I have an IF node and want to carry out some extra actions if the condition is FALSE.
Aside from the extra actions, I want both TRUE and FALSE branches to continue after that point - like this:
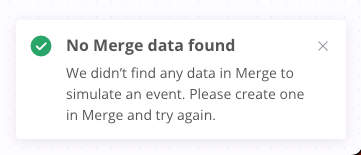
However, when I try to run the Merge node, it complains:
No Merge data found
We didn’t find any data in Merge to
simulate an event. Please create one
in Merge and try again.
I understand from reading other threads that Merge will wait for both branches to complete - but since there is an IF node, one branch will always be empty.
I’m really trying to do something like this pseudo code:
// actions before
if (foundSheet) {
// do nothing
} else {
cloneSheet();
renameSheet();
}
// actions after
I’m sorry if I’m missing an obvious point here - I did search for a long time both the docs and the community but couldn’t work it out.
What am I missing? How do I replicate this kind of conditional structure in n8n?
Somehow, when I test this, it uses test data from a previous run of the FALSE branch, but that causes later code to fail since it relies on an earlier node that is no longer present in the stunted FALSE branch.
Is there any way to stop Merge from waiting for both inputs?
The first “If” actually is set up to let everything through on the “True” route. That route goes to the merge.
Then I have a second set, also from the “True” route, that goes to a second “If” w/ “Always output data” on, so the workflow doesn’t stop there if nothing meets the criteria. The second “If” filters for the thing I actually want to pull out - sometimes all 5 items are “True” on the second “If,” sometimes only 1, whatever. Then those that meet the second “If” criteria get their changes in the “Set” (with “Always Output Data” on as well), and that “Set” moves on to be the second input in the Merge. Now the Merge has 2 inputs, and it’s happy. It’s set to “Enrich Input 1” so that the changes from the bottom route are added/edited on to the unchanged top route.
I’m new to n8n, so perhaps there’s a better way, but that’s how I worked it out.
I don’t see how I can use the “Always Output Data” route, since this will mean that the FALSE branch from my first example is executed even when the condition is FALSE. This would fail since it attempts to create the missing sheet (what the condition was for) - which fails since it is already there.
Does that makes sense, or did I misunderstand your suggestion?
The only way I can see to resolve this just now is to create a sub-workflow - but that seems a lot of extra work for the 3 conditional nodes.
You don’t have to have a TRUE and a FALSE route from a IF.
So you have a 1st IF that is always TRUE, to get the data to pass through to the MERGE. Nothing happens on that route, it’s just to move data through. In my case, it’s that there is a “post_id” in my data. Connect the first IF to the 1st MERGE.
Then you have a second IF that does the actual filtering. So, IF sheet exists, TRUE, and the TRUE route goes no where. IF Sheet does not exist, FALSE, and the FALSE route goes and does what you want, and meets up with the Merge. Set this second IF to always output data, and if nothing passes through the IF filter, it’ll output an empty result to the MERGE so that the MERGE can continue.
Now you have 2 inputs to the MERGE, and it’ll work. How you’ll merge it depends on what you want output - Keep Matches, Keep Everything, etc.
All of your data goes through the first IF. So your 1st IF statement needs to be something that is true for everything that will pass through it. I don’t know what data you have that’s going to a sheet, but something like, “IF [data] exists,” so that everything passes through it. You don’t care yet if the correct sheet exists for the data to go into. It ALL passes through. This IF exists just to put something into Merge 1, so Merge input 1 is happy, and then also bring everything to the second IF, which does the actual work. See how there is no “False” output from IF1? That’s because it’s just used just to pass data through to the MERGE and the 2nd IF.
Then you use the second IF to actually filter for and do the thing you want - IF FALSE, make the Sheet, and pass that data to the merge. Merge input 2 is happy because it gets a response. The TRUE line does nothing, because IF SHEET EXISTS you don’t need it to do anything.
If there is nothing that passes through the 2nd IF FALSE, you still have the FALSE line connected to the MERGE, and “Always Output Data” on. The MERGE will get 2 inputs (one from the 1st IF TRUE line, and one from the 2nd IF FALSE line) and will continue, because it gets a blank output from the 2nd IF FALSE line.
Another way to think about it is that IF1 handles the TRUE and IF2 handles the FALSE.
If you set the MERGE to “Keep Matches” you won’t get a result if there is an empty result from the second input.
But if you set the MERGE to “Keep Everything” or “Enrich Input 1” or you’ll have all your data from Merge input 1, coupled with any data (if it exists) from Merge input 2, and then it’ll work.
I just don’t understand why this isn’t an issue for everyone with conditional logic. It seems like a FI node is necessary that ignores one of the branches depending on the state of the IF.
This still isn’t set up like the example I gave. The way I showed, with 2 outputs from “True” in the first IF, and nothing coming out of the “False” in the 1st IF, is what I read elsewhere in the forum, and what worked for me.
When you select “Merge by Fields” you can find the options to “Enrich Input 1 (left join)” “Enrich Input 2 (right join)” etc. Those are critical to making this work, see the settings in the mockups I posted.
I did see that, and I’m sorry - I just don’t understand.
Why do you have an IF that is true for everything? What does that add?
When the sheet exists in your example, won’t the Merge receive no data for Input2 and therefore fail as before?
And where can you set ‘Merge by Fields’ - which node is that? The Merge Node?