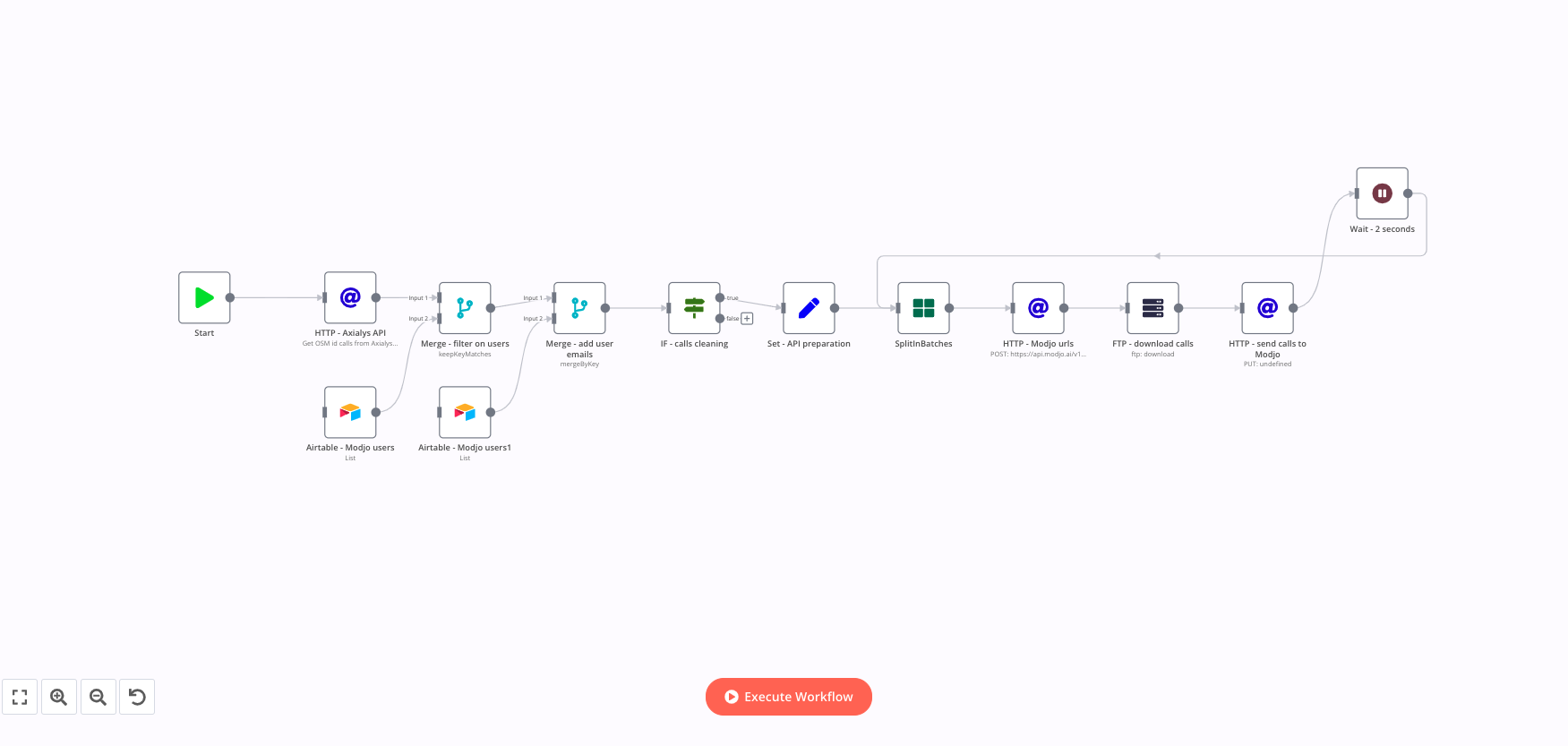
I’ve built a workflow that aims to download .mp3 files from an FTP server and send these downloaded .mp3 files in a tool called Modjo.ai, a conversational analysis tool, using Modjo’s API
The workflow is structured into 2 pieces:
1st piece: get the urls of all the .mp3 files to be downloaded in one database
2nd piece: loop 1 by 1 over this database, and for each iteration, download the .mp3 file from the FTP server and send the dowloaded .mp3 file in Modjo.ai using Modjo API.
I’ve started building this workflow using the n8n desktop app. And it works perfectly well when I launch the workflow on my n8n desktop app.
Then I turned to n8n.cloud. And when using n8n.cloud, it stops after 3 iterations of the SplitInBatches loop, with the error “Connection lost” when reaching for the 3rd time the FTP node.
The reason will be that n8n runs out of memory and so crashes. Depending on which subscription you have on n8n.cloud, will it have more (largest plan) or less (smallest plan) memory.
The Desktop App usees your system memory, which will be much larger than the one the cloud instances have, and for that reason, it works fine.
We released with the latest version( 0.156.0) an update to use less memory when working with binary data (it stores the data on the hard drive rather than RAM). That version is however not available yet on n8n.cloud and also not possible to activate that setting yet. Should however become available soon.
For now, the best thing to do would be to split out the workflow part which works with binary data into a sub-workflow and make sure that this sub-workflow returns only minimal data. It should then work fine.
I think I may need a bit more info on how memory works in n8n
If n8n runs out of memory after 2 SpliInBatch iterations, is it possible to clear memory at the end of each SplitInBatch iteration.
Say in my case, clear from memory the downloaded mp3 file after it’s been sent to Modjo?
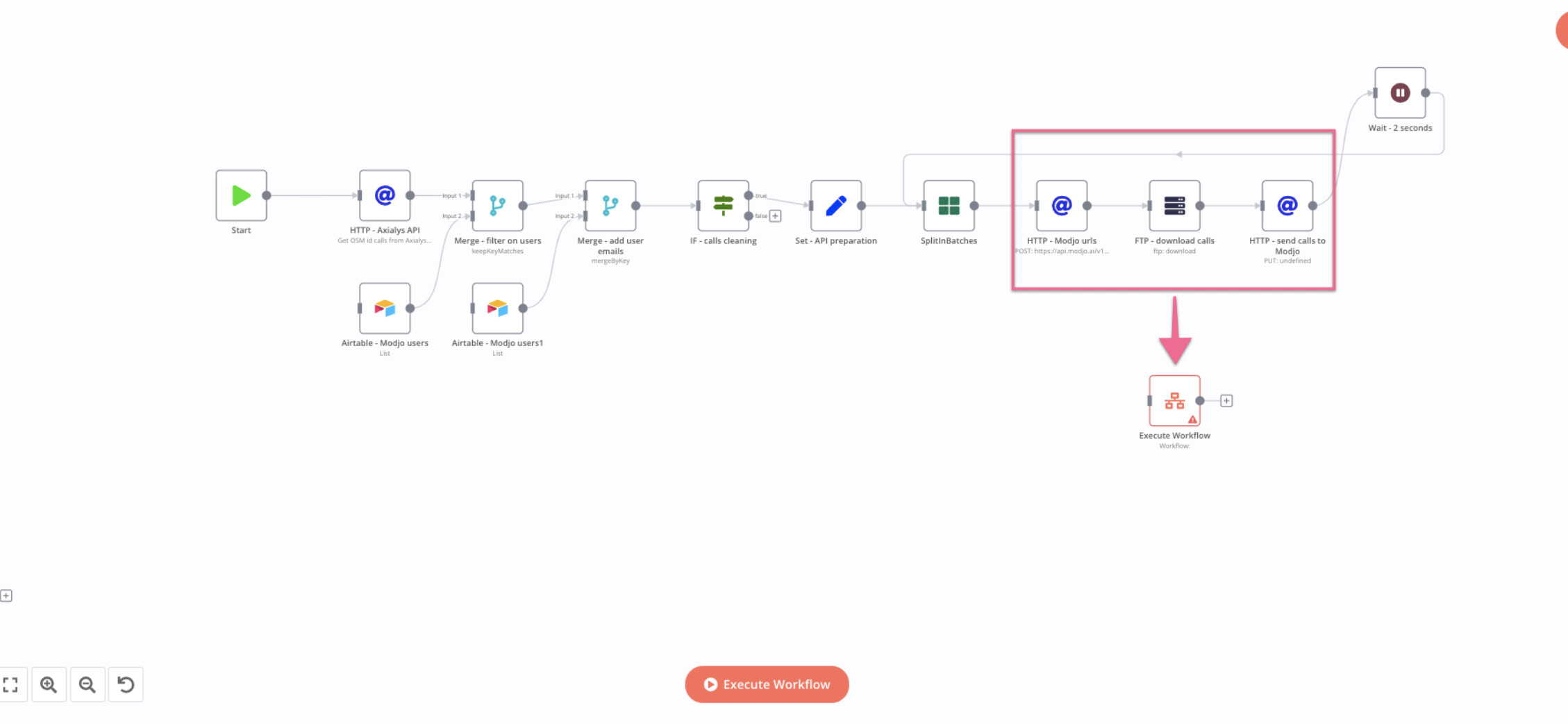
For 1st option, this mean I would need to put all the node in the red square into a Execute workflow node, and call this node at each iteration of the SplitInBatch loop?
Exactly. Make sure to add a Set-Node in the Sub-workflow which removes all data before returning. If you do not do that the data “leaks” back into the main workflow and you would be again where you started.
No sadly no exact ETA esp. because of Christmas right now. Assume 1-3 weeks.
Unfortunately, even with this tricks, it doesn’t work. My mp3 files, even downloaded one at a time and then freed up, seem to exceed the max memory… so I guess I have no choice to wait till the release.
What is the max size of a file that a workflow running on n8n.cloud start plan can currently bear? When running tests, my workflow works with 600 KB mp3 files but crashes with 1,4 MB mp3 files. So I guess it’s in between?
When moving from RAM to hard drive storage, by how much this will be increased?
That is hard to answer. Depends on multiple factors (what else is running at the same time, how the workflow looks like, if run in production or UI, …). Normally should 1.4 MB not be a problem at all even on the smallest cloud plan. Are you sure that you are not returning any data from the sub-workflow, especially not the binary data?
When running my tests, I was removing the SplitInBatch loop and was filtering on only 1 file at a time, in order to check from which size of the file it will start to crash.
Weird if 1.4 MB is not a problem even on the smallest cloud plan.
Any storage tips I should be aware of?
Not sure how large the data of the rest of the workflow is but all data adds up. So you can also try to reduce that and maybe also use a sub-workflow to only have the data in that main workflow that you actually require. Additionally, does it also matter what else is running in n8n and make sure to NOT have “Save Execution Progress” active as that will eat up also RAM.