I am trying to create a Locally hosted AI agent that I can “Train” with data/resources that my company has collected over 50 years. I work for a civil/structural engineering consultancy firm and we have decades of PDF files which include various building codes, templates of company proposal, specification documents, etc.
So far I am utilizing N8N running through Docker in a container. (Below link to GitHUB database)
I’ve solved the issue of allowing the application to see the designated file stored locally on my PC. The next problem I am having is finding a N8N workflow that can work to achieve what I want done. I am aware of Ollamas limitation on token sizes greater than 2000 so I would like to create some form of a PDF “Digester” that can break down these PDF’s into more manageable bites to then be stored in a vector database that the LLM can draw from. A key issue would be to ensure that the digested “bites” still understand the context of the previous bite and context isn’t lost along the way. Further some of these documents contain figures and tables that may need to be parceled out separately while still maintaining the original context of the overall document.
Most workflows i’ve tried use the “Read/Write File from Disk” which never gives an output (despite confirming file path can be seen by the container). Attached below is the closest i’ve gotten however this requires individual document placement as well as stops short when documents are too large.
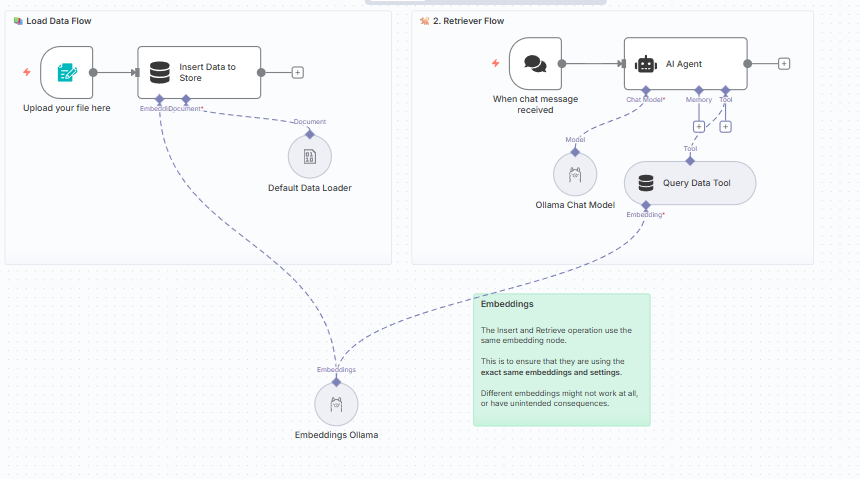
The end game is to have an LLM that has been “trained” specifically by data that this company has produced over the years in the hopes that it can spit out templates (Spec documents, proposals, reports, etc.) for future jobs that our engineers can the modify thereafter.
Thanks ahead of time for any and all help,
Cheers
P.S. I’ve answered the below to the best of my ability
Information on your n8n setup
- n8n version: - Version: 1.108.2
- Database (default: SQLite):
- n8n EXECUTIONS_PROCESS setting (default: own, main):
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
- Operating system: Windows