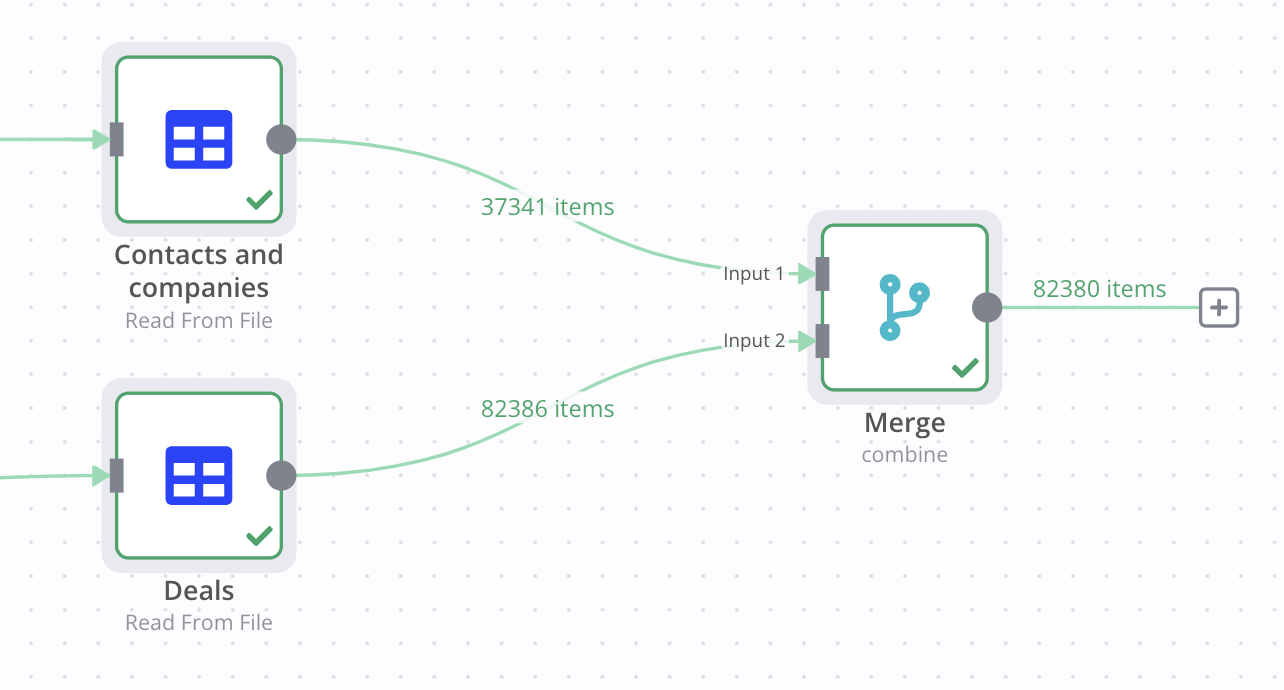
I have 2 CSV datasets. The first one is for Contacts & Companies and the second one for Deals.
These 2 are linked together by the fields:
Contacts & Companies: MIG_CLNT_Clients_NRT_CLNT_ID
Deals: MIG_SCTR_SalesContracts_NRT_SCTR_OWNER_CLNT_ID
I want to join the output of the deal & contact in single objects using the 2 fields above, preferably using the Merge node, as I already mapped the rest of the flow to this structure.
I want to use the merge node to use ‘Both inputs merged together’ for fields to match MIG_CLNT_Clients_NRT_CLNT_ID in first input and MIG_SCTR_SalesContracts_NRT_SCTR_OWNER_CLNT_ID from the second input and include all matches.
This works but the problem is that I have 38000 contacts and 82000 deals, so the node timeouts if I don’t split into batches.
Is there a way to process each deal with the whole input of the contacts & companies, do the join and then do the same with the next deal and so on?
Please share your workflow
If I connect the Merge node to the Split in Batches it will take the next deal but no input comes in ‘Input 1’ - contacts.
Hi @alexnemes, this might be a tough one, but let’s try to unpack this step by step.
This works but the problem is that I have 38000 contacts and 82000 deals, so the node timeouts if I don’t split into batches.
Can you confirm how exactly the timeout materializes/which error exactly you are seeing? Are you using n8n cloud or a self-hosted version? If it’s the latter, can you confirm the server specs you are working with?
And lastly, can you also share the data structure used in each of your files (it’s fine to redact the any actual data, I just want to understand the amount of data you’re working with)?
We are using the self hosted Version 0.208.1
I do not know the server specs yet.
Would be great if it was possible somehow to merge 1 deal at a time with the corresponding contact from Input 1, or have a single array with all deals joined with their contacts. At this point this amount of data is a bottleneck for our project as there are Hubspot contacts & companies to upsert and associate deals to them in the rest of the flow
So from the looks of it your instance seems to be capable of processing that much data, but your browser doesn’t seem to be able to render the result.
Perhaps you can simply build your workflow with smaller datasets for testing, then switch to the production files once ready and simply have it do its magic in the background?
@MutedJam Yes seems to be working in background as the executions are marked with success.
I am thinking of sending each object resulted from merge via webhook to trigger the main flow that checks and adds deals, companies, contacts etc for each object from the merge node.
My question is: Will that main flow execute each of the 82380 items in sequential order as received from webhook? It is important to be sequential in order to not add the same objects twice if executions happen at same time and threads search for the same contact for example, don’t find it and both add the contact, deal or company.
I am thinking of sending each object resulted from merge via webhook to trigger the main flow that checks and adds deals, companies, contacts etc for each object from the merge node.
Sounds like a solid approach to me, provided you throttle your request enough not to overwhelm your instance. The order of items should remain the same, I tested this out a while back over here.