I’m currently working with n8n version 1.1.1 and using the Starter Plan on the cloud environment. My workflow is fairly complex and involves fetching, grouping, and outputting worklogs from Jira. To circumvent memory issues, I’ve offloaded tickets with thousands of worklogs into subworkflows. I have implemented pagination wherever possible. Unfortunately, it appears there are no additional pagination options to further reduce the workload in this case.
Interestingly, the subworkflows run smoothly when executed individually. However, when I run the entire main workflow, my cloud machine crashes.
Does anyone have insights into when the memory gets released after a workflow or subworkflow has completed? Or perhaps there’s a better approach to handle this issue?
I’ve been working on a workflow involving fetching, grouping, and outputting worklogs from Jira. I previously had issues with memory, but I’ve discovered that Jira allows for more fine-grained control, allowing me to streamline the workflow further.
Despite this improvement, my original question remains: When does n8n release the memory after a workflow (or subworkflow) has completed? Understanding this would be crucial for optimizing more extensive and complex workflows in the future.
The memory is only released once a workflow is completed - this goes for sub-workflows and their parent workflows.
When using sub-workflows, it’d be also worth ensuring that it doesn’t return all of its data to the parent.
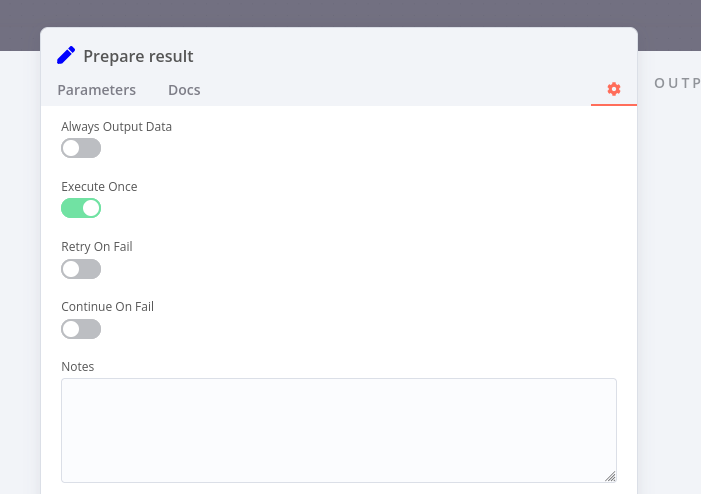
You can achieve this by using a single Set node in your sub-workflow, returning only a single (very small or even empty) item using the “Execute Once” option:
In terms of memory consumption, it’s also worth noting that nodes like the Code node are on the “naughty” list of high memory usage: Memory-related errors | n8n Docs
Firstly, I appreciate the insights on memory management. That brings me to a key question: What’s the advantage of using subworkflows if the memory only gets released once the entire workflow, including parent and subworkflows, is completed? It’s often suggested that structuring it this way can help, but I’m not seeing the benefit here.
Regarding Code nodes, they are unfortunately unavoidable in my case. I’m aware they are on the “naughty list,” but they are necessary for my specific tasks.
As for minimizing data returns from subworkflows, I’ve already taken steps to do so, so thanks for reinforcing that point!
The “Execute Once” option doesn’t quite work for me, as I need all the results, not just a single, reduced item.
On a side note, I did manage to find an alternative solution by setting a filter in my query. It’s a workaround for now, but I’m still very interested in understanding the memory dynamics better.
Just to make sure we’re on the same page, the sub-workflow only holds the data for the current batch in memory, after which the memory is freed again - so smaller sub-workflows means the memory is released more often, which should result in less issues for you
I can absolutely understand that Code nodes are required for you, just thought I’d also mention it! And glad to hear you found an alternative that’s working for you