A couple of days ago I found out that my n8n instance crashed and rebooted. Turns out it ran out of memory. I’m not sure how though… because I only have ~5 fairly simple workflows running (DB read/writes).
For context, the main workflow pings an Airtable DB every 60 seconds and updates individual records if necessary. Supporting workflow sends out email alerts when prompted by the main workflow
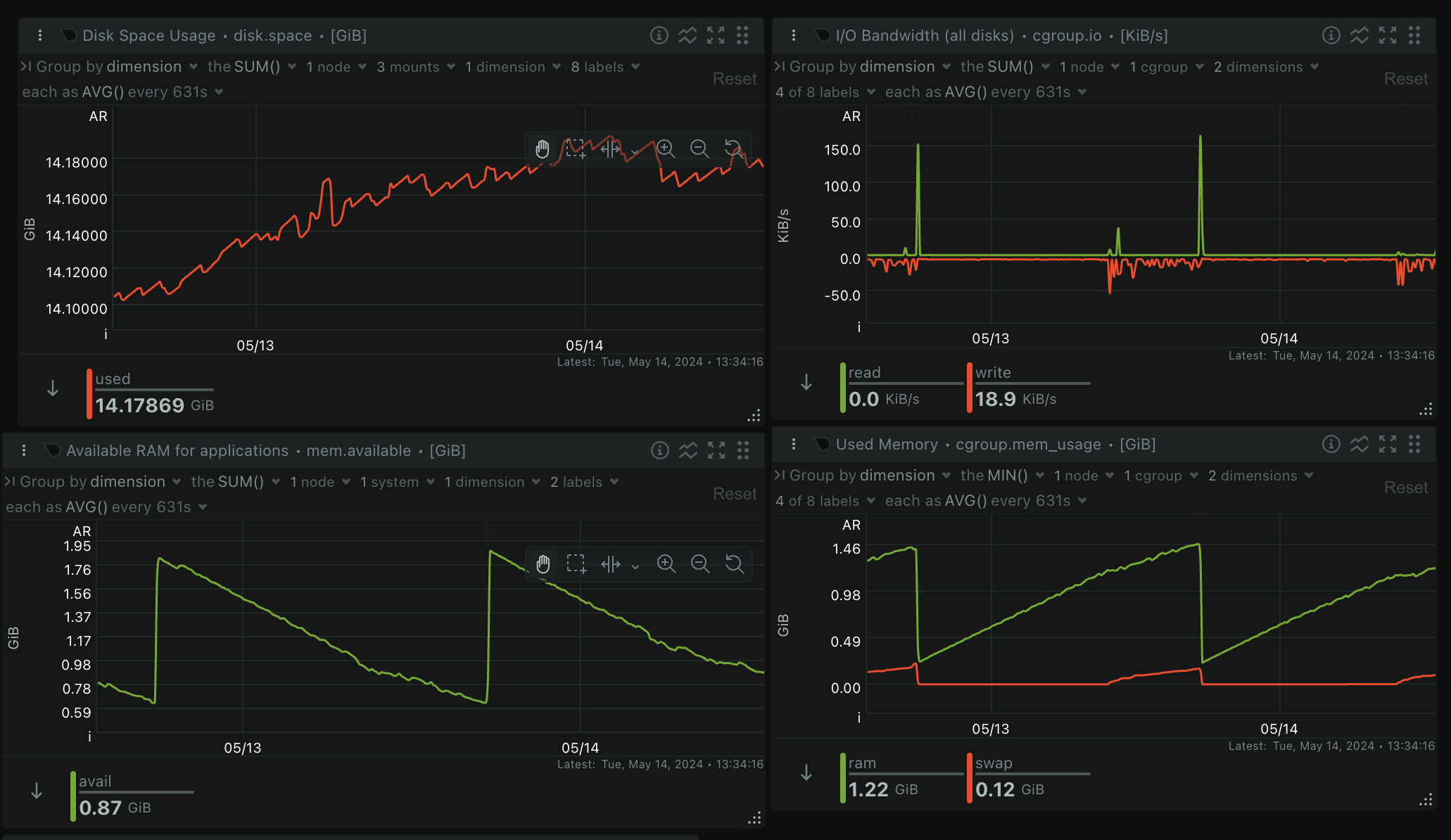
To diagnose, I set up netdata to track RAM and CPU usage. See below.
What is the error message (if any)?
Here you can see the memory leak before I manually restarted the instance
Might have overlooked it but how many (v)cpu cores do you have available?
With Docker there is some overhead and the garbage collection for the container doesn’t work properly if you have 1 cpu or less.
Any ideas as to what’s going on? I read in this post that adding a Set block at the end of the flow might empty the memory after execution. So I’m testing that right now
I am not seeing any leaking in my own workflows, do you have anything else installed on the server?
What are your workflows actually doing as well? What you see as ~5 simple workflows may actually be heavy on usage as it is.
Where did you see originally that it ran out of memory? The memory usage will grow until it hits a certain amount then internally it will sort itself out.
Have you tried setting up monitoring using the /metrics endpoint to see what the internals are doing?
Compare the contents of this first item to a record in Supabase
Perform a few text (formatting) replacements
Pass feed content to another (worker) workflow and execute it
Worker workflow (on the same server) makes an HTTP request with the info
This workflow runs every 60 seconds. The worker workflow runs maybe 2-4 times every hour. Everything else runs maybe 1-2 times a day.
I’m convinced the leak is happening because of either the RSS fetch node or the code node (return first item in RSS array). The container runs out of memory and reboots → repeat every ~20 hours
The storage use is also going up which makes me wonder if n8n is storing the RSS feed items in the DB somewhere. I’ve turned off logging for successful runs with EXECUTIONS_DATA_SAVE_ON_SUCCESS=none ENV setup so the executions shouldn’t be slowly increasing storage use.
Is there any way to check why n8n is using up server storage? Would it be better to stop using SQLite and set up a postgres server since I have ~60 executions/hour?
I’m new to all this but very eager to learn—thank you for all the help!
The RSS node should be ok I have been using it for a while now but without seeing some logs it would be hard to say. The code node we know is heavy on usage as it creates a sandbox on every run so if you were passing in a bunch of items depending on the option being used it would use more memory.
With storage the RSS trigger only stores the datetime of the first item in the feed when the node runs, This datetime is compared against the current datetime to see if the item is new and needs to be picked up in the workflow.
The memory should always be freed up, In the last 48 hours how many times did you restart n8n as those memory graphs don’t look terrible also they do instantly increase twice which makes me think the instance is doing a lot.
I have done some digging through some of the cloud instances to look at the stats and I am not seeing anything that looks like a memory leak at the moment and the code node is one of the most used nodes.
I would recommend enabling the metrics endpoint and maybe monitoring the n8n application itself which could help.
I suspect the workflow is saving all the RSS feed data (30 records every time) in memory during each run, and that’s what’s causing the memory bloat. Do you think so as well?
Should I try setting
N8N_DEFAULT_BINARY_DATA_MODE=filesystem
or
EXECUTIONS_DATA_PRUNE_MAX_COUNT=(something like 100)?
Its unclear if the pruning affects binary data stored in memory—could you please let me know?