Hi! As in the subject, I’d like to ask how I can set the Default Binary Data Mode variable to filesystem so I can handle larger files.
The problem is I’m currently on n8n Cloud and not a self-hosted instance, so I could not apply the typical advice I see in other topics. I’ve also seen another question where the Split in Batches node was advised-- however, I’m not really working with a big dataset, but rather some large binary files.
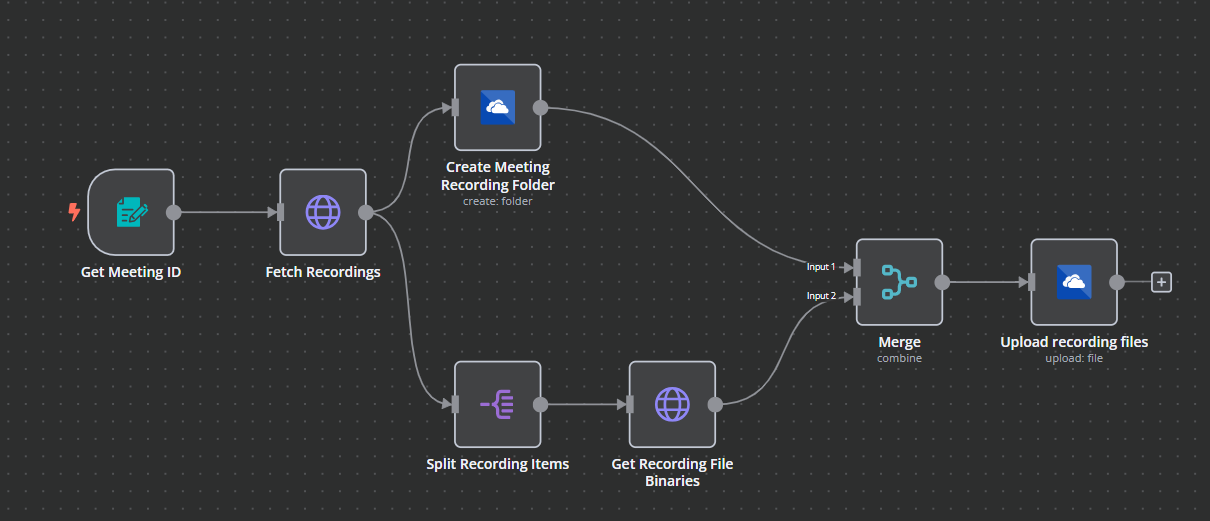
Below is an image of the workflow I’m working on. Would appreciate any advice!
To set the Default Binary Data Mode variable to filesystem in n8n Cloud, there’s no direct option to change this setting as you would in a self-hosted instance. One option is to upgrade to a higher plan which would give you more memory which might solve your issue.
You can also split your workflow into multiple sub-workflows with a parent workflow that fetches the recordings and another child workflow that handles downloading the files and uploading them to cloud storage. You can use the Loop Over Items node in the parent workflow to process small batches of a few urls at a time which should free up resources after each child execution so your n8n instance only needs to manage a few recordings in memory at a time. Here’s a similar post that might help!
If you’re stuck, you can also share your workflow in your post instead of a screenshot:
Tip for sharing your workflow in the forum
Pasting your n8n workflow
Ensure to copy your n8n workflow and paste it in the code block, that is in between the pairs of triple backticks, which also could be achieved by clicking </> (preformatted text) in the editor and pasting in your workflow.
```
<your workflow>
```
Make sure that you’ve removed any sensitive information from your workflow and include dummy data or pinned data as much as you can!
Hi Aya! Thanks for giving me some tips. I’ll try to paste the JSON in here for context.
So to clarify: I already use Split Out here to get the four recording items. However, since this is Zoom, there’s only the one very large file (can reach 400-500 MB since it’s the video) and maybe one or more really small files (text files or transcripts that may be around <10MB or <1MB in some cases).
Can Loop Over Items help me here? Or is upgrading to a plan with larger memory my only recourse? Thanks again!
Hmm, Loop Over Items won’t help to process a file that’s already too large for your memory. I would say upgrading to higher plan with larger memory or using self-hosted would be the better option You can find more information about memory limits for each plan in our docs here: Cloud data management | n8n Docs
* Trial: 320MiB RAM, 10 millicore CPU burstable
* Starter: 320MiB RAM, 10 millicore CPU burstable
* Pro-1 (10k executions): 640MiB RAM, 20 millicore CPU burstable
* Pro-2 (50k executions): 1280MiB RAM, 80 millicore CPU burstable
* Enterprise: 4096MiB RAM, 80 millicore CPU burstable