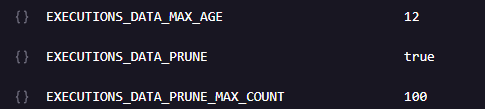I’m using slef hosted n8n on Railway which is using a Postgres DataBase. The volume of data was going up in the DB (executions and binary data from Google Drive downloads) and it crashed because limits were reached.
I increased the limits, it works OK, then added the following ENVIRONMENT VARIABLES for the n8n service in Railway, but the size of the Postgres volume is not going down (the violume grew before the set 12 hours for EXECUTIONS_DATA_MAX_Age so it should have reduced by now.
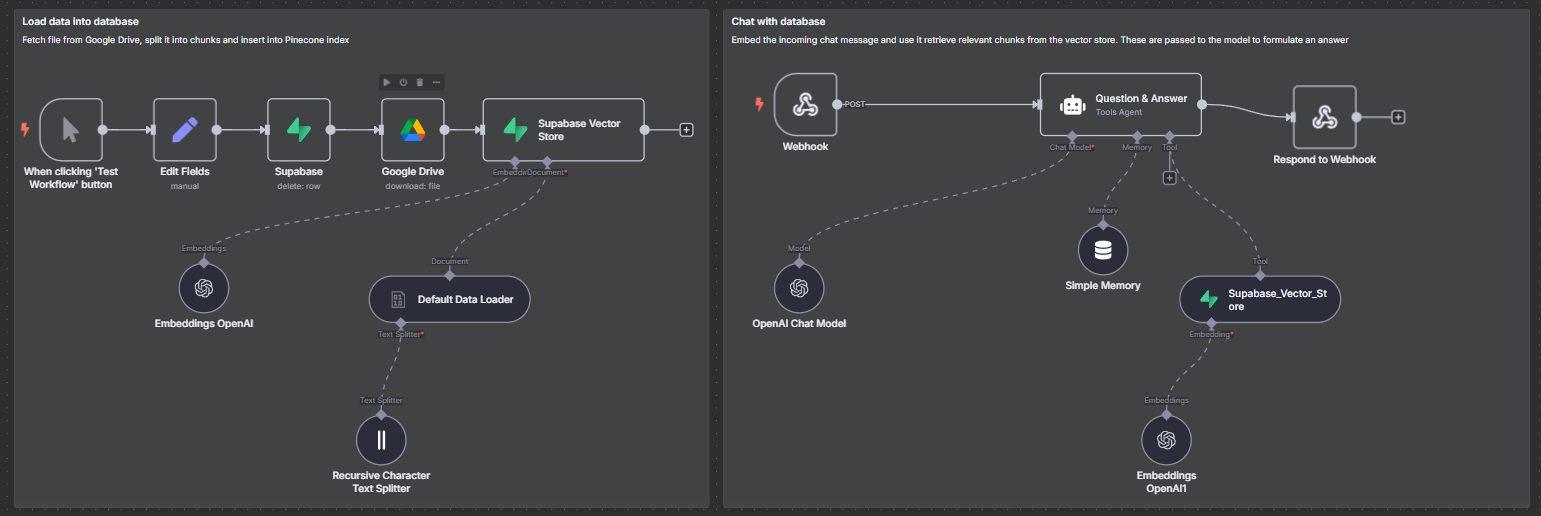
Below is the flow, and the only data that I’d expect to be stored, is the execution logs, binar data from the Google Drive Download, and maybe the Simple Memory node, but I also expected all these to be pruned/deleted with the ENVIRONMENT VARIABLES.
There’s a chance your usage pattern for storage in Postgres wouldn’t be fully mitigated by managing the retention. There are some DB management functions to actually free space that might be necessary too.
See if this article gives you any insight in to what might be going on.
Thanks @hubschrauber I saw similar advice elsewhere to try VACUUM; and VACCUM FULL; on the execution_data table
I tried both and the volume usage decreased slightly but not much.
To test, I created a fresh install of n8n on Railway and it had about 200Mb volume usage for Postgres, When using the flows it went up very slightly by only a couple of Mb.
When using Google Drive or FTP to download files to created embeddings for a vector store in a different Postgres DB on Supabase, the Postgres on railway obviously went up more for each PDF used (size of PDF + some more) to create the embeddings
I have to wait just over 12 hours (time for execution data to be pruned in n8n) to try VACCUM; & VACCUM FULL; on this new instance of n8n to see what happens.
However as most if not all the pruning should have happened by now on the first instance of n8n, VACCUM & VACCUM full ony reduce the Posgress volume for that instance to about 500MB from about 800Mb. All execution_data in the table has been deleted. That’s an additional 300Mb than a fresh install and I only have a handful of quite simple inactive flows whose JSON downloads are about 100Kb in total.
So I’m confused as to what’s causing the additional 300Mb or so of ‘bloat’.
You might already be doing this to find which table/index is using the space, but (for convenience) here’s a workflow that shows a list of the biggest ones.
Just set the credential to connect to your local n8n postgres instance with the root uid/pw.
Thanks for that. It helped because it showed that even the last ‘vaccum full;’ on the execution_data table, prior to yout post, didn’t actually reduce the size (confirmed by performing it again which then reduced the size of the whole db to about 250Mb).
250Mb (approx) seems to be the minimum size of the db for both instances of n8n and with my worflows and 12 hour data rentention before pruning takes effect.
I’m now using n8n to do a ‘vaccum full;’ every 24 hours to keep the size low.
I’ve however been developing front code that works with n8n and the DB, so haven’t had the opportunity to do any real world tests or checks, but hope to soon as the workflows will require developing soon.
I’ll keep and eye on it all and update here as soon as I can.