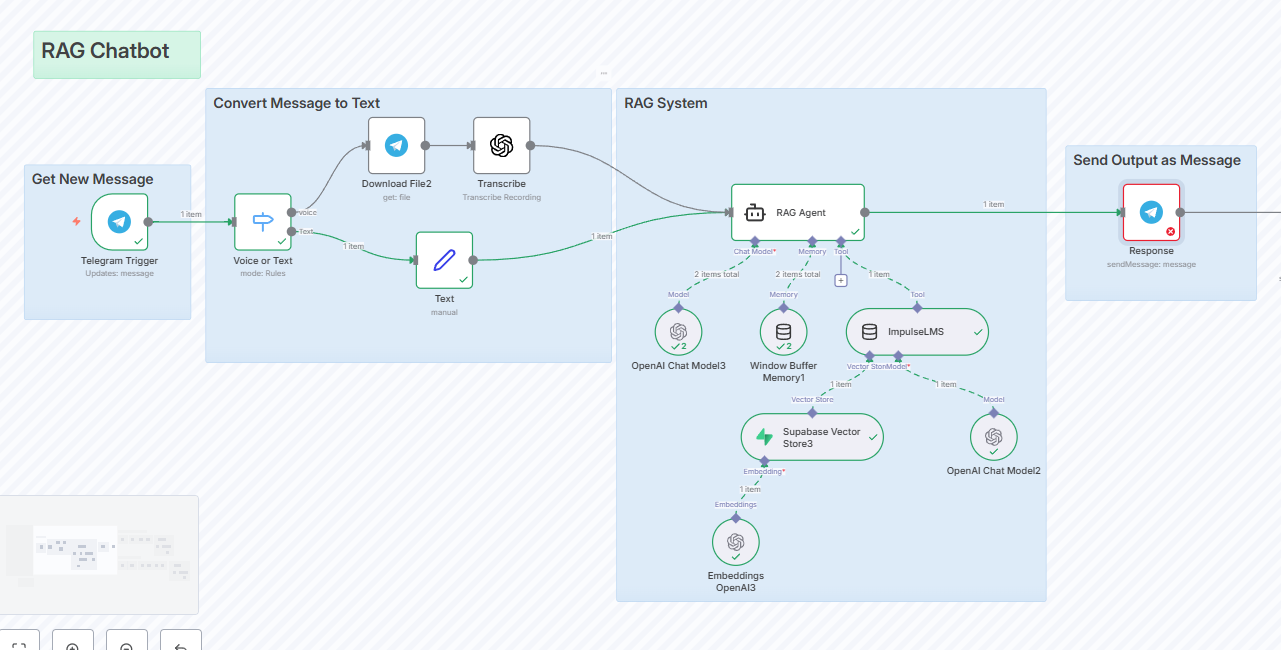
Hello n8n community,
I’m hoping for some guidance on a very strange, intermittent issue I’m facing with a self-hosted setup. The core problem is that the Telegram “Send Message” node fails unpredictably, but only when it receives input from a LangChain RAG Agent node.
My Environment
-
n8n Version: 1.119.2
-
Deployment: Docker Compose on a dedicated Ubuntu Server 24.04.
-
Networking: All traffic is routed through Nginx Proxy Manager (also in Docker).
-
Special Configuration: My OpenAI nodes are configured to route through a custom Nginx proxy on a separate server. This proxy uses a self-signed certificate. I have correctly configured n8n to trust this certificate by mounting it into /opt/custom-certificates with the required hashed symlink. This part works – the RAG agent successfully gets responses from OpenAI.
The Detailed Problem
My workflow is based on the official “Company RAG” template: Telegram Trigger → (process voice/text) → RAG Agent → Telegram Send Message ( Company Knowledge Base Agent (RAG) | n8n workflow template )
The workflow fails about 50% of the time, and the failure always happens at the final “Send Message” node. Sometimes it works perfectly, other times the execution just hangs or errors out at that final step.
Here’s what I’ve discovered through debugging:
-
The problem is specific to the RAG Agent node. If I replace the RAG Agent with a simple Set node that just outputs static text, the Telegram node works flawlessly, 100% of the time.
-
The pattern is repeatable. I’ve built other simple test workflows. As soon as I place any AI Agent node before a Telegram node, the connection becomes unreliable.
This leads me to believe the issue is some kind of incompatibility or race condition between the output of the agent and the input of the Telegram node.
Things I’ve Already Investigated (to save time)
I’ve spent a lot of time debugging potential “red herrings” and want to rule them out:
-
ValidationError: X-Forwarded-For: I do see this error in my logs once when I first load the UI after a container restart. However, I am almost certain this is a separate, cosmetic issue because:
-
It only happens on the first UI request and does not appear when the Telegram node fails.
-
I have already tried setting N8N_TRUSTED_PROXIES, N8N_RATELIMIT_TRUST_PROXY, and even N8N_DISABLE_RATE_LIMIT=true. These variables are correctly passed into the container (verified with docker exec env), but they don’t fix the intermittent Telegram failures.
-
My Configuration
Here is the structure of my docker-compose.yml:
services:
n8n:
image: n8nio/n8n:latest
container_name: n8n
restart: always
ports:
- "0.0.0.0:5678:5678"
env_file: ./.env
environment:
- N8N_HOST=${SUBDOMAIN}.${DOMAIN_NAME}
- WEBHOOK_URL=https://${SUBDOMAIN}.${DOMAIN_NAME}/
# ... other standard variables
volumes:
- n8n_data:/home/node/.n8n
- ./pki:/opt/custom-certificates:ro # For my OpenAI proxy's self-signed cert
# ... other data volumes
networks:
- proxy
# ...
My Core Questions
-
What are the recommended advanced debugging techniques? The standard execution view is not sufficient for these intermittent failures. How can I capture the exact data payload, internal state, or any potential errors being passed between the RAG Agent and the Telegram node precisely at the moment of failure?
-
How can I enable more verbose, internal logging? The standard logs don’t show any specific error from the Telegram node when it fails. Are there specific NODE_DEBUG flags or other n8n-specific logging levels I can enable that would provide a detailed trace of the outbound HTTPS request being made by the Telegram node?
-
What information would be most helpful for you to see? I am fully prepared to provide any necessary diagnostic information to get to the bottom of this. Please let me know what logs, configurations, or specific tests you would like me to run. I can share anything needed (anonymized, of course) to help you help me.
I’m convinced my environment is set up correctly and this is a more nuanced application-level problem. Any help or ideas would be greatly appreciated. Thank you!