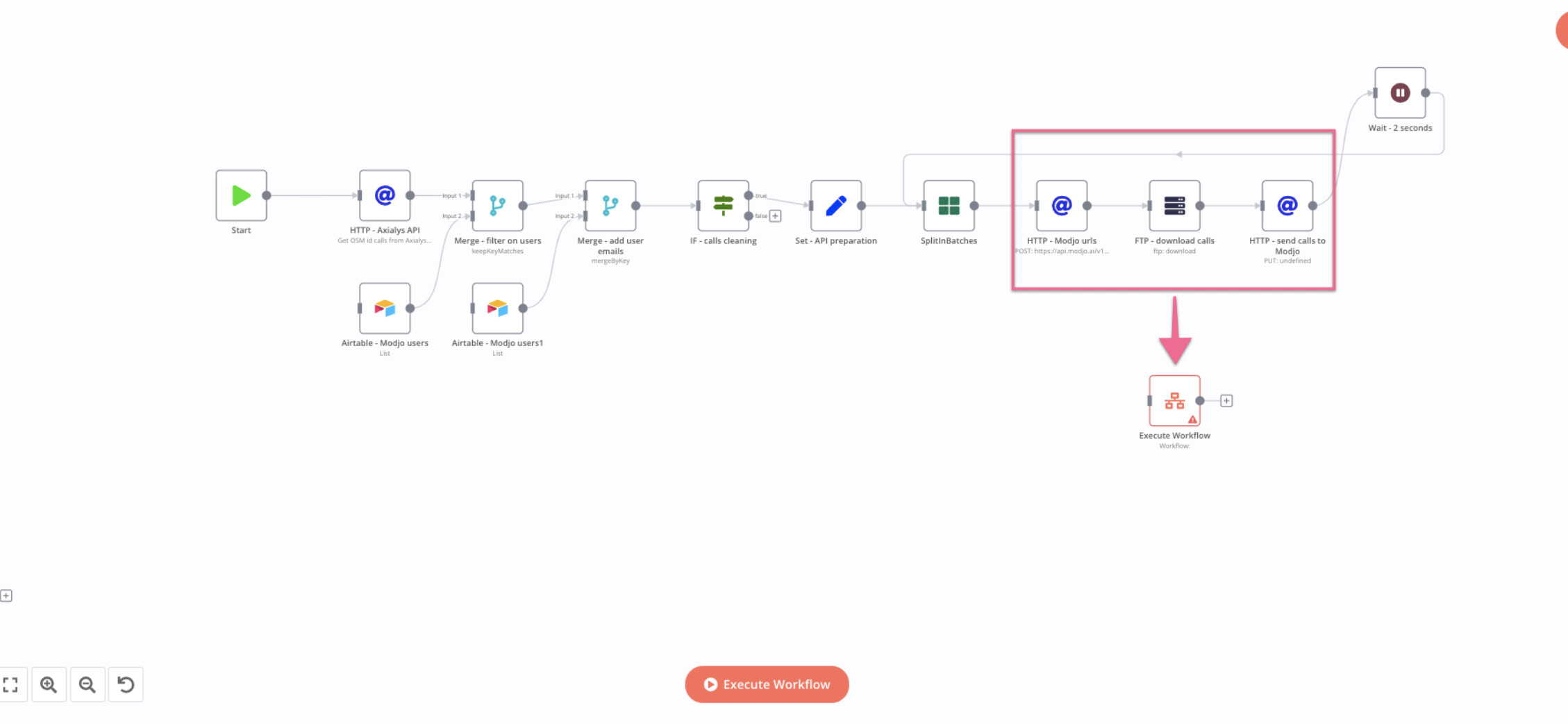
For 1st option, this mean I would need to put all the node in the red square into a Execute workflow node, and call this node at each iteration of the SplitInBatch loop?
For 2nd option, do you have an ETA to share?
Thanks,
Ludovic
For 1st option, this mean I would need to put all the node in the red square into a Execute workflow node, and call this node at each iteration of the SplitInBatch loop?
For 2nd option, do you have an ETA to share?
Thanks,
Ludovic