Describe the problem/error/question
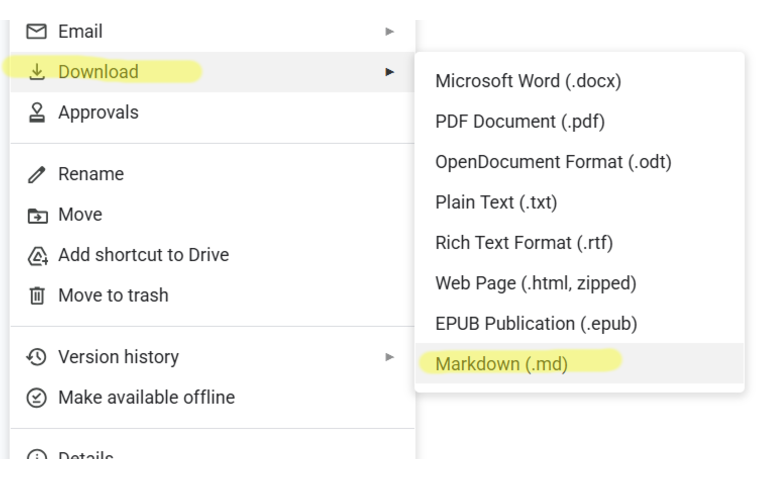
Can’t find an n8n way (node(s)) to get Markdown from a GDoc. Lots of solutions the other way around, and if you “Read” a GDOC, you get “content” as plain text. Maybe it’s an API thing, as it is possible from the GDoc web ui:
What is the error message (if any)?
N/A
Please share your workflow
Looking to find/create something to add to any workflow.
Share the output returned by the last node
If you like, here is what a formatted GDoc looks like when it is “Read” from a GDoc node in n8n, taken from the right “Output” pane:
content
Book Constraints\nCitation Rules Capsule for a 12-Chapter Methodology Book\n1) What must be cited\nCitations are required for any claim that is:\nNumeric: statistics, percentages, counts, rates, benchmarks, “X times more likely,” “average,” “median,” etc.�\nExternally verifiable facts: dates, definitions from standards, legal/regulatory constraints, market-size figures, historical events.�\nResearch claims: “studies show,” “research indicates,” “meta-analyses suggest,” neuroscience/psych claims, behavioral outcomes, etc.�\nQuotations: any direct quote or near-quote from a person, book, paper, or web ...
Information on your n8n setup
- n8n version: latest
- Database (default: SQLite): for settings? Probably sqlite
- n8n EXECUTIONS_PROCESS setting (default: own, main): Workflow Started manually
- Running n8n via (Docker, npm, n8n cloud, desktop app): docker compose on:
- Operating system: ubuntu linux.
1 Like
Hey,
n8n does not have a built-in way to convert a Doc into Markdown directly.
Here’s what n8n provides:
-
A Docs node that can read a document, but it only gives you flat text output. It doesn’t convert the formatting into markdown (headings, lists, bold, etc). That’s just how the integration works right now it pulls text without preserving structure.
-
A Markdown node that converts between Markdown and HTML (Markdown ↔ HTML) only.
So you don’t get a one-step Doc → Markdown in n8n as part of core nodes.
A supported pattern inside n8n
The closest you can do today without external services is:
-
Use the Google Drive node to export the Doc as HTML (download operation supports HTML export).
-
Pass that HTML into the Markdown node set to HTML→Markdown.
That lets you turn the exported HTML into Markdown text you can use elsewhere.
Direct .md conversion or retaining formatting via the Docs node itself isn’t provided by n8n’s core nodes at this time. Let me know if this helps!
True, Anshul.
My solution had to be fine-tunable, it ends up, as things vary…
If you just grab a gdoc, it is in stripped down text, with “/n”s. BUT if you export, like: https://docs.googleapis.com/v1/documents/{{ Some GDoc’s documentId }}
then you get the entire… mess. To clean that all up, I felt better in a Code Node than an all-in-one black box:
const content = $input.all()[0].json.body.content;
let markdown = "";
for (const element of content) {
if (element.paragraph) {
const style = element.paragraph.paragraphStyle.namedStyleType;
let prefix = "";
// 1. Map Headers
if (style === 'HEADING_1' || style === 'TITLE') prefix = "# ";
else if (style === 'HEADING_2' || style === 'SUBTITLE') prefix = "## ";
else if (style === 'HEADING_3') prefix = "### ";
else if (style === 'HEADING_4') prefix = "#### ";
// 2. Handle Lists/Bullets
if (element.paragraph.bullet) {
prefix = "* "; // Standard bullet
}
let paragraphText = "";
for (const part of element.paragraph.elements) {
if (part.textRun) {
let text = part.textRun.content;
const textStyle = part.textRun.textStyle || {};
// 3. Apply Inline Formatting (Bold/Italic)
if (textStyle.bold && text.trim()) {
text = `**${text.trim()}**${text.endsWith(' ') ? ' ' : ''}`;
}
if (textStyle.italic && text.trim()) {
text = `_${text.trim()}_${text.endsWith(' ') ? ' ' : ''}`;
}
paragraphText += text;
}
}
// 4. Assemble the line
if (paragraphText.trim().length > 0) {
// Ensure headers don't get double-bolded if they were bold in GDocs
if (prefix.startsWith('#')) {
paragraphText = paragraphText.replace(/\*\*/g, '');
}
markdown += prefix + paragraphText.trim() + "\n\n";
}
}
}
// Clean up: Straighten quotes and remove GDoc vertical tabs (\u000b)
markdown = markdown
.replace(/\u000b/g, '')
.replace(/[\u201C\u201D]/g, '"')
.replace(/[\u2018\u2019]/g, "'");
return { chapter_markdown: markdown.trim() };
It should handle tables, too, but I haven’t had time to test…
Anyone have improvements for this node?
TIA
pat