All, I know how silly these questions look, but I have been looking for answers intensely here, google and youtube - and i have been hitting a wall for over 2 hours. Sorry:
I am doing simple http requests to websites. Nothing special just http request to what i believe are static websites, yet i receive these two errors:
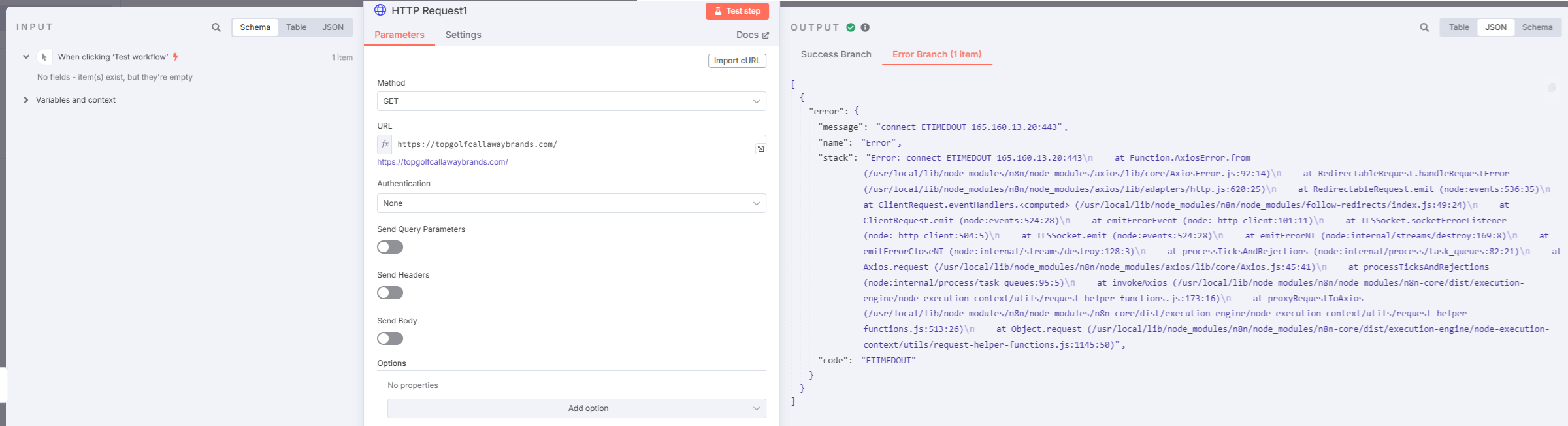
Connect time out error when i go here https://topgolfcallawaybrands.com/ → again just a normal static website. I have been trying to turn on ‘retry on fail’, but that didnt work
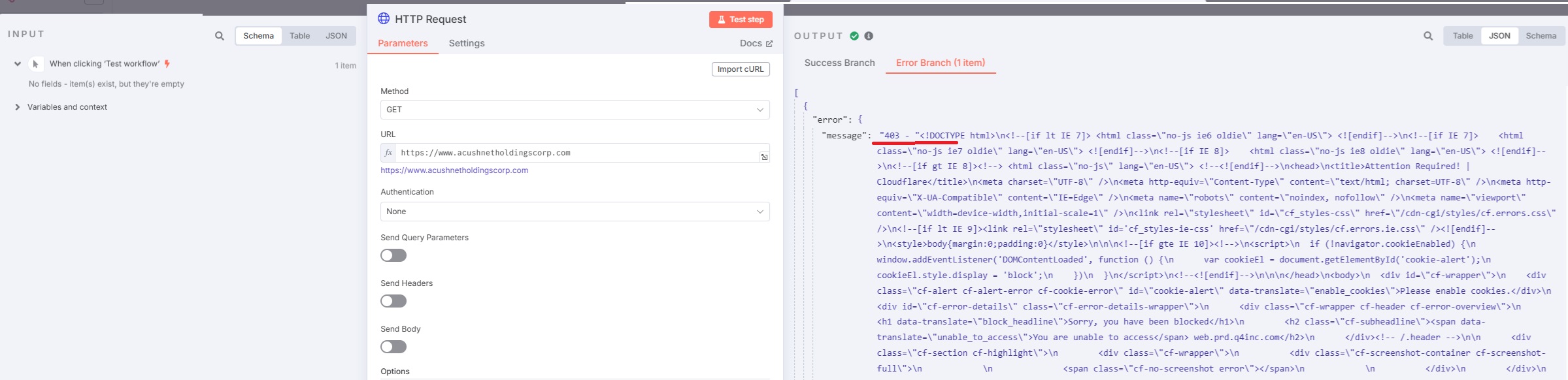
A 403 error indicates that the server is refusing to fulfill the request. Even though the website appears to be publicly accessible, some servers implement security measures to block automated requests that don’t resemble typical browser behavior.
An ETIMEDOUT error suggests that the request is taking too long to get a response from the server, leading to a timeout.
If your goal is to scrape website content, you might need to consider alternative approaches:
Use a Browser Automation Tool: Tools like Puppeteer or Playwright can simulate real user interactions more effectively, handling JavaScript rendering and other complexities that standard HTTP requests might not manage well.
Third-Party Scraping Services: Services like ScrapeNinja or ScrapeOps offer advanced scraping capabilities, including proxy rotation and TLS fingerprinting, which can help bypass common anti-bot measures.
Legal Considerations: Always ensure that you’re complying with the website’s terms of service and robots.txt file when scraping data.