I have a small question: what node can I use to check connectivity of internet connection?
The idea is to make a ping to 8.8.8.8 every seconds and trigger something else when the ping is in failed for 2 or 3 ping consecutively.
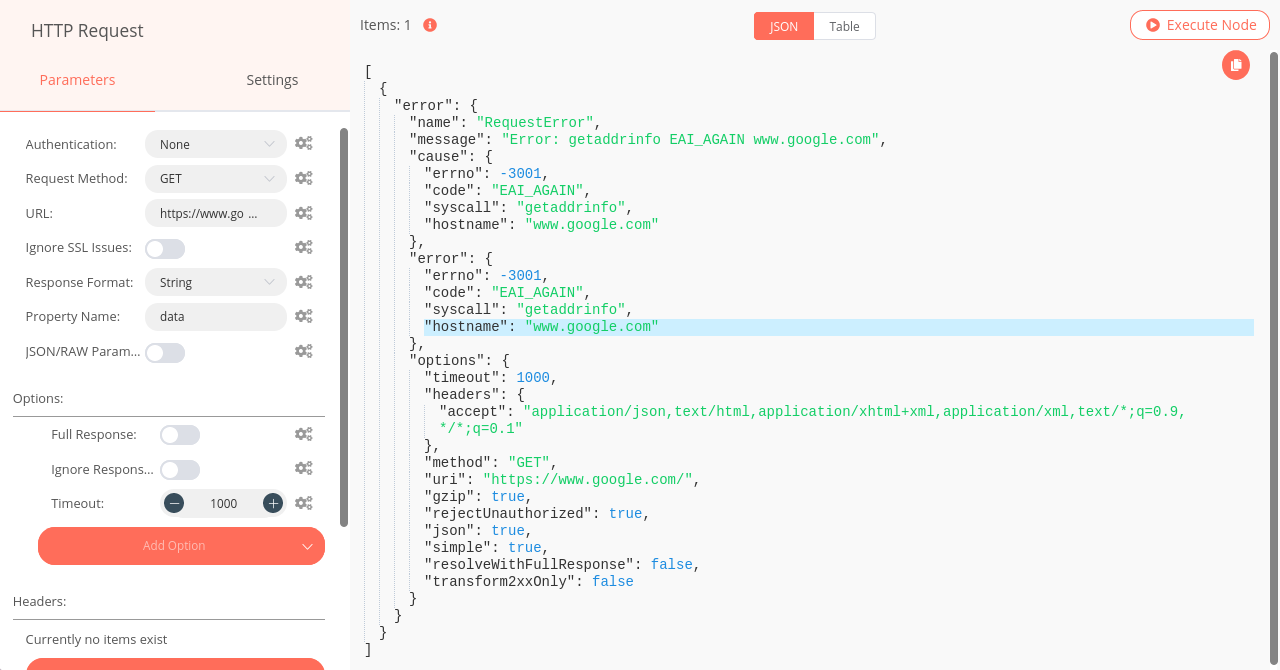
If I try with the “Execute Command” node, output tells me it can’t execute “ping 8.8.8.8” due to root permission problem.
So maybe I’m wrong and I not using the right node to make this workflow.
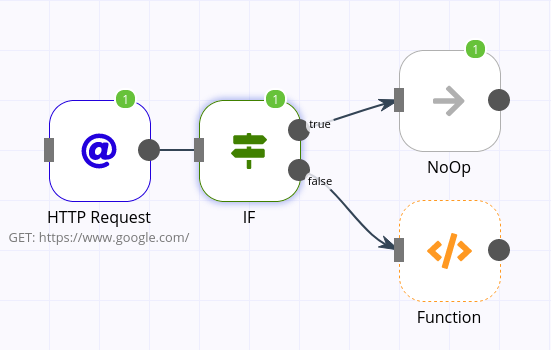
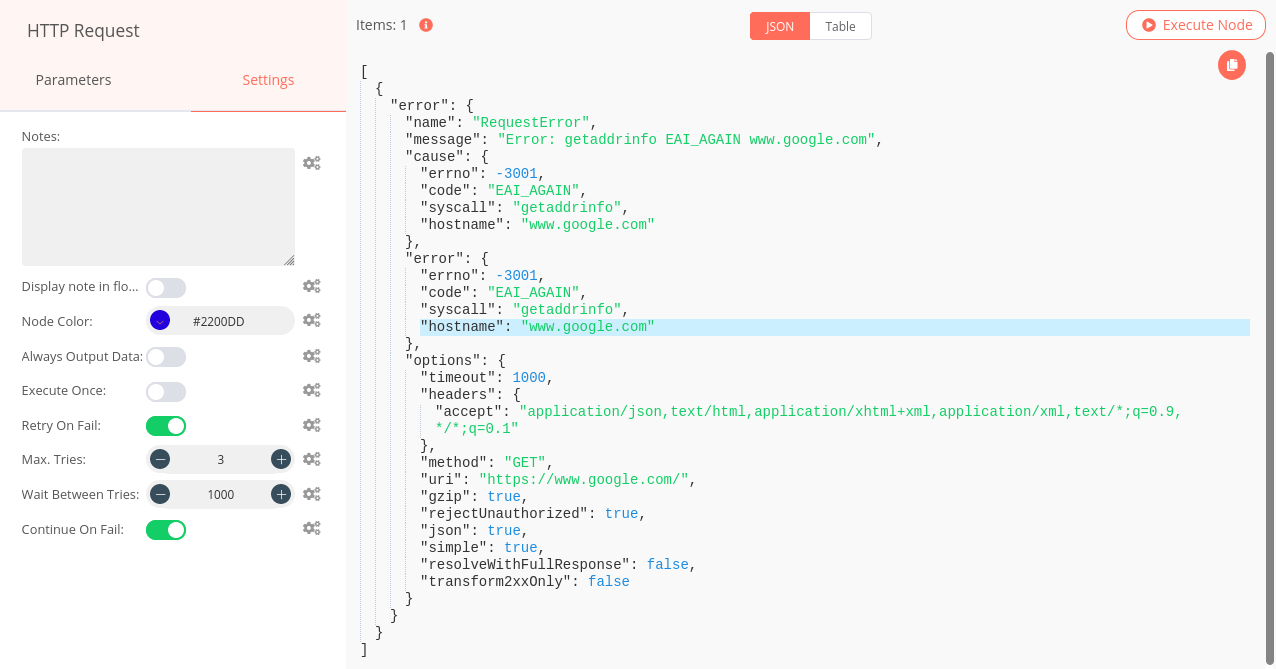
Hi @Elpatii , this is a quite interesting issue, one solution is to add the permission to your user (or use root), other solution that i will use, is using HTTP Request node to retreive Google page, enable the continueOnFail and retryOnFail options, then use an IF node to verify if the request failed or not
Hi @dali, thanks for your reply! I’d in mind to use a GET request, but I’m wondering about the network “cost” against to ICMP. Thanks for sharing your configuration about this workflow.
I’ll thing about it
EDIT: for information, if someone search a solution about the “permission denied (are you root?)” when running a ping as default user “node”, it’s a security restriction of BusyBox in Alpine.
To resolve this, I now launch my docker container using the debian version image “n8nio/n8n:latest-debian”.
So, I’ve now something functional. Every 10 seconds, a ping to 8.8.8.8 is made. If error is “0”, do nothing. If error is “1” (ping failed for 10 seconds), sends a mail to SMS gateway via internal Exchange open relay.
But, some little problem: if internet is down, I will receive my SMS to tell me, cool, this is what I want. But, it will sends me 1 SMS every 10 seconds
Has someone an idea to prevent this? Like making a queue or something else?
In that case you could store a timestamp of when the ping last failed (in the false branch after your ‘if’ node). You could then check this timestamp at the start of your workflow, and if it’s within the last hour (say) you could not do the ping.
I will use another (professional) solution, but I’m new to n8n (I’m coming from Huginn) and I was wondering if this kind of purpose could be for n8n, it’s a way to learn the tool
Actually do not see anything wrong with using n8n for that. Sure there is always a more professional solution out there for everything but the question is really if it is worth setting it up. And that does not end there, it then also has to get maintained long-term.
I personally prefer to have as less system as possible. Keeps everything simpler, with less stress and it is clear where I look if something goes wrong. In the past I did write a lot of bash scripts and triggered via a cron. These days I do all of that via n8n workflows.
I understand where you’re coming from but in his particular use case i would’ve used a system that would simply connect to a n8n webhook incase the connecting goes down or anything like that
Interesting, but also then you would have to have that other system running which then connects to n8n. Additionally will you double the risk that it does not work. Because it would then fail if either one (the other system or n8n) is down.
Redundancy would only be if it would still work if any of them is still up. But in the above-described case does it sound like something external would trigger n8n when there is a problem, and n8n would then for example send an SMS via Twilio.
So if the external system is down, it would never trigger the n8n workflow.
If n8n is down, would the external system try to start the workflow but because it is down nothing would happen. So they are dependent on each other and both have to work for this system to work.
The idea of using n8n was to have something simple, that someone could maintain or fix if I’m not here.
As Jan told, bash script or whatever is good, but if I’m the only who can maintain, understand and fix the script, it’s a problem because it creates a dependence.
And with n8n, it’s easy to understand the workflow with this nice GUI.
Concerning the external system, for me it’s a SMS physical gateway that could receive email and convert the body into SMS.
Of course, for this purpose, we can’t rely in internet because it’s to diagnose that it’s down, this is why I send mail with local Exchange server to the SMS gateway. It only needs the local network up.