Describe the issue/error/question
First off I have to say thank you to the N8N for providing such excellent responses.
I have a simple task which is to go to a website link, emulate filling in 2 input boxes and submitting the data using the button.
After this step the download link will pop up below and I would like to download the PDF from that link.
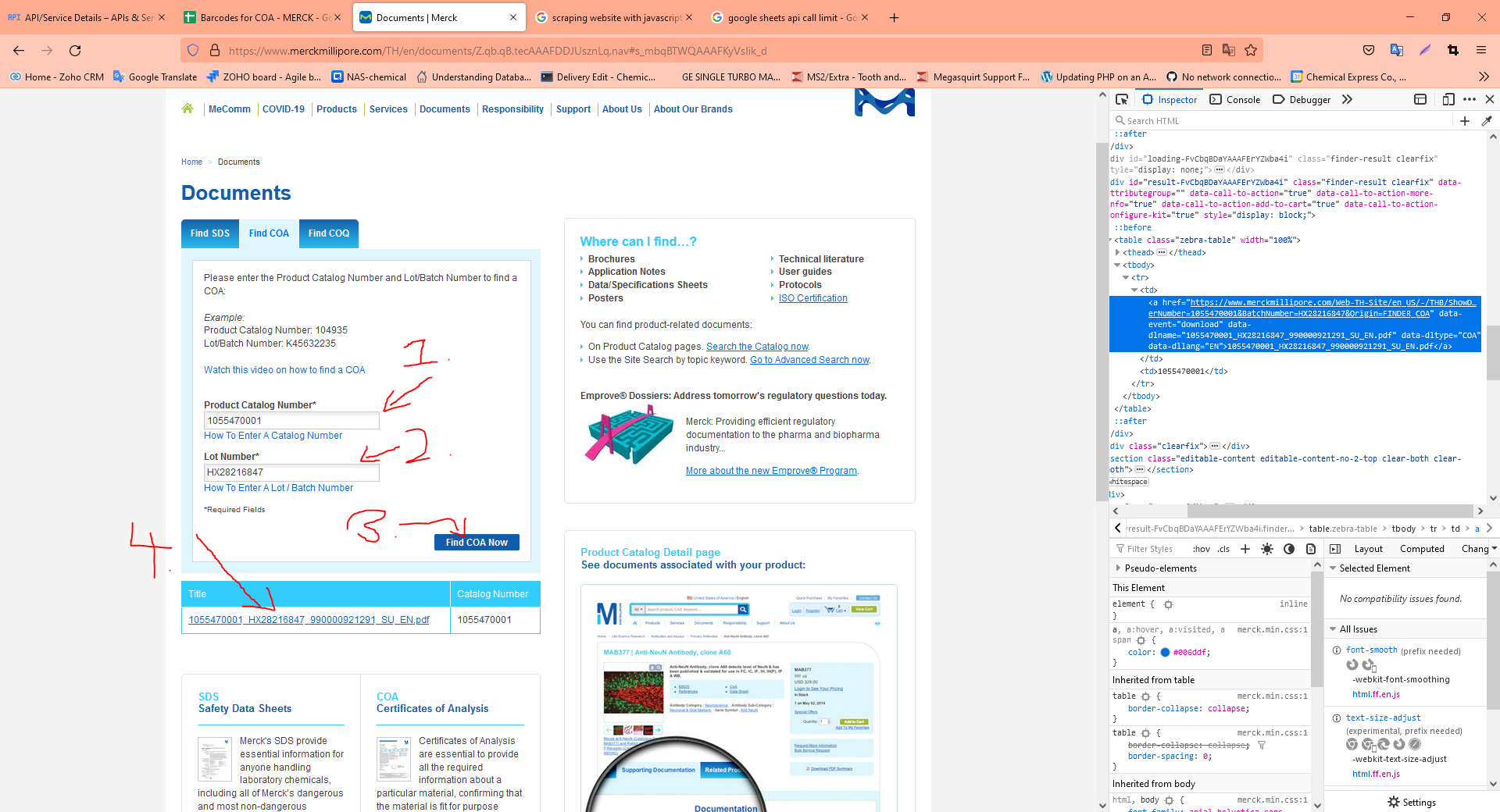
heres a photo of what the website looks like.
- Enter product number
- enter lot number
- click button (submit)
- Download pdf from the link that is found with javascript.
So what would be the way that you choose to interact with the javascript in this site?? everything else like providing the input data and saving the file are very easy thanks to the available core nodes.
The company has refused to provide api access which would make our lives much easier.
What is the error message (if any)?
Please share the workflow
(Select the nodes and use the keyboard shortcuts CMD+C/CTRL+C and CMD+V/CTRL+V to copy and paste the workflow respectively)
Share the output returned by the last node
Information on your n8n setup
Running latest version of N8N in a docker container, I dont mind adding other apps/libraries to the docker container for N8N usage.
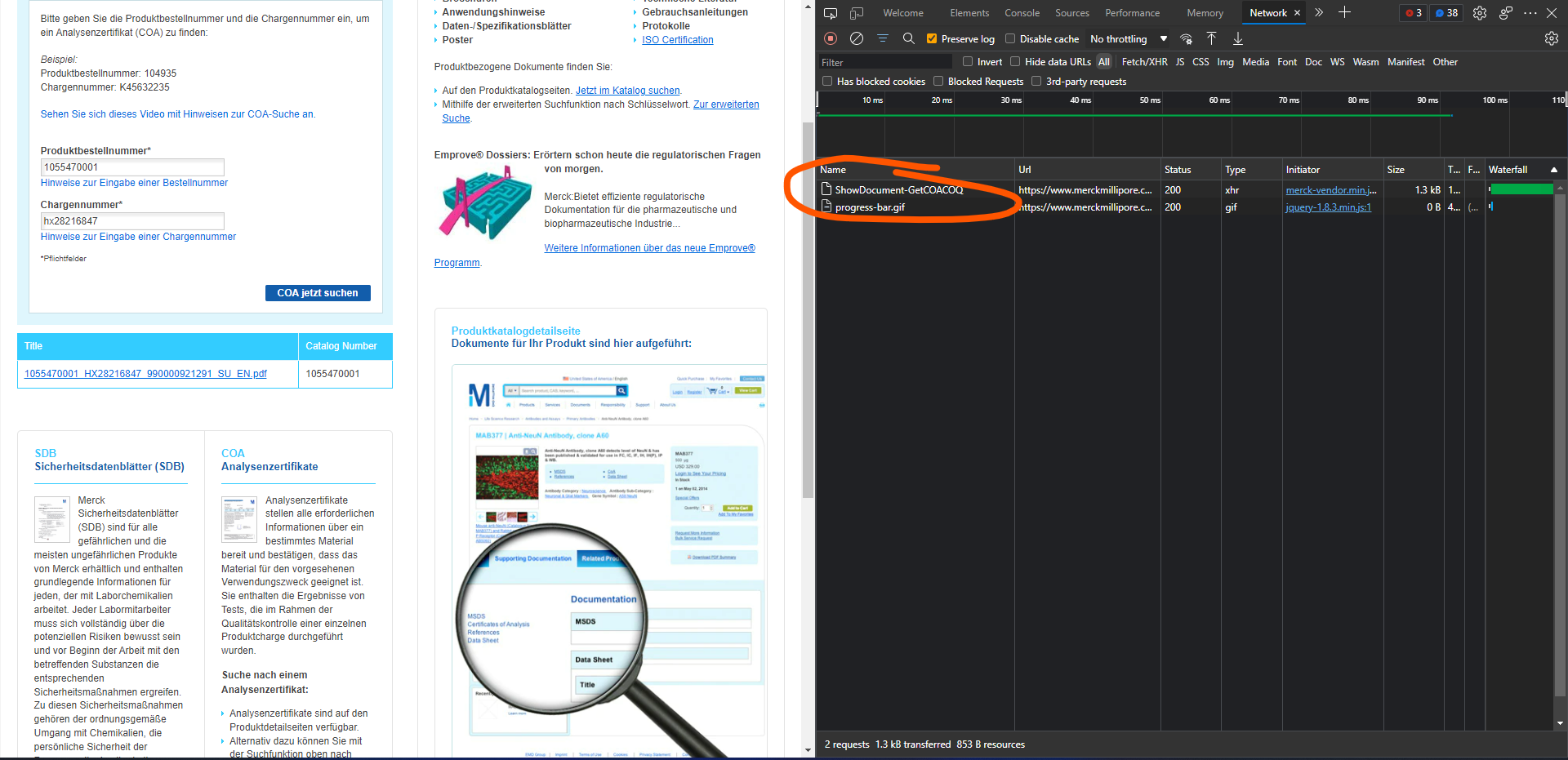
okay so ive just discovered that the link it produces example
https://www.merckmillipore.com/Web-TH-Site/en_US/-/THB/ShowDocument-GetCOACOQ?COAOrderNumber=1055470001&BatchNumber=hx28216847&Origin=FINDER_COA
has both the fields incorporated in a http request, which i can just implant the data and perform a http request to retrieve the file.
However for curiosity sake, how would I do this kind of thing if I wasnt so lucky? avoiding the use of things like UI path etc.
Hi @Josh-Ghazi, my first go to would be the network tab in your browsers’ developer tools, similar to what you have already done. In many cases you’ll be able to see which request exactly is made when a form is submitted and can reproduce it in n8n:
If the website you are trying to scrape does not support this, you might need to look into configuring a headless browser (or rely on external services such as Phantombuster).
1 Like
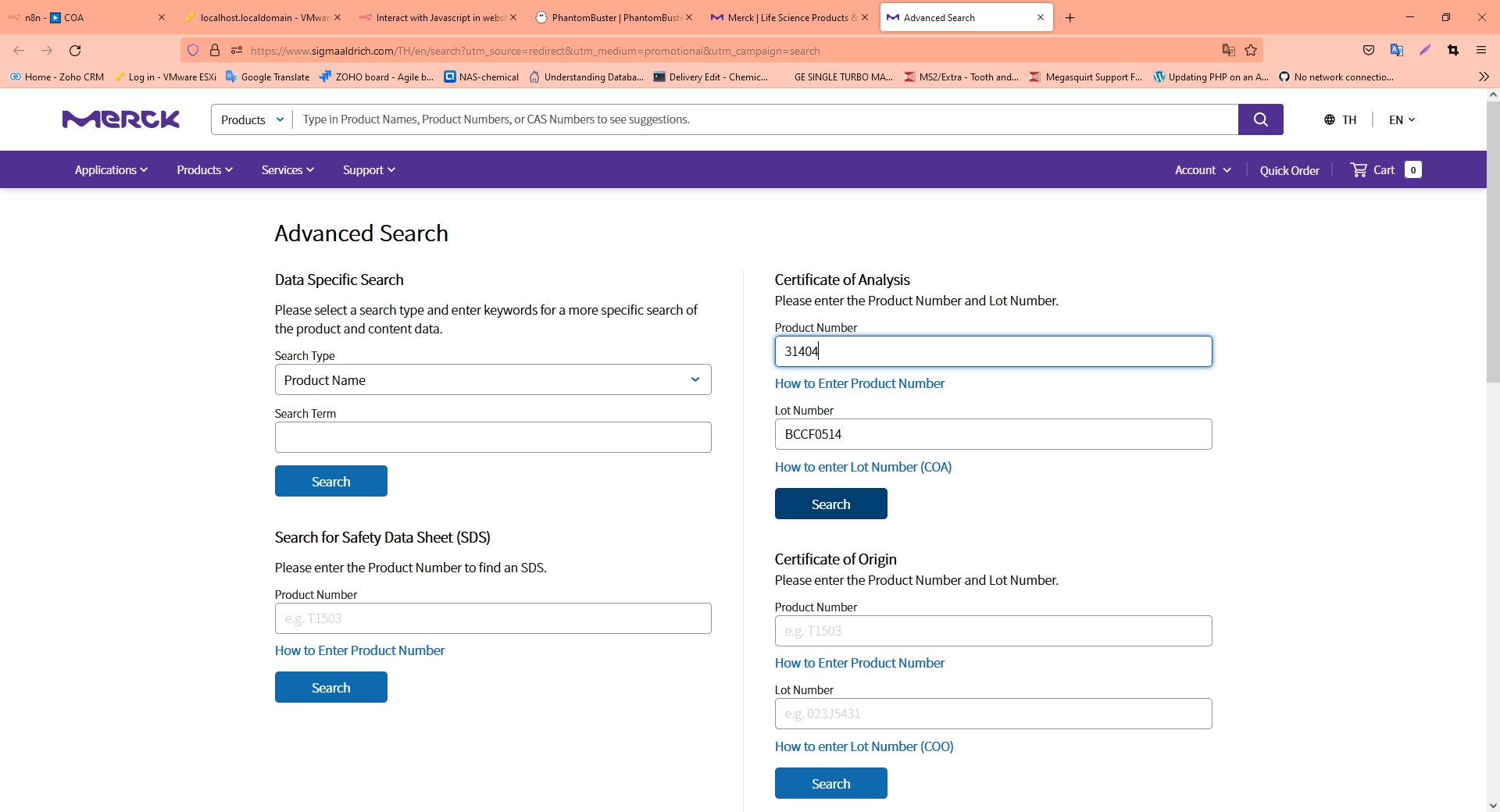
Okay so ive run into what we were talking about, from the looks of it, it appears to be 2 input boxes that are used by a javascript to find a url to a PDF file which is instant download (http file request) Here is the website the download links are all different and dont seem to follow any kind of convention. here a list of numbers in case u wanna try
31404-500G-R POTASSIUM PERMANGANATE R. BCCF0514
822299.0500 PIPERIDINE FOR SYNTHESIS S8157399
C3662-10MG CYCLOSPORIN A 0000127857
EZRMI-13K Rat/Mouse Insulin ELISA K 3872062
HF120MC5PK Hi-Flow Plus 120 077730-02-C
CLS432008-1EA CORNING(R) COOLCELL(R) FT 26218009
S1878-100G SODIUM M-PERIODATE MKCQ7147
491047-5G 2-(BROMOMETHYL)PYRIDINE H MKCJ6763
104984.0500 POTASSIUM HEXACYANOFERRAT A1684984
108087.0500 POTASSIUM SODIUM TARTRATE AM1579487
9310-500GM OmniPur TRIS Hydrochlorid 166797
R4500-25G (-)-RIBOFLAVIN, FROM EREM wxbd4613v
So what is your recommendation to handle this kind of thing
Hi Josh, I’d still check which request is fired when hitting a button. Filling out the two fields from your screenshot appears to result in a GraphQL request which your might be able to emulate using the respective node (but I am not at all familiar with GraphQL so can’t help much with that I am afraid).
If that website really requires JS for rendering purposes you’d need a browser you can programmatically control and this isn’t something n8n offers by default, that’s why I suggested looking at external services doing the job.
1 Like