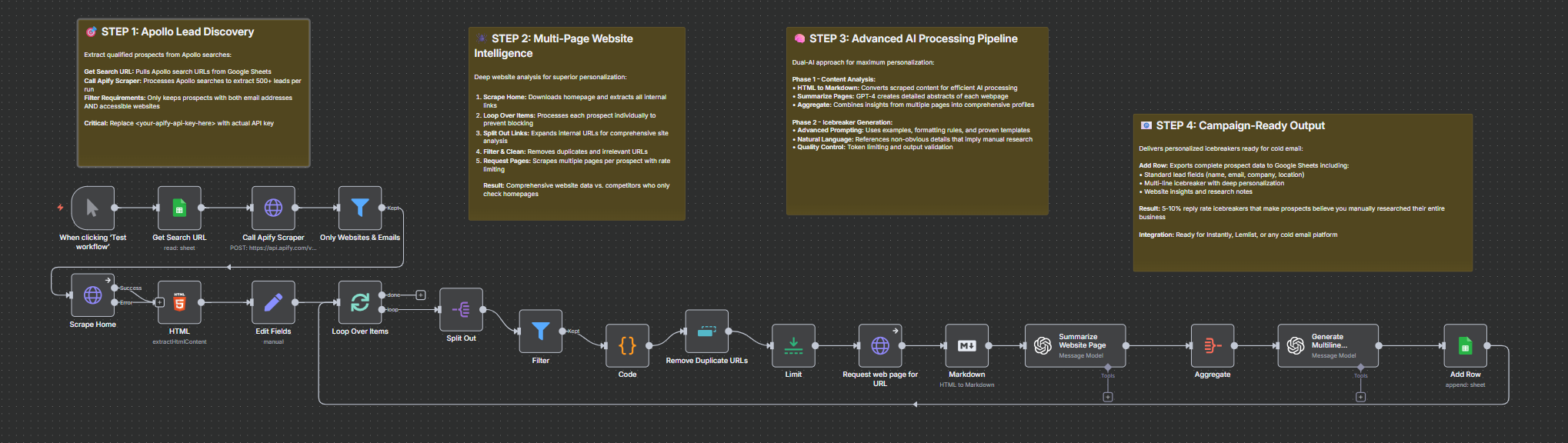
Speed Optimization Help Needed: Apify → Web Scraping → GPT-5 Personalization Workflow
Hey guys, here’s a great, working workflow that creates personalized cold emails I’d love to put into Instantly.ai for outreach. Unfortunately, it’s way too slow — it currently takes about 3 minutes per lead — so uploading 1000 leads just isn’t feasible.
What It Does
It generates hyper-personalized cold email icebreakers (and does a great job creating those):
-
Pulls leads from Apollo with Apify
-
Scrapes multiple pages from each website
-
Uses GPT-5 mini and GPT-5 for every lead (summarization + icebreaker generation)
-
Outputs to Google Sheets
Results are great, but it’s painfully slow.
The Problem
-
Current: ~3 minutes per lead
-
At scale: 1000 leads = 50 hours

-
Bottlenecks: sequential processing, 2x GPT calls per lead (GPT-5 mini + GPT-5). The workflow spends too much time on the two GPT nodes. Switching to smaller GPT models didn’t help much. Ideally, it should handle many leads at the same time.
Current Architecture
-
Apollo/Apify → filter leads with websites
-
Loop through each lead individually
-
Scrape homepage + 3 internal pages (for personalization in case the homepage doesn’t contain much info)
-
GPT-5 mini summarizes each page
-
GPT-5 generates icebreaker from the summaries
-
Write to Google Sheets
How do you handle batch processing with AI nodes, and how would I need to set up parallel processing for this? The sequential loop is killing performance.
Looking for any ideas to get this from 3 minutes to under 30 seconds per lead.
I used Nick Saraev’s template as the base for this automation but tweaked it for my use case. Maybe someone else has also used his template and made it work? I’d really appreciate your help! ![]()
Happy to share the JSON if anyone wants to take a look.