I am currently using a Edit/Set node to rename and “flatten out” some fields deep within a JSON. However, the Set node takes many minutes per run due to the amount of data passed through it.
Is it possible to use a Code node to achieve the same result but faster? I am proficient in automation design but not in coding, so if anyone would be willing to help me design a Code node to do this, not only would it be a great help, but I would learn something in the process and be able to do it for myself in the future.
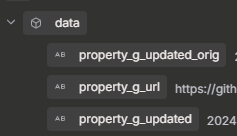
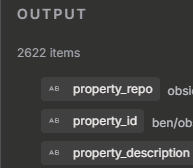
Basically the general idea is this: My JSON contains data that is wrapped under “data”. Screenshot below. What I want to achieve is to extract specific key values out to the top, so that they are accessible by just their key name instead of data.keyname. Does this make sense, am I explaining it correctly?
If I am using an “Extract to File > JSON” node and it outputs like the first screenshot (under a dataobject), how can I extract directly to the flat format in my second screenshot? If it’s possible to avoid needing a Code node at all, that would be even better!
Hey, no worries, I will help you, but can you post your workflow here, so I can get a better idea of how you use the data afterwards? I need this as there may be an even better/cleaner solution.
Just to reiterate in case I didn’t articulate it well the first time, I’m still learning how to explain this need effectively. The Extract JSON node comes from a previous node that reads a local JSON file. The Extract JSON node wraps everything inside data at the top level. I’m using the Set node to “unwrap” them aka flatten them all at the top level.
I’d like to either: 1) Always Extract JSON flattened instead of being wrapped inside data, or if that isn’t technically possible then 2) use a Code node instead of Set node to flatten everything, which I think n8n would process much faster than the Set node (which currently takes minutes, when my JSON has 2600+ records in the array)
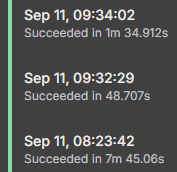
Thanks for the suggestion, I tried your “New Set Node”, and while it was faster, it still took 1min 30sec to process the whole dataset. I’d like this to ideally be as fast as possible, under a minute at least.
I just discovered the Rename Keys node and tried it, and it further sped the process, down to 48sec only. But I still wonder if a Code node could do this even faster?
7m 45s with the original Set node I started with. 1m 34s with New Set Node above. 0m 48s for the Rename Keys node.
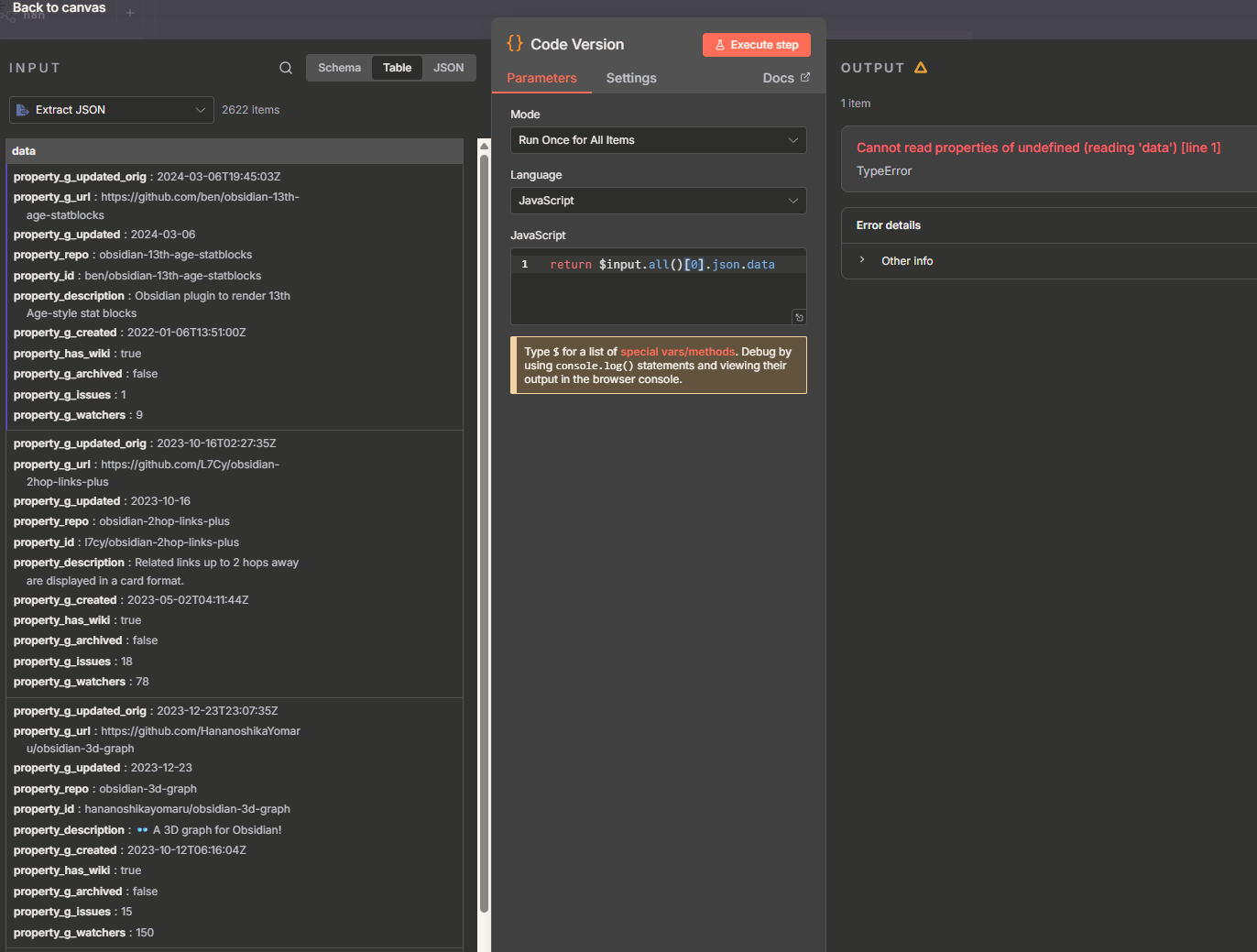
Interested to try the Code node, but it gives me an error in my workflow. I think the included [0] needs to be removed? Here’s a screenshot of what I see. Note, the workflow I shared in this post is just a slice, the screenshot below is with the full dataset.
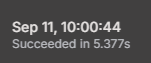
That’s it! That last Code block you shared worked perfectly, and it processed all 2600+ records in about 5 seconds! Amazing, thank you so much. I’ve learned a lot here