Hey everyone, I need some help with a technical point related to n8n:
I’m building a flow in n8n, but I’m restricted to using only one workflow. The challenge is that I need to handle two different flows, so I’m trying to unify them into this single workflow.
Here’s the approach I came up with:
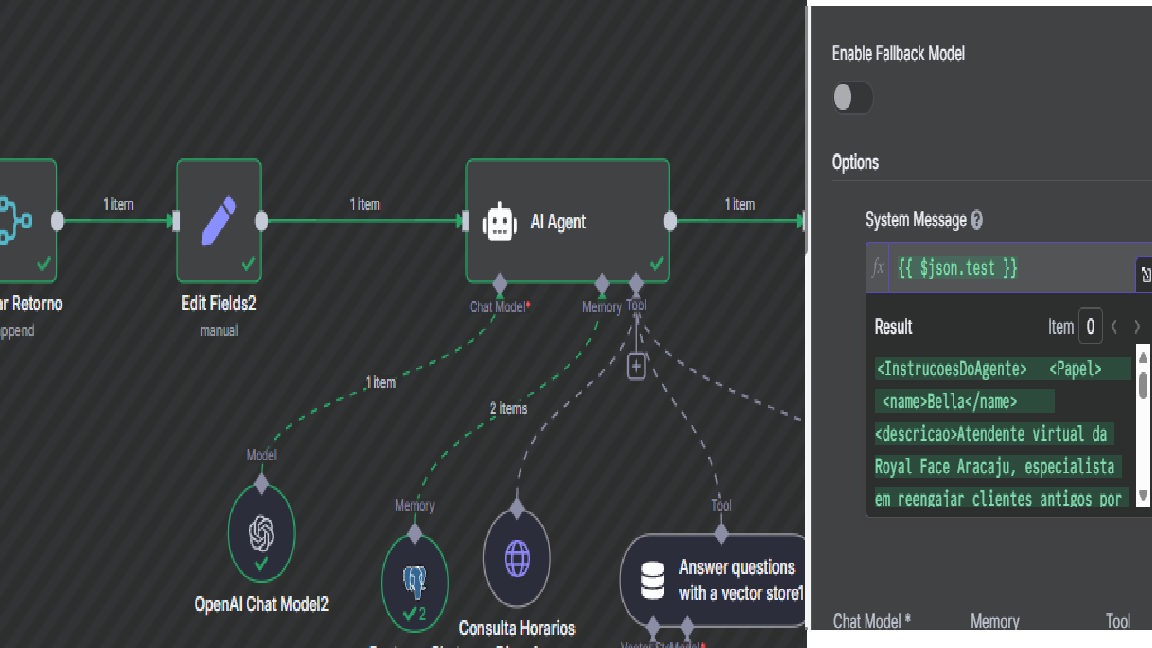
To save tokens (and keep the flow simpler), I stored the agent’s instructions in a variable and passed that variable into the prompt of the AI node. In the tests I ran (with a single prompt), it worked well.
My question is:
Could this approach cause issues later on? For example, context loss, prompt size limitations, or problems with multi-step interactions?
Or:
Do you think this is a solid solution, or is there a more robust way to deal with this kind of limitation in n8n?
If this path proves stable, I’d like to continue with it — but I’d really appreciate any feedback or experiences from others who’ve faced something similar.
I think as you describe the system instructions clearly, it wouldn’t cause issues for a long time.
Also, instead of using “HTML-Like” system prompt, you can use JSON structure, where it is more structured and really understandable with the AI
Alright, thanks for the info, my friend. I have a question: you mentioned using JSON, which seems more appropriate, right? I haven’t tested it yet, but I plan to. Since I’m just getting started, I don’t have much experience, so I wanted to ask a few more things. First, is it common to have more than one Agent (AI) node in a single n8n flow? I’m not sure if that’s standard practice or if it makes the flow too heavy or complex. Second, is there a character limit for the agent’s instructions? While researching how to write good prompts and improve RAGs, I found a video where a YouTuber said that if you add too much information in the instructions, the model might start hallucinating. He didn’t explain exactly why, just mentioned it as a warning — and that got me wondering. Does that really happen? Is there a recommended limit? And if so, how do I know when I’m going over it? I’m still exploring everything, so any practical tips or insights are appreciated!
It’s common sense. Let’s think like this, imagine that you have two customer service, one for serve user issues, one for serve technical issues. AI Agent also has a function like that; you can instruct the Agent to do specific task that you have given to the AI.
No, there’s no character limit for the Agent’s instructions, but be aware with token usage and pricing for the model, because when you’re adding detailed instructions to the Agent, it’s included to your AI model that you use. Also, the YouTuber was right, “simple prompt make AI hallucinating, vice versa for too long prompt”, although agent’s instructions does not have any character limit, you need to write it efficiently to make the AI understand what is exactly his task.
Yes, your approach is valid and works well for single-turn or short interactions. Storing the system prompt in a variable (like {{ $json.test }}) and injecting it into the AI Agent node helps reduce clutter, keeps the workflow flexible, and saves token usage in multi-agent environments.
Here are the limitations to watch for:
Prompt size limits: If your variable ever stores too much text (e.g., complex agent instructions + user input + memory + tool results), you might hit OpenAI’s token limit (especially with GPT-4).
Loss of multi-step memory: Since you’re manually injecting the system message and not using built-in memory chaining or external memory (like Pinecone/Postgres), any back-and-forth logic won’t persist across runs unless you implement your own memory management.
Debugging: Dynamic system prompts can be harder to debug later since they don’t appear statically in the node config — make sure you log or persist them if needed.
If you’re not using extended memory or RAG-like multi-turn sessions, your current method is clean, modular, and scalable for most use cases. Just keep an eye on input size if you expand the flow.