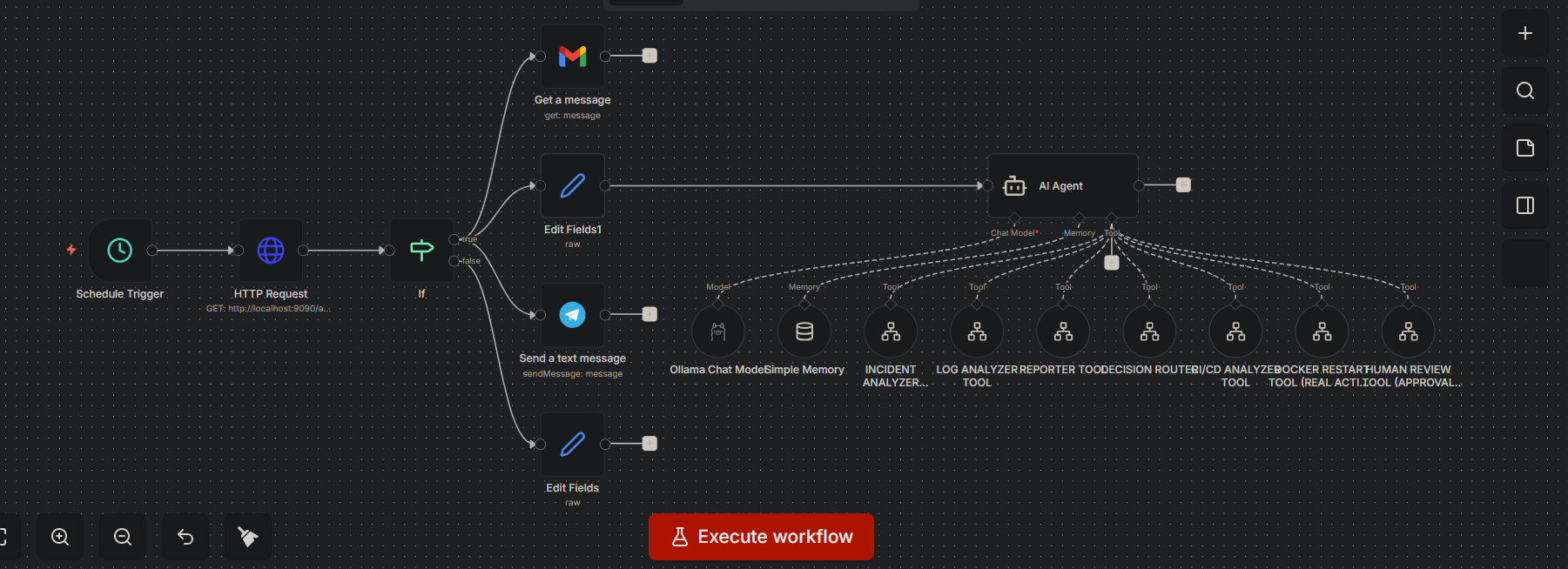
I built a fully automated AI DevOps system using n8n — and turned it into a multi-agent incident response platform.
This project isn’t just automation… it’s a full AI-driven DevOps control plane.
It monitors systems, detects failures, analyzes logs, evaluates CI/CD pipelines, and responds like a real Site Reliability Engineer.
![]() What it does:
What it does:
Real-time system monitoring (every minute)
Detects outages, CPU spikes, and service failures
AI-based incident analysis and severity classification
CI/CD pipeline failure detection and debugging
Log analysis for root cause detection
Structured incident reporting
Instant alerts via Telegram
Human approval flow for critical actions
Optional Docker restart for auto-healing (with safety gates)
![]() Multi-Agent Architecture:
Multi-Agent Architecture:
I designed the system using modular AI agents:
Incident Analyzer Agent
Log Intelligence Agent
CI/CD Analyzer Agent
Decision Routing Agent
Reporting Agent
Human Approval Agent
Auto-Healing Action Agent
Each agent runs as an independent workflow and connects like microservices.
![]() Tech Stack:
Tech Stack:
N8N (orchestration layer)
Docker, Inc(automation + recovery actions)
AI models (Ollama / LLMs)
Monitoring + alerting logic
Telegram for real-time incident delivery
![]() Why this matters:
Why this matters:
This is the direction DevOps is moving toward:
From manual monitoring → automation → AI-driven self-healing infrastructure.
I didn’t just build workflows — I built a 24/7 AI DevOps engineer system that can observe, reason, and act.
![]() Next step: scaling this into a SaaS platform for AI-powered DevOps automation and incident response.
Next step: scaling this into a SaaS platform for AI-powered DevOps automation and incident response.
One of my next projects will be an Amazon Web Services (AWS) cost explorer and manager
If you’re building in DevOps, AI, or automation — this is the future.
Let’s connect.