After inserting a document into the memory store, If I search for it afterwards I get no result thus the workflow doesn’t continue. It’s as if the store is empty. Using the same key. I tried looking in the docs, but they are a bit lacking. Also, is there a way to clear a particular store key after using it without inserting more documents to save memory?
What is the error message (if any)?
No error, it just doesn’t work nor I can find any debug information.
Please share your workflow
I can’t really share the whole workflow, as I’m using confidential docs. However, it happens with whatever doc I send.
It seems like there’s an issue with the memory store not retrieving documents after insertion using the same key. To troubleshoot, ensure the document is successfully inserted and that the search functionality is querying the store correctly. Additionally, check for potential concurrency issues and implement logging to capture any errors. Regarding clearing a store key without inserting more documents, it depends on the memory store’s capabilities; refer to its documentation for guidance on key expiration or deletion.
Maybe I’m a bit paranoid, but that answer souns like chatgpt
So:
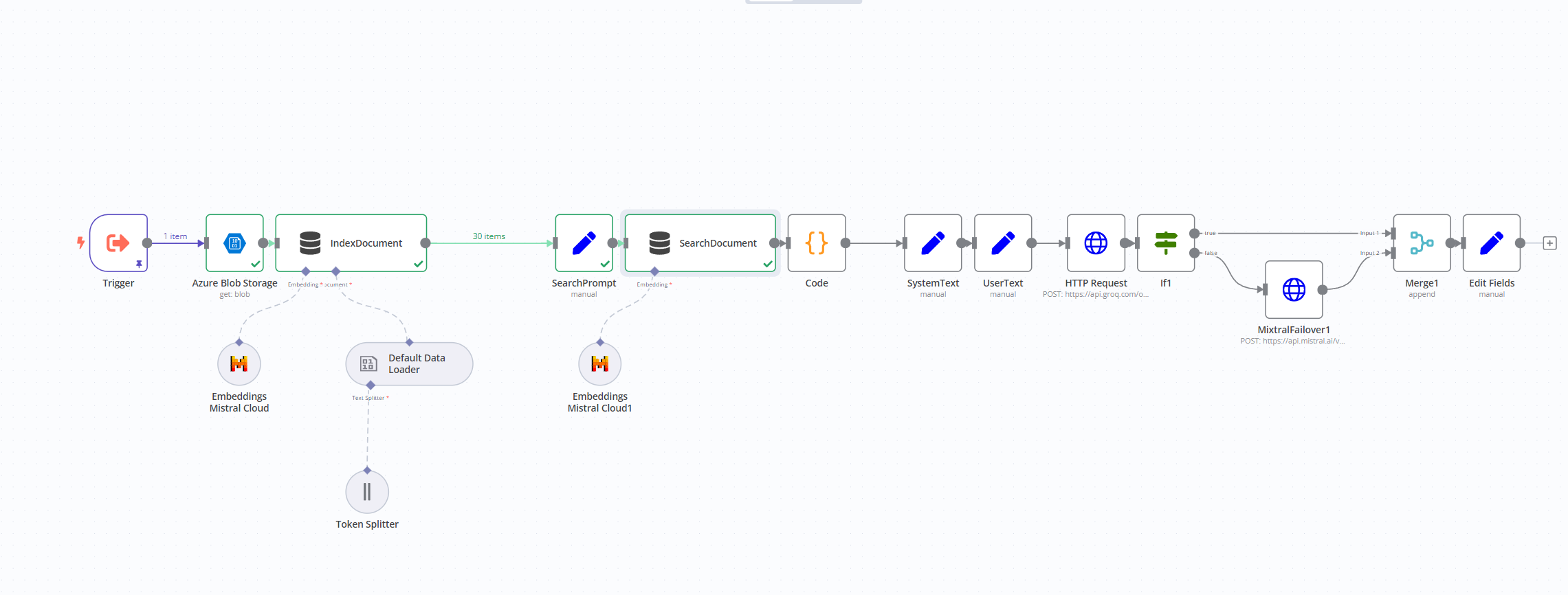
How can I ensure it is inserted? The node returns 30 inserted chunks. You can see it in the image (But chat gpt can’t read images xD)
How can I implement logging in an out of the box store that I didn’t develop?
If, after reading the documentation as I said, how can I refer to it for clearing the store key?
I think I found something. The Mistral Embeddings subnode seems to throw this error:
Request failed: HTTP error! status: 400 Response:
{"object":"error","message":"Too many tokens in batch. Max is 16384 got 71775","type":"invalid_request_error","param":null,"code":null}
But I’m confused because I’m using chunking, the batch size of the subnode is 1 and it is set to split the pdf in pages. So I’m not sure what’s going on here and why the parent node says everything is good without the embeddings. This looks like a bug now
@Jon Sorry for tagging you, but I think this issue went undernotice and is prenventing us from further usage of the AI stuff (I’m in love, and also implemented a Groq ChatModel that maybe your are interested in adding).
Another issue I’m facing is that If aI run the workflow twice, it seems that the memory story saved the previous run info, but within the same workflow it doesn’t find nothing in the vector store.