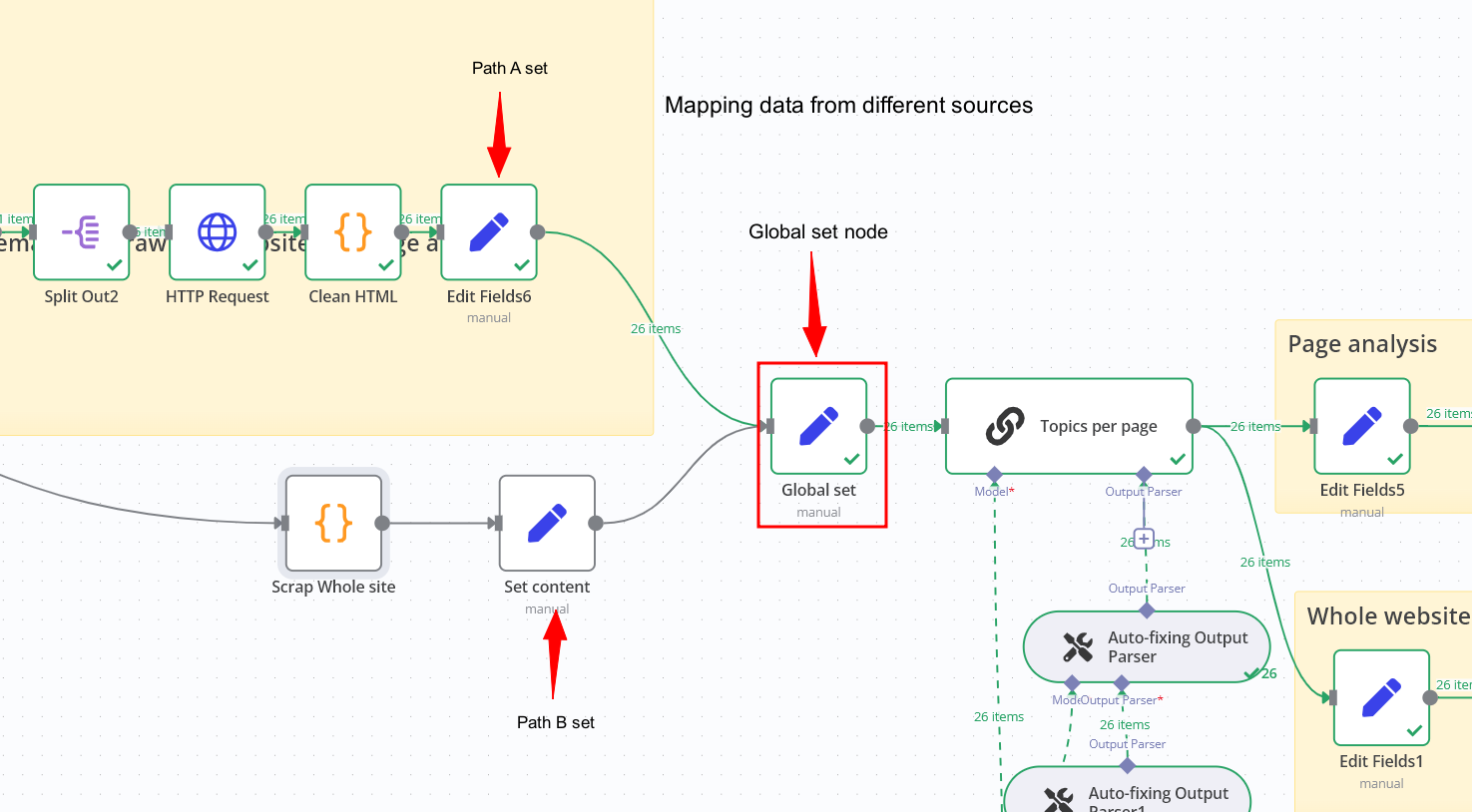
When building workflows that need more scalability or different sources, we might find a case where we have two different data sources that need be processed by the workflow
In this case, most users tend to replicate the same workflow/steps to map out the different paths
This a trick you can use: A Global set node
How does this work
You map each path as it should eg trigger A is a webhook and B is an in app trigger
On the last nodes, standardize the data to have the same fields and field names eg path A and B both need have same fields eg URL, topics etc
Have a new Global set node that can then be mapped to pass all these items
This is the node that we then reference throughout the workflow based on the desired actions
If these datasets need different response formats, have an identifier eg Path = Workflow
The other solution is using || when mapping the fields eg
@Trust For the immediate previous node data, I like it as it is. It much better to have that as it would somehow overside the Pass all items eg in the set node. I dont need the previous as {{nodename.items}} but the easier json.item
The problem with this approach, is the immediately previous node changes frequently in development as your code evolves.
And it’s easy to end up with multiple of the same field name json.item… and then the system doesn’t know how to treat one vs the other and acts unpredictably. All it takes is inserting a node to the left side of the current node, after you set an expression. I’ve found myself in this situation several times in my first several workflows. A better way to approach this, is to allow json.item to be used (for shorthand if you type it) for the immediately proceeding and then change it to full length immediately. If you drag it, just use full length. Being consistent is a much better way. Being consistent, allows you update consistent across the board if a node name changes.
I used to rely on the Merge Node to combine data from Source A and Source B, allowing it to pass whenever either source provided new data. However, after seeing your approach, I’ll be switching to it!
Your method is much clearer and more convenient, making the workflow easier to manage.