides no user-agent spoofing, JS challenge solving, or cookie handling - most serious Cloudflare protections (especially for sites behind “I’m Under Attack” mode or using so called bot fight mode) require a browser-like client to solve JavaScript challenges and present valid tokens.
If the website/API uses Cloudflare’s Bot Management then simply going through Squid won’t bypass it - they look at TLS fingerprints, JA3 hashes, behaviour, etc.
If you hit a CAPTCHA or JS challenge, curl (or n8n for that matter) won’t solve it. Cloudflare will still block.
I am really interested to know how and most importantly why would it work for you though. What do you think could be different in your setup that makes it work?
I used: https://api.abuseipdb.com/api/v2/check?ipAddress=113.30.176.33&maxAgeInDays=90(API call)
with header: Key: YOUR_API_KEY
If you’re scraping and looking to bypass Cloudflare protection, I’d suggest using ScraperAPI or a similar service.
I tested ScraperAPI and it worked fine — even with Squid proxy running.
Test setup:
In the proxy field, instead of using Docker’s internal hostname like squid-proxy,
I pointed it to my public IP and Squid port. (my case, i hosted in hostinger kvm2)
ScraperAPI handled all JS/cookie challenges, and I got a valid HTML response.
Conclusion:
If you’re making official API calls, use AbuseIPDB’s API directly — it’s clean and reliable.
If you’re scraping web pages behind Cloudflare, Squid alone isn’t enough — but combining it with ScraperAPI works well.
Fair enough, I changed my setup to be more similar to yours (even though API endpoints are protected by the same Cloudflare as the web pages and Cloudflare protection was supposedly bypassed by using squid).
I changed the requests from direct website url to the API url with the key in the header. I tried running the workflow without squid and didn’t have a problem even without it. Now I have sent over 200 requests for different IPs and got every single response back.
At this point I have everything working with and without squid when I use API instead of hitting the web pages directly.
I actually got stuck on this phase for past 2 days — came across your question while googling, and once I figured it out after trying everything, I came back to share the solution here.