All, I have been running into two issues with my web-scraper for a dynamic website. I can’t find the answers in this forum, firecrawler and on youtube - would appreciate your help a lot! Ps i try to be as precise in my wording as i can, but please cut me some slack given my no-code background.
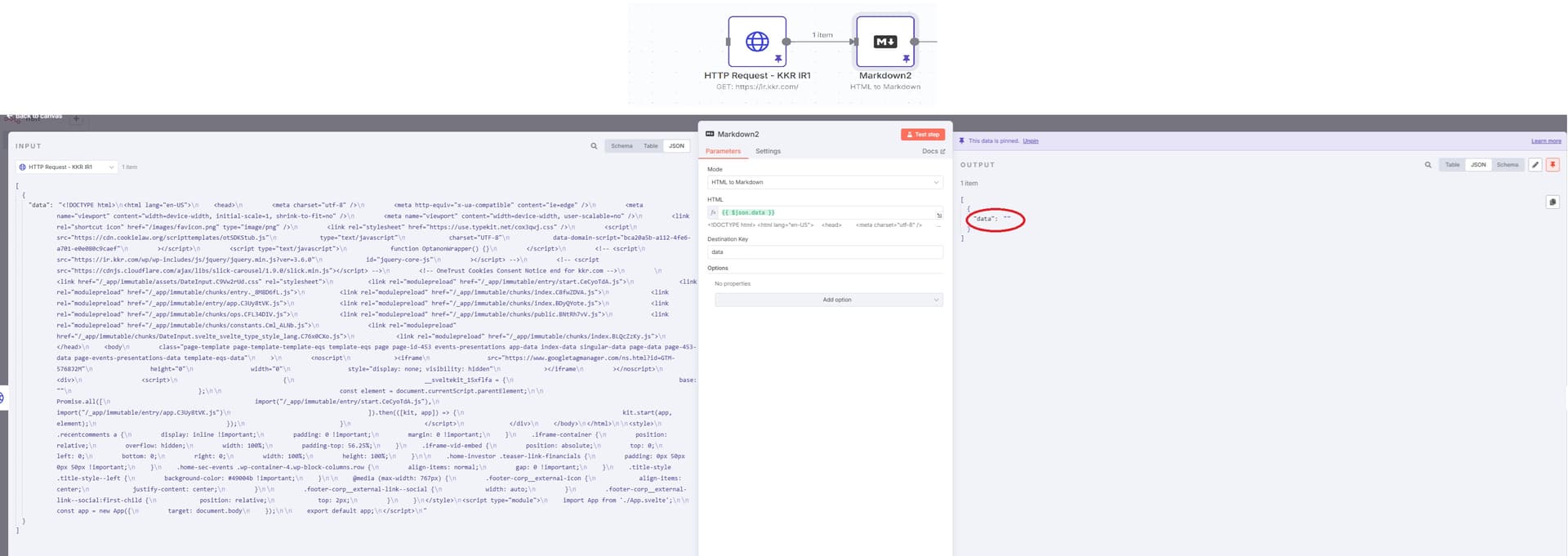
HTTP->Markdown for subdomains: in n8n I did a http ‘get’ request for a subdomain. I then want to turn the html from the http request into a markdown format. This flow works for the main domain “www.test.com” (all good), but it does not work for subdomains “www.media.test.com”. The markdown’s output is a blank data object " " (see screenshot 1). Does anyone know what I am doing wrong?
Subdomains and paths: a http request for a main domain 'won’t scape any subdomains or paths - is my understanding correct? If so, could you point me to how i could scrape 1) doman 2)sub 3)paths, all in one go? (without having to find all paths and subdomains and doing individual scrapes? I checked firecrawl’s documentation, which is experimenting with extracting multiple paths only ‘www.test.com/*’ - but its only for paths and still a bit buggy.
Thanks a lot n8n community for any help with the above!
Felix
Thanks for the detailed post and the screenshot — that helps a lot to understand the issue.
1. HTTP → Markdown not working on subdomains:
What you’re running into is likely due to the way modern websites (like media.test.com) load their content. From the screenshot, the HTML you’re getting via the HTTP Request node is mostly <head> content and JavaScript references — this means the page is rendered client-side with JavaScript (probably React, Vue, or similar).
The HTTP Request node in n8n fetches only static HTML. It doesn’t execute JavaScript, so any dynamic content loaded by JS won’t be included in the response. That’s why your Markdown node receives mostly empty or useless content and outputs "".
What you can do:
Use an external service that renders JS, such as:
Apify
You can call them from n8n via HTTP nodes. These services return the fully rendered page (after JS execution), which you can then convert to Markdown.
2. Scraping multiple subdomains/paths:
Yes, you’re correct — an HTTP Request to a root domain will not automatically crawl subdomains or paths. n8n does not have a crawler built-in.
If you already know the list of URLs (including subdomains and paths), the best approach is:
Use a Set node to store them as an array.
Use SplitInBatches to iterate.
For each one, send an HTTP request and handle the output (convert to Markdown, store, etc.).
If you don’t have the list, you’ll need a crawler to generate one. Firecrawl and similar tools are working on this, but it’s still experimental and not reliable for production.
Extra tip: If the site has a sitemap.xml, you might be able to get a list of URLs from there and use it as your source.
Let me know if you want help building a sample flow with batches and Markdown conversion.
Erick! This is super helpful: your explanations of what walls I hit, and possible workarounds, as well as your ‘extra tips’ Seriously, very much appreciated!