This is indeed a tricky one. Are there only two possible emails? Or is there an infinite number of emails?
If there’s only two emails, I’d simply recommend using the IF node to check whether the email field equals [email protected] (in that case all rows for this email can be further processed after the true output of the IF node, and rows for [email protected] fo to the false output).
If there can be more emails, the scenario would be a bit harder to implement in n8n. The only approach I can imagine would be to transform your input data into a single item for each email address using customized code through the Function node. Then split up the workflow in batches of 1 using the Split In Batches node.
Finally, for each individual email spread out all matching items again, create the spreadsheet, send out the email and loop until all emails are processed.
Ah, this can be quite memory hungry indeed. The Function node is tough on memory, but also the binary files generated inside the loop can become large from the looks of it.
Are you self-hosting n8n? If so, you could try setting the environment variable N8N_DEFAULT_BINARY_DATA_MODE=filesystem on the latest version. This will mean binary data is held on the filesystem rather than in memory (this is still being tested at this stage, so not documented yet) and might already improve the situation for you.
I will try that for sure as i got the self hosted app but also the “desktop” one.
I make small try on desktop before mooving to server
will try this one on server with this setting see what happen.
Else I have an other “idea” in mind is to add something link retrieve the file content > create sql table > insert data > get disctinct email > batch of query for each email (generate file / send email)
Unfortunately this variable won’t have any effect on the n8n desktop version yet. This is because the desktop version is only being built every few weeks based on the available n8n version at that time. Currently, the desktop app uses n8n version 0.153.0 while the latest version available for self-hosting and n8n.cloud is 0.159.1. The binary data handling improvements have started with version 0.156.0.
So if you do have a SQL database available, this road is definitely worth a shot
So i’m on the good way with the SQL process i think
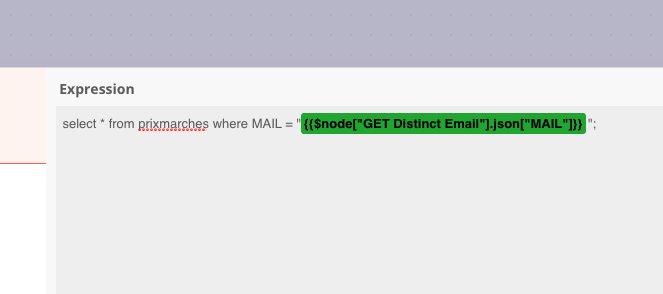
I made the start like Read binary file / import into DB / select distinct MAIL but now i’m stuck in the “batch” mode
i’m not sure how to retrieve the batch value to “fill” my query (and replace the XXXX here by the retrieved emails)
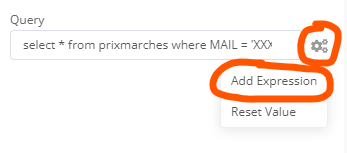
select * from prixmarches where MAIL = ‘XXXXXXX’;
(i try to look at the doc, but didn’t find any sample / expalaination, i might be wrong…)
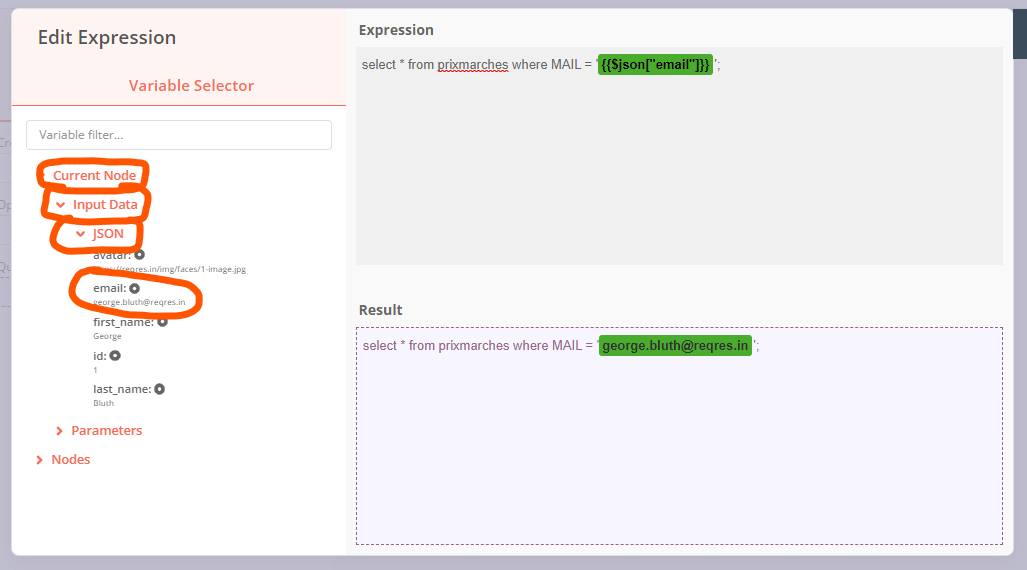
This could be achieved using an expression. To add one, first make sure to run your workflow up until the SplitInBatches1 workflow (this is just to generate some example data making working with expressions easier).
You can then add the actual expression by clicking the cogwheel next to the query field and then Add Expression:
In the expression editor, instead of the XXXXX pick the field you want to use through the browser on the left side (the data from the screenshot is just some dummy data I use, your fields will of course look different):
Also, to save memory you might want to split the workflow part up until the insert and the select part into two separate workflows running after each other.
For the memory part for now with SQL it’s not an issue the whole process (almost green everywhere as you can see)
take about 1 or 2 minutes maximum on my laptop
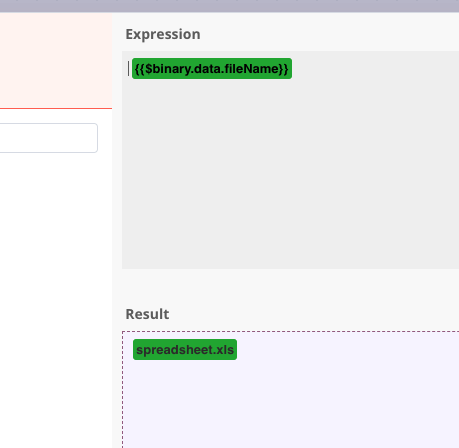
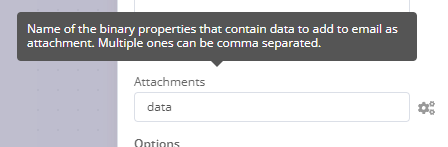
Sounds like we’re getting there. The attachments field wouldn’t require the filename but the name of the binary property. In my example that’d be simply data:
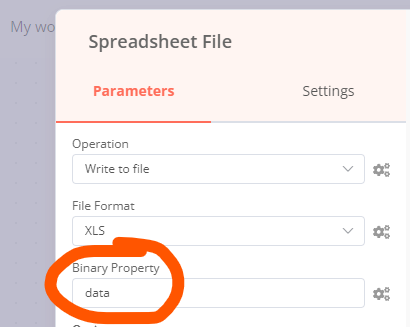
It’s the value you’d set in the previous Spreadsheet File node generating the file:
Just have to fine tune cause right now i got a bunch of email but every time the same content, it’s seem the bach get the same indice (email) in my case and not use the next one.
But i’m almost there !
Edit : I use the wrong indice in my 2nd sql query, with the right indice all goods