Hello,
I wanted to make scrapper for job listing and it work just fine, but it looks like it would return only last page ;/
I am not sure what’s wrong but maybe the set merger is wrong set up ;/
WF:
Online output: https://n8n.hryszko.dev/webhook/05b4ab4d-447a-44d3-8097-810bd2029356?lang=python
Example output (for future users if link does not work): pastefile1 · paste.gg
Thanks in advance for tips ;))
You’d need an actual merge node (or actually two) - otherwise each item lists node would call the final Set node individually.
Check out this example:
Hope this helps 
Tbh, I haven’t looked at the rest of the workflow, just at the merge problem 
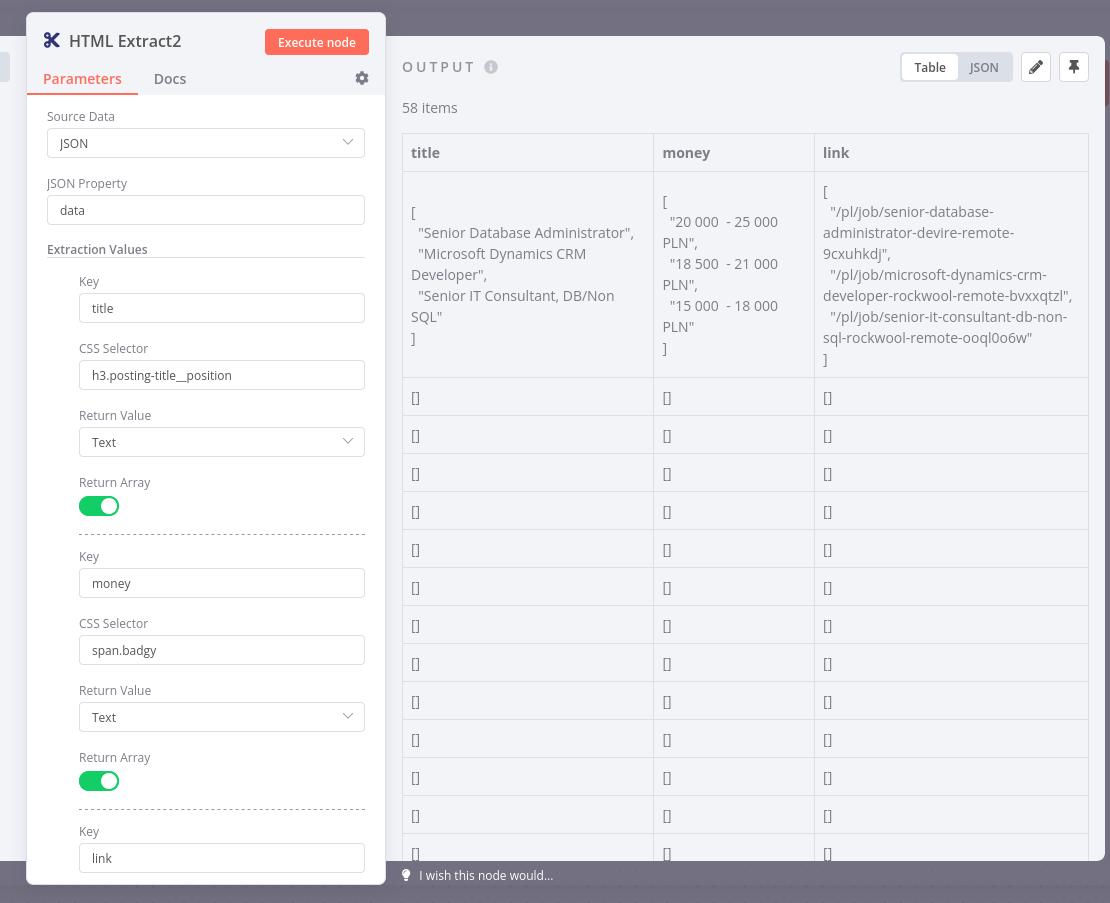
You’re right, it returns three items, but this seems to be expected. There are only three values returned by your HTML Extract 2 node, the other arrays are empty:
Which data exactly are you missing?
If you’re looking to extract data from Praca Python | Praca IT | Zdalnie | Sierpień | No Fluff Jobs, you might want to take a look at the network request made by that page. It could be easier to process the JSON data provided by this API rather than build a web scraper. Something like this perhaps:
1 Like
You are life saver 
Thanks that helped a lot <3
1 Like
No worries, and sorry for my initial confusion. Clearly it’s time to stop working for the week
1 Like