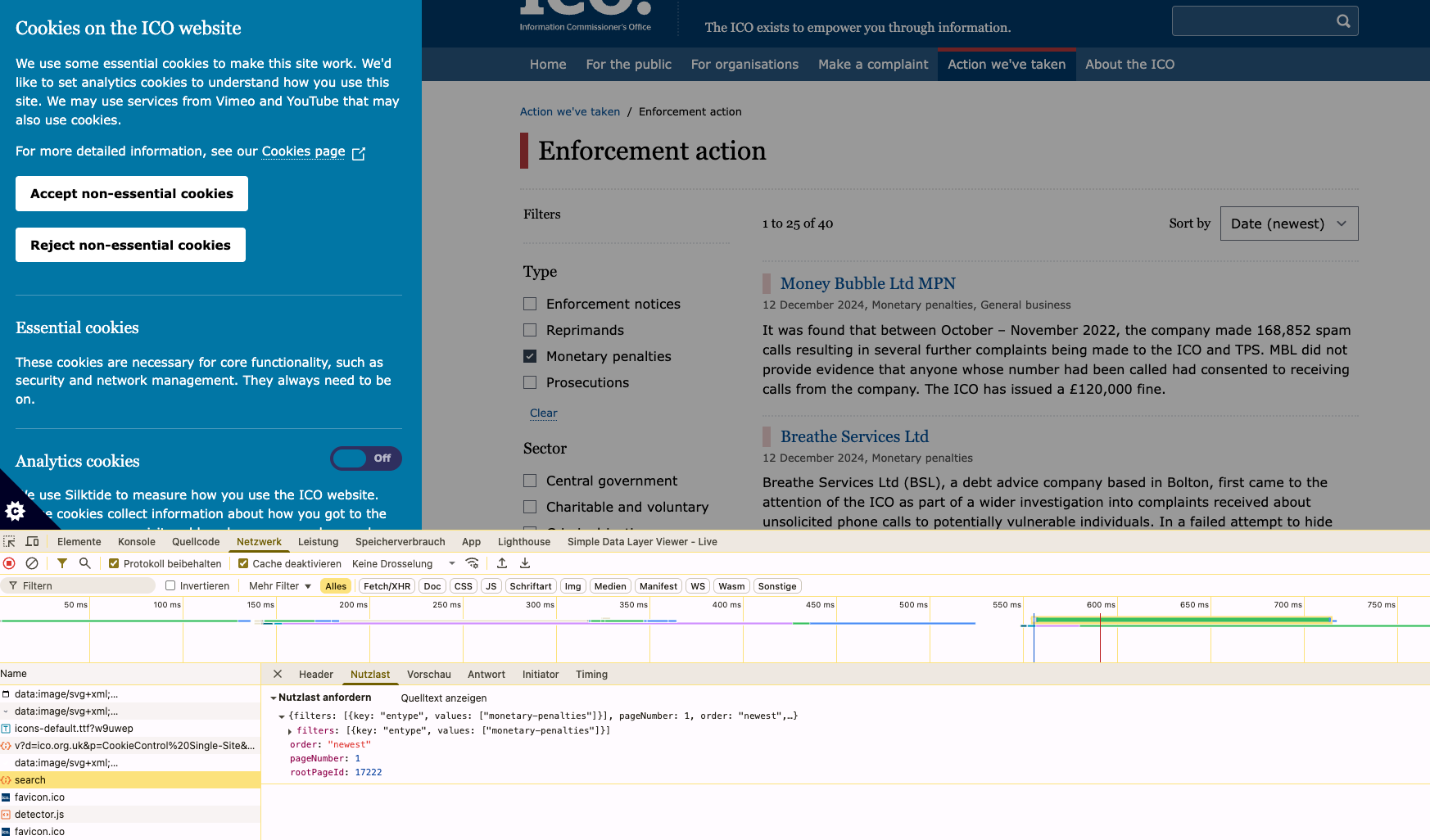
I can make the request to the website using HTTP Request; and I can use HTTP Extract to take data out. The issue is the website is dynamic. After making the HTTP Request, it doesn’t download the website, after all content has been loaded. Instead, it only loads the template without dynamic content.
The content is retrieved using an API call with JavaScript. You can see this through the Developer Tools in browsers like Chrome. This request can be copied (using Copy as cURL) and then added as an HTTP Request Node in your workflow.
After that, just perform a Split Out, and you’re done.
However, here’s a friendly reminder: Using the likely undocumented API too excessively can quickly result in your IP address being blocked.