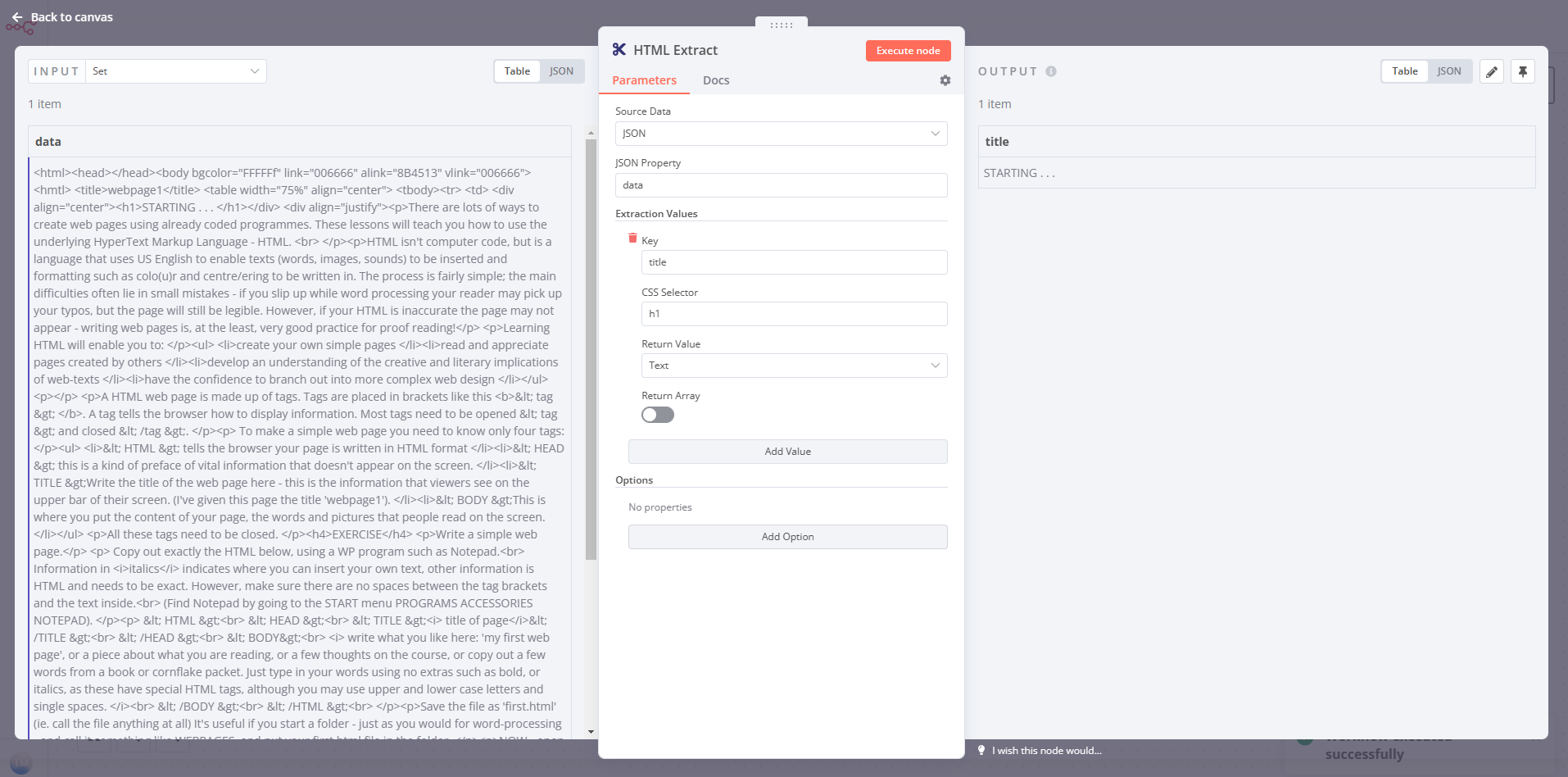
I’m getting data from a webhook, and then want to parse it with the HTML Extract node, but I’m running into errors I’m not finding a way to fix. The data comes in from the webhook fine, but once it goes to the HTML Extract node, these are the errors:
ERRORS
In a popover in the bottom right of the page:
Problem executing workflow
There was a problem executing the workflow:
"Converting circular structure to JSON --> starting at object with constructor 'Object' | property 'parent' -> object with constructor 'Document' | property 'children' -> object with constructor 'Array' --- index 0 closes the circle"
In the HTML Extract node itself:
ERROR: extractionValues.values is not iterable
The workflow:
Here is the data that comes in to the webhook:
[
{
"headers":
{
"host":
"n8n.mydomain.live",
"user-agent":
"axios/1.2.1",
"content-length":
"4405",
"accept":
"application/json, text/plain, */*",
"accept-encoding":
"gzip, compress, deflate, br",
"content-type":
"application/json",
"x-forwarded-for":
"85.203.36.52",
"x-forwarded-host":
"n8n.mydomain.live",
"x-forwarded-port":
"443",
"x-forwarded-proto":
"https",
"x-forwarded-server":
"8bd0a4ed6c1a",
"x-real-ip":
"85.203.36.52"
},
"params":
{
},
"query":
{
},
"body":
{
"html":
"<html><head></head><body bgcolor="FFFFFf" link="006666" alink="8B4513" vlink="006666"><hmtl> <title>webpage1</title> <table width="75%" align="center"> <tbody><tr> <td> <div align="center"><h1>STARTING . . . </h1></div> <div align="justify"><p>There are lots of ways to create web pages using already coded programmes. These lessons will teach you how to use the underlying HyperText Markup Language - HTML. <br> </p><p>HTML isn't computer code, but is a language that uses US English to enable texts (words, images, sounds) to be inserted and formatting such as colo(u)r and centre/ering to be written in. The process is fairly simple; the main difficulties often lie in small mistakes - if you slip up while word processing your reader may pick up your typos, but the page will still be legible. However, if your HTML is inaccurate the page may not appear - writing web pages is, at the least, very good practice for proof reading!</p> <p>Learning HTML will enable you to: </p><ul> <li>create your own simple pages </li><li>read and appreciate pages created by others </li><li>develop an understanding of the creative and literary implications of web-texts </li><li>have the confidence to branch out into more complex web design </li></ul><p></p> <p>A HTML web page is made up of tags. Tags are placed in brackets like this <b>< tag > </b>. A tag tells the browser how to display information. Most tags need to be opened < tag > and closed < /tag >. </p><p> To make a simple web page you need to know only four tags: </p><ul> <li>< HTML > tells the browser your page is written in HTML format </li><li>< HEAD > this is a kind of preface of vital information that doesn't appear on the screen. </li><li>< TITLE >Write the title of the web page here - this is the information that viewers see on the upper bar of their screen. (I've given this page the title 'webpage1'). </li><li>< BODY >This is where you put the content of your page, the words and pictures that people read on the screen. </li></ul> <p>All these tags need to be closed. </p><h4>EXERCISE</h4> <p>Write a simple web page.</p> <p> Copy out exactly the HTML below, using a WP program such as Notepad.<br> Information in <i>italics</i> indicates where you can insert your own text, other information is HTML and needs to be exact. However, make sure there are no spaces between the tag brackets and the text inside.<br> (Find Notepad by going to the START menu\ PROGRAMS\ ACCESSORIES\ NOTEPAD). </p><p> < HTML ><br> < HEAD ><br> < TITLE ><i> title of page</i>< /TITLE ><br> < /HEAD ><br> < BODY><br> <i> write what you like here: 'my first web page', or a piece about what you are reading, or a few thoughts on the course, or copy out a few words from a book or cornflake packet. Just type in your words using no extras such as bold, or italics, as these have special HTML tags, although you may use upper and lower case letters and single spaces. </i><br> < /BODY ><br> < /HTML ><br> </p><p>Save the file as 'first.html' (ie. call the file anything at all) It's useful if you start a folder - just as you would for word-processing - and call it something like WEBPAGES, and put your first.html file in the folder. </p><p>NOW - open your browser.<br> On Netscape the process is: <br> Top menu; FILE\ OPEN PAGE\ CHOOSE FILE<br> Click on your WEBPAGES folder\ FIRST file<br> Click 'open' and your page should appear. </p><p>On Internet Explorer: <br> Top menu; FILE\ OPEN\ BROWSE <br> Click on your WEBPAGES folder\ FIRST file<br> Click 'open' and your page should appear.<br> </p><p>If the page doesn't open, go back over your notepad typing and make sure that all the HTML tags are correct. Check there are no spaces between tags and internal text; check that all tags are closed; check that you haven't written < HTLM > or < BDDY >. Your page will work eventually. </p><p> Make another page. Call it somethingdifferent.html and place it in the same WEBPAGES folder as detailed above. </p><p>start formatting in <a href="webpage2.html">lesson two</a> <br><a href="col3.html">back to wws index</a> </p> <p></p> </div> </td> </tr> </tbody></table> </hmtl></body></html>"
}
}
]
I have tried:
-
In the HTML Extract node, I entered {{ $json[“body”] }} into the “JSON Property” field, but that returns, “ERROR: No property named “[object Object]” exists!”
-
In the HTML Extract node, I entered {{ $json[“body”][“html”] }} into the “JSON Property” field, but that returns, "ERROR: No property named “input::placeholder { user-select: none; -webkit-user-select: none; } iframe { color-scheme: auto; }”… etc etc
-
In the HTML Extract node, I entered body.html into the “JSON Property” field, but that returns, “ERROR: No property named “body.html” exists!”
-
Adding an “Item Lists —> Split Out Items” before the HTML Extract node, with “body” under “Fields to Split Out,” and that returns “ERROR: The provided field ‘body’ is not an array”
-
Adding an “Item Lists —> Split Out Items” before the HTML Extract node, with “body.html” under “Fields to Split Out,” and that returns “ERROR: The provided field ‘body.html’ is not an array”
-
Adding an “Item Lists —> Split Out Items” before the HTML Extract node, with {{ $json[“body”] }} under “Fields to Split Out,” and that returns “ERROR: fieldToSplitOut.includes is not a function”
-
Adding an “Item Lists —> Split Out Items” before the HTML Extract node, with {{ $json[“body”][“html”] }} under “Fields to Split Out,” and that returns “ERROR: Couldn’t find the field 'input::placeholder { user-select: none; -webkit-user-select: none; } iframe { color-scheme: auto; }” … etc etc
I’m out of ideas! Any assistance would be deeply appreciated.