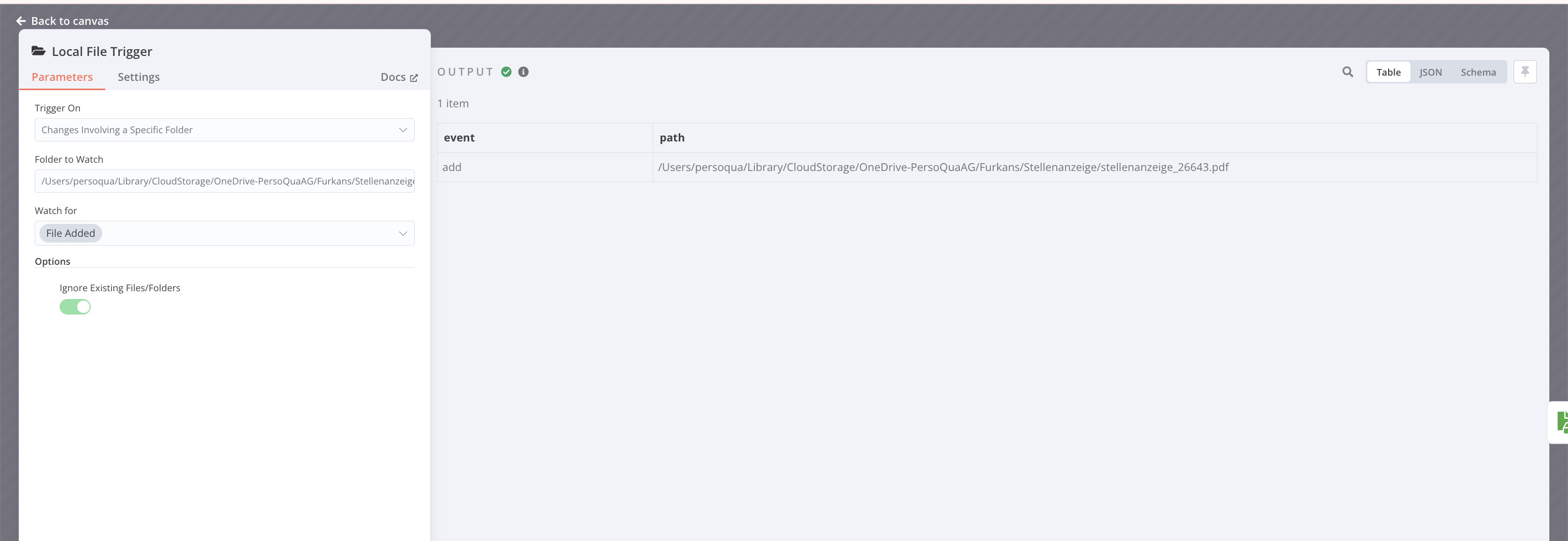
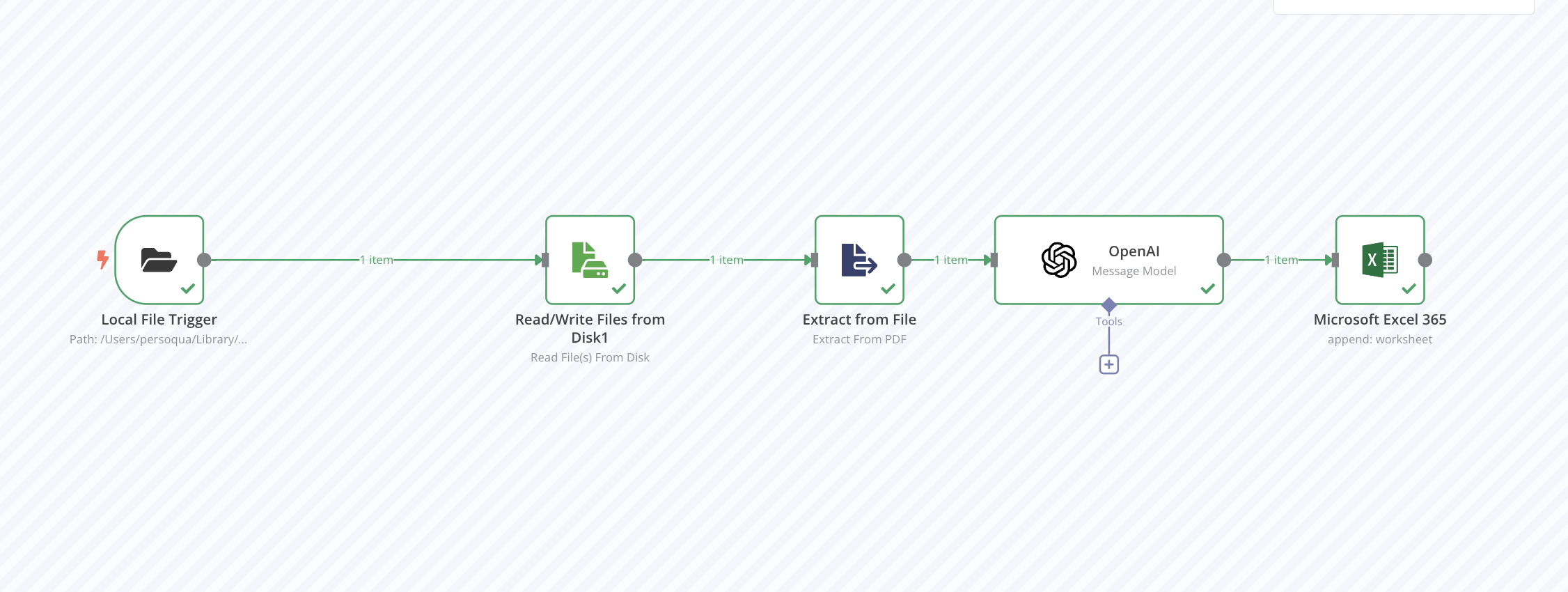
I have set up a workflow in n8n to process multiple PDF files placed into a specific folder. The extracted data from each PDF is intended to be appended as a new row in a Google Sheet. While the workflow functions correctly when a single PDF is processed—successfully appending a new row in the Google Sheet—issues arise when multiple PDFs are added simultaneously. In such cases, only one new row is created, and it gets overwritten with the data from the last processed PDF. My objective is for each PDF to result in a separate row in the Google Sheet, even when multiple files are processed concurrently.
Error Message:
No explicit error message is displayed; however, the expected behavior of appending multiple rows does not occur.
Workflow:
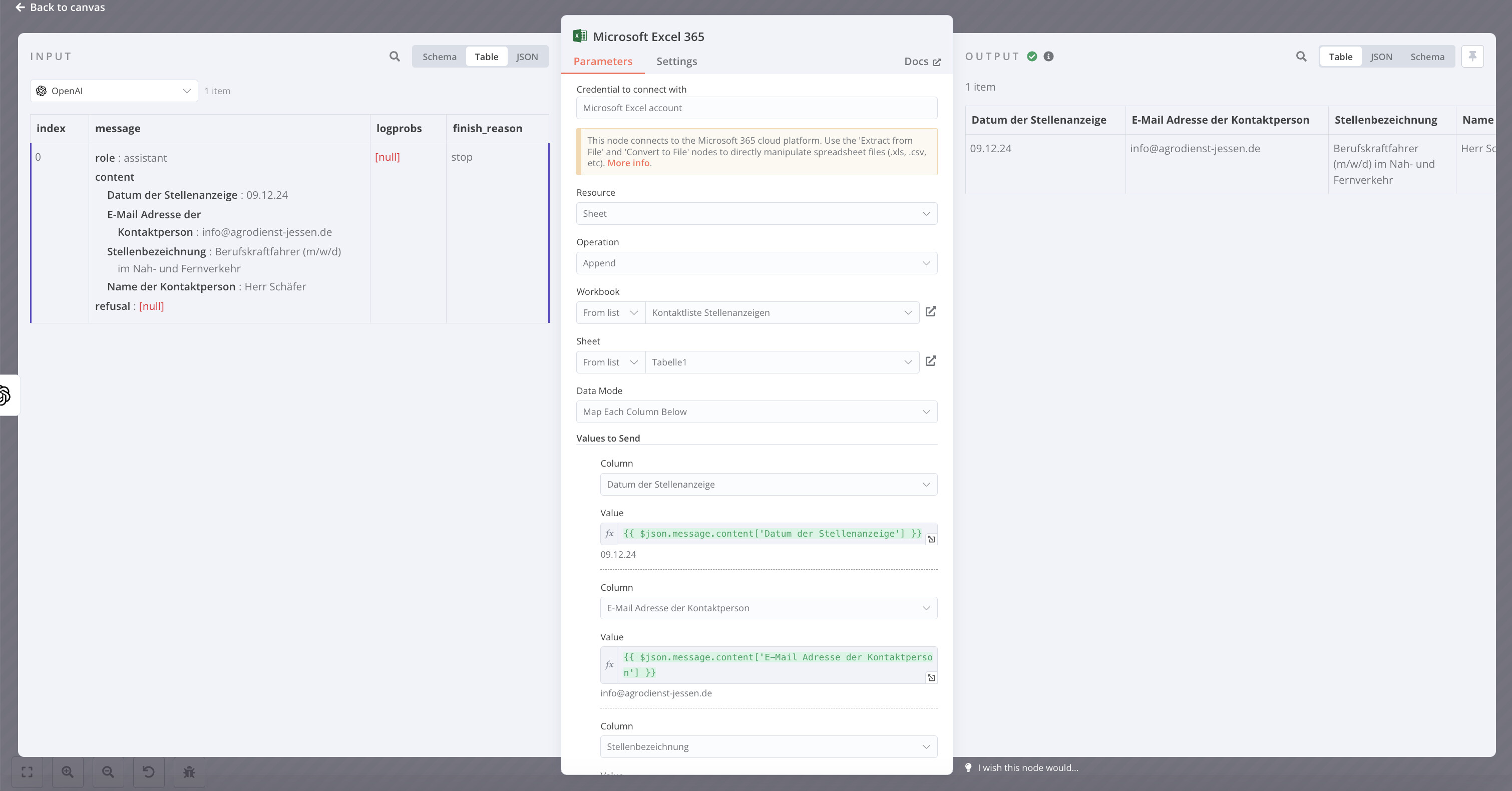
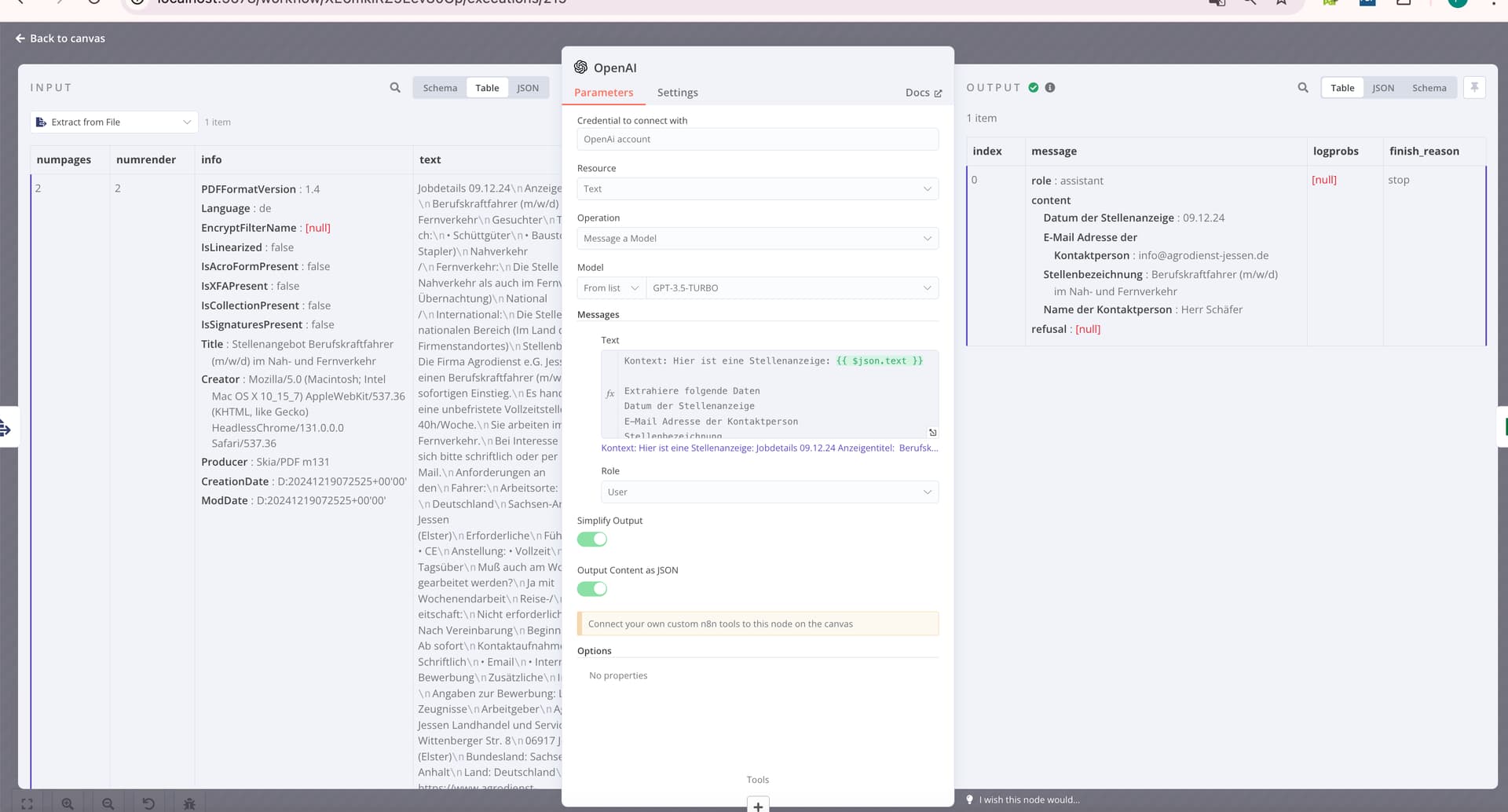
Output Returned by the Last Node:
The final node outputs the data from the last processed PDF file, which is then written to the Google Sheet. When multiple PDFs are processed, this results in only one row being appended, containing the data from the last PDF.
Information on Your n8n Setup:
- n8n version: 1.72.1
- Database: SQLite
- n8n EXECUTIONS_PROCESS setting: Default (
own,main) - Running n8n via: Terminal
- Operating system: macOS
- Browser: Chrome
Additional Context:
I have attempted to utilize the “Loop Over Items” node to process each PDF individually, but the issue persists. It seems that either the loop is not configured correctly, or the data is not being properly passed to the Google Sheets node. I would appreciate any guidance or suggestions to resolve this issue.
Thank you in advance for your assistance!