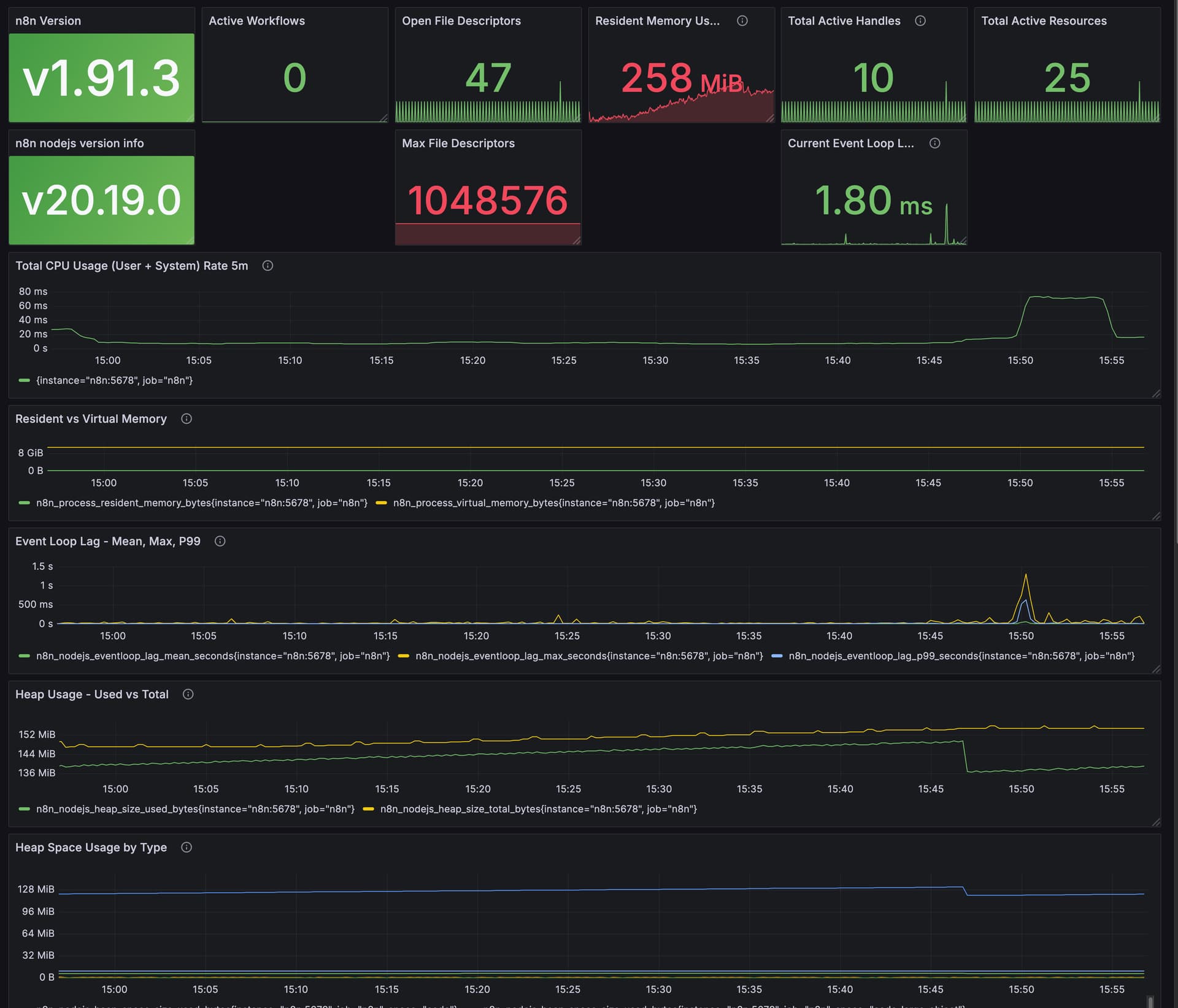
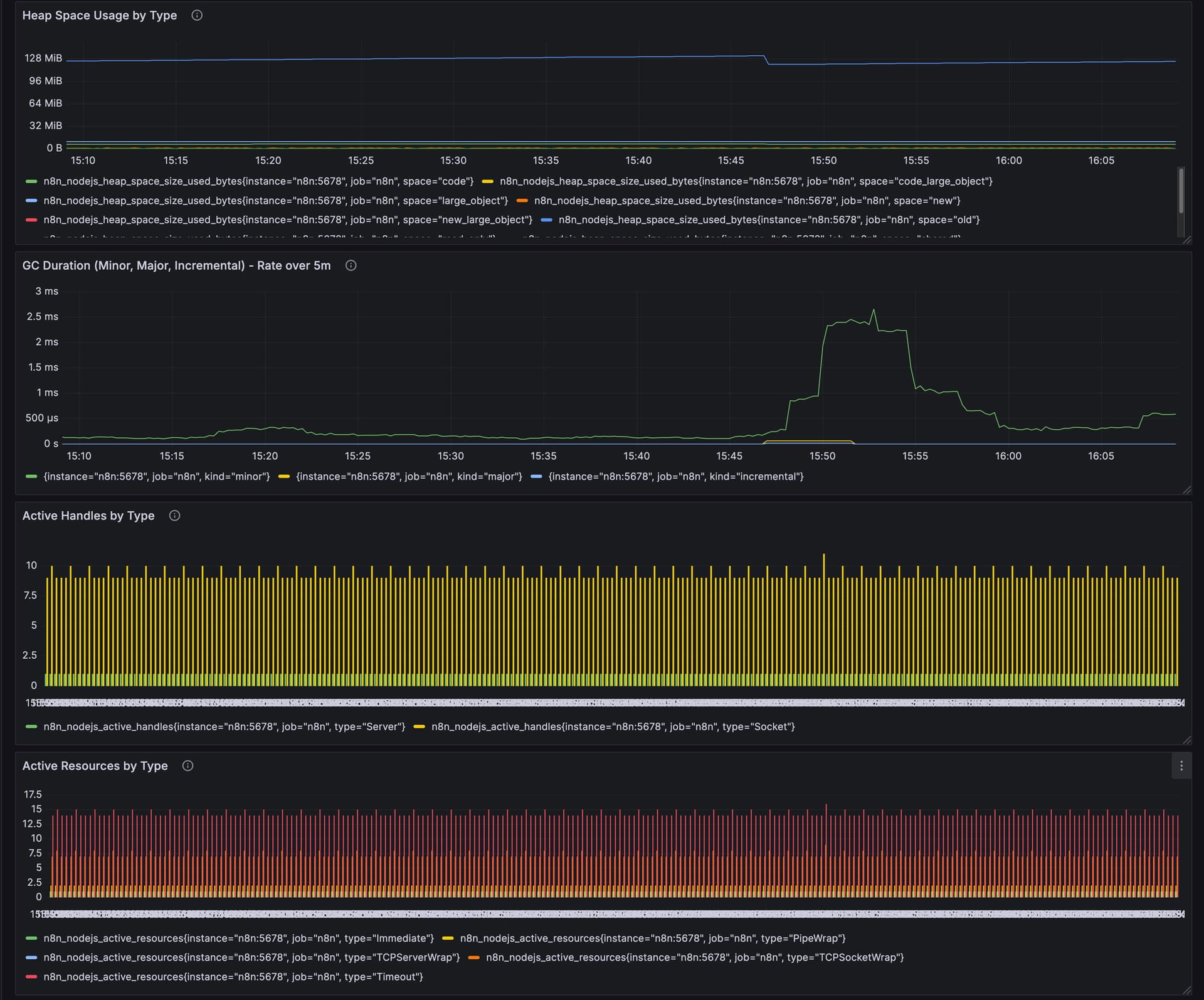
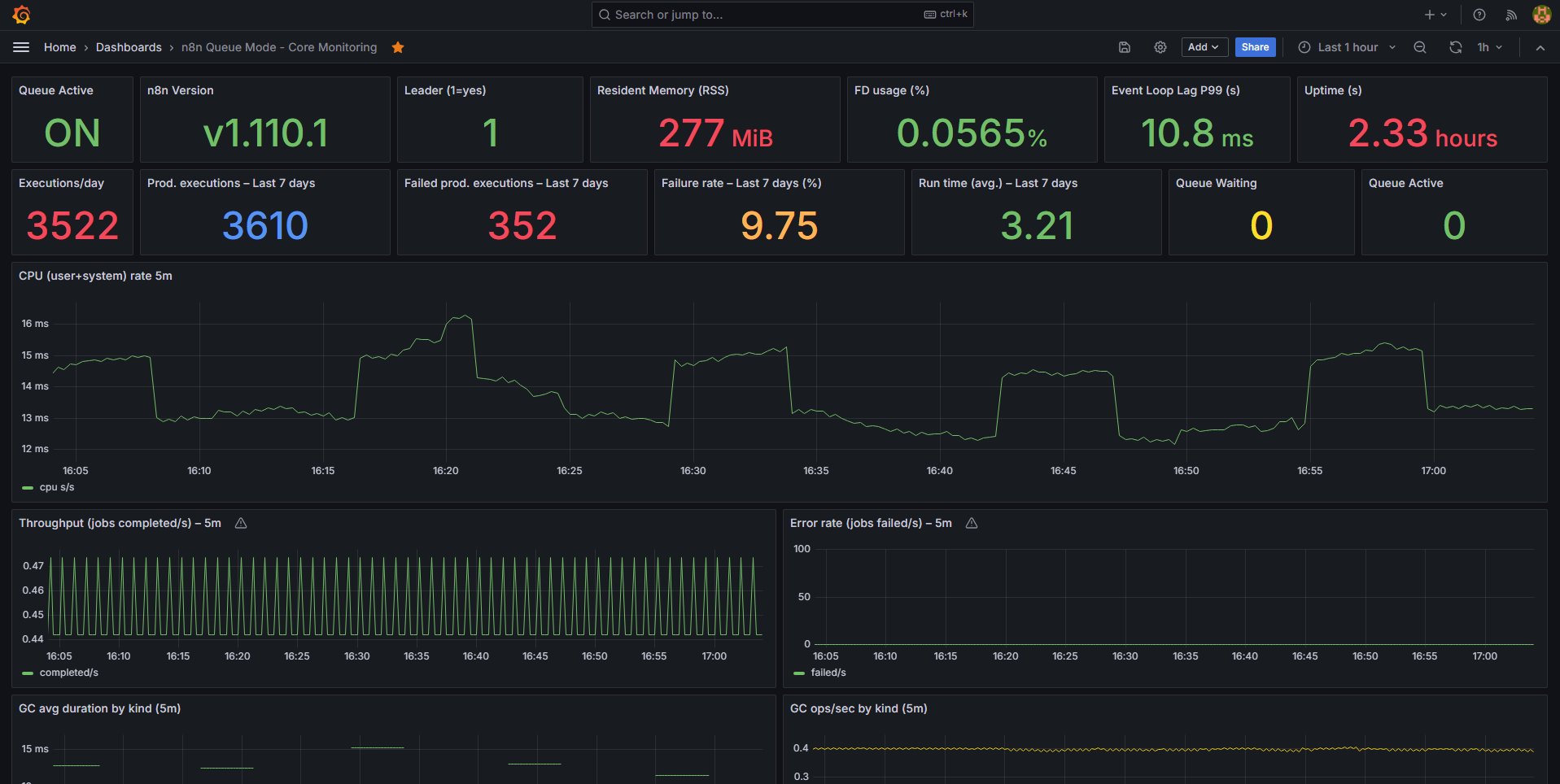
Summary
{
“annotations”: {
“list”: [
{
“builtIn”: 1,
“datasource”: {
“type”: “grafana”,
“uid”: “-- Grafana --”
},
“enable”: true,
“hide”: true,
“iconColor”: “rgba(0, 211, 255, 1)”,
“name”: “Annotations & Alerts”,
“type”: “dashboard”
}
]
},
“editable”: true,
“fiscalYearStartMonth”: 0,
“graphTooltip”: 0,
“id”: 6,
“links”: ,
“liveNow”: false,
“panels”: [
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: [
{
“options”: {
“0”: {
“color”: “red”,
“index”: 1,
“text”: “OFF”
},
“1”: {
“color”: “green”,
“index”: 0,
“text”: “ON”
}
},
“type”: “value”
}
],
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 2,
“x”: 0,
“y”: 0
},
“id”: 15,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“editorMode”: “code”,
“expr”: “sum(up{job=“n8n”})”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Queue Active”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 2,
“y”: 0
},
“id”: 1,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: true
},
“showPercentChange”: false,
“textMode”: “name”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “max by (version) (n8n_version_info{job=“n8n”})”,
“instant”: true,
“legendFormat”: “{{version}}”,
“refId”: “A”
}
],
“title”: “n8n Version”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 3,
“x”: 6,
“y”: 0
},
“id”: 2,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “max(n8n_instance_role_leader{job=“n8n”}) or on() vector(0)”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Leader (1=yes)”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “bytes”
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 9,
“y”: 0
},
“id”: 8,
“options”: {
“colorMode”: “value”,
“graphMode”: “area”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “sum(n8n_process_resident_memory_bytes{job=“n8n”}) or on() vector(0)”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Resident Memory (RSS)”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“max”: 100,
“min”: 0,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “percent”
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 13,
“y”: 0
},
“id”: 10,
“options”: {
“colorMode”: “value”,
“graphMode”: “area”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “100 * sum(n8n_process_open_fds{job=“n8n”}) / sum(n8n_process_max_fds{job=“n8n”})”,
“instant”: true,
“refId”: “A”
}
],
“title”: “FD usage (%)”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “s”
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 3,
“x”: 17,
“y”: 0
},
“id”: 9,
“options”: {
“colorMode”: “value”,
“graphMode”: “area”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “max(n8n_nodejs_eventloop_lag_p99_seconds{job=“n8n”}) or on() vector(0)”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Event Loop Lag P99 (s)”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “s”
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 20,
“y”: 0
},
“id”: 11,
“options”: {
“colorMode”: “value”,
“graphMode”: “area”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “time() - max(n8n_process_start_time_seconds{job=“n8n”})”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Uptime (s)”,
“type”: “stat”
},
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 2,
“x”: 0,
“y”: 3
},
“id”: 20,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“editorMode”: “code”,
“format”: “table”,
“rawQuery”: true,
“rawSql”: “SELECT date_trunc(‘day’,“startedAt”) AS “time”,\r\n COUNT()::bigint AS executions\r\nFROM execution_entity\r\nWHERE “startedAt” >= NOW() - INTERVAL ‘7 days’\r\n AND COALESCE(“mode”,‘regular’) <> ‘manual’\r\n AND (\r\n “status” IN (‘success’,‘error’)\r\n OR (“status” IS NULL AND “finished” IS NOT NULL)\r\n )\r\nGROUP BY 1\r\nORDER BY 1;",
“refId”: “A”,
“sql”: {
“columns”: [
{
“parameters”: [],
“type”: “function”
}
],
“groupBy”: [
{
“property”: {
“type”: “string”
},
“type”: “groupBy”
}
],
“limit”: 50
}
}
],
“title”: “Executions/day”,
“type”: “stat”
},
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“fieldConfig”: {
“defaults”: {
“mappings”: [],
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “blue”,
“value”: null
}
]
}
},
“overrides”: []
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 2,
“y”: 3
},
“id”: 16,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“editorMode”: “code”,
“format”: “table”,
“rawQuery”: true,
“rawSql”: "WITH e AS (\r\n SELECT\r\n CASE\r\n WHEN “status” IN (‘success’,‘error’) THEN “status”\r\n WHEN “status” IS NULL AND “finished” = true THEN ‘success’\r\n WHEN “status” IS NULL AND “finished” = false THEN ‘error’\r\n ELSE NULL\r\n END AS outcome\r\n FROM execution_entity\r\n WHERE “startedAt” >= NOW() - INTERVAL ‘7 days’\r\n AND COALESCE(“mode”,‘regular’) <> ‘manual’\r\n)\r\nSELECT COUNT()::bigint AS prod_executions_7d\r\nFROM e\r\nWHERE outcome IS NOT NULL;”,
“refId”: “A”,
“sql”: {
“columns”: [
{
“parameters”: ,
“type”: “function”
}
],
“groupBy”: [
{
“property”: {
“type”: “string”
},
“type”: “groupBy”
}
],
“limit”: 50
}
}
],
“title”: “Prod. executions – Last 7 days”,
“type”: “stat”
},
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 6,
“y”: 3
},
“id”: 17,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“editorMode”: “code”,
“format”: “table”,
“rawQuery”: true,
“rawSql”: “WITH e AS (\r\n SELECT\r\n CASE\r\n WHEN “status” IN (‘success’,‘error’) THEN “status”\r\n WHEN “status” IS NULL AND “finished” = true THEN ‘success’\r\n WHEN “status” IS NULL AND “finished” = false THEN ‘error’\r\n ELSE NULL\r\n END AS outcome\r\n FROM execution_entity\r\n WHERE “startedAt” >= NOW() - INTERVAL ‘7 days’\r\n AND COALESCE(“mode”,‘regular’) <> ‘manual’\r\n)\r\nSELECT COUNT()::bigint AS failed_prod_7d\r\nFROM e\r\nWHERE outcome = ‘error’;",
“refId”: “A”,
“sql”: {
“columns”: [
{
“parameters”: [],
“type”: “function”
}
],
“groupBy”: [
{
“property”: {
“type”: “string”
},
“type”: “groupBy”
}
],
“limit”: 50
}
}
],
“title”: “Failed prod. executions – Last 7 days”,
“type”: “stat”
},
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“fieldConfig”: {
“defaults”: {
“mappings”: [],
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “light-orange”,
“value”: null
},
{
“color”: “super-light-purple”,
“value”: 50
},
{
“color”: “dark-red”,
“value”: 80
}
]
}
},
“overrides”: []
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 10,
“y”: 3
},
“id”: 18,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“editorMode”: “code”,
“format”: “table”,
“rawQuery”: true,
“rawSql”: "WITH e AS (\r\n SELECT\r\n CASE\r\n WHEN “status” IN (‘success’,‘error’) THEN “status”\r\n WHEN “status” IS NULL AND “finished” = true THEN ‘success’\r\n WHEN “status” IS NULL AND “finished” = false THEN ‘error’\r\n ELSE NULL\r\n END AS outcome\r\n FROM execution_entity\r\n WHERE “startedAt” >= NOW() - INTERVAL ‘7 days’\r\n AND COALESCE(“mode”,‘regular’) <> ‘manual’\r\n),\r\nagg AS (\r\n SELECT\r\n COUNT() AS total_done,\r\n COUNT(*) FILTER (WHERE outcome = ‘error’) AS failed\r\n FROM e\r\n WHERE outcome IS NOT NULL\r\n)\r\nSELECT ROUND(100.0 * failed / NULLIF(total_done, 0), 2) AS failure_rate_pct\r\nFROM agg;”,
“refId”: “A”,
“sql”: {
“columns”: [
{
“parameters”: ,
“type”: “function”
}
],
“groupBy”: [
{
“property”: {
“type”: “string”
},
“type”: “groupBy”
}
],
“limit”: 50
}
}
],
“title”: “Failure rate – Last 7 days (%)”,
“type”: “stat”
},
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 4,
“x”: 14,
“y”: 3
},
“id”: 19,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“datasource”: {
“type”: “grafana-postgresql-datasource”,
“uid”: “bexilgs49ik8wa”
},
“editorMode”: “code”,
“format”: “table”,
“rawQuery”: true,
“rawSql”: “SELECT ROUND(AVG(EXTRACT(EPOCH FROM (“stoppedAt” - “startedAt”))), 2) AS avg_runtime_seconds\r\nFROM execution_entity\r\nWHERE “startedAt” >= NOW() - INTERVAL ‘7 days’\r\n AND COALESCE(“mode”,‘regular’) <> ‘manual’\r\n AND “stoppedAt” IS NOT NULL\r\n AND (\r\n “status” IN (‘success’,‘error’)\r\n OR (“status” IS NULL AND “finished” IS NOT NULL)\r\n );”,
“refId”: “A”,
“sql”: {
“columns”: [
{
“parameters”: ,
“type”: “function”
}
],
“groupBy”: [
{
“property”: {
“type”: “string”
},
“type”: “groupBy”
}
],
“limit”: 50
}
}
],
“title”: “Run time (avg.) – Last 7 days”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “yellow”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 3,
“x”: 18,
“y”: 3
},
“id”: 3,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “sum(n8n_scaling_mode_queue_jobs_waiting{job=“n8n”}) or on() vector(0)”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Queue Waiting”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 3,
“w”: 3,
“x”: 21,
“y”: 3
},
“id”: 4,
“options”: {
“colorMode”: “value”,
“graphMode”: “none”,
“justifyMode”: “auto”,
“orientation”: “auto”,
“reduceOptions”: {
“calcs”: [
“lastNotNull”
],
“fields”: “”,
“values”: false
},
“showPercentChange”: false,
“textMode”: “value”,
“wideLayout”: true
},
“pluginVersion”: “10.4.6”,
“targets”: [
{
“expr”: “sum(n8n_scaling_mode_queue_jobs_active{job=“n8n”}) or on() vector(0)”,
“instant”: true,
“refId”: “A”
}
],
“title”: “Queue Active”,
“type”: “stat”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“color”: {
“mode”: “palette-classic”
},
“custom”: {
“axisBorderShow”: false,
“axisCenteredZero”: false,
“axisColorMode”: “text”,
“axisLabel”: “”,
“axisPlacement”: “auto”,
“barAlignment”: 0,
“drawStyle”: “line”,
“fillOpacity”: 0,
“gradientMode”: “none”,
“hideFrom”: {
“legend”: false,
“tooltip”: false,
“viz”: false
},
“insertNulls”: false,
“lineInterpolation”: “linear”,
“lineWidth”: 1,
“pointSize”: 5,
“scaleDistribution”: {
“type”: “linear”
},
“showPoints”: “auto”,
“spanNulls”: false,
“stacking”: {
“group”: “A”,
“mode”: “none”
},
“thresholdsStyle”: {
“mode”: “off”
}
},
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “s”
},
“overrides”:
},
“gridPos”: {
“h”: 8,
“w”: 24,
“x”: 0,
“y”: 6
},
“id”: 5,
“options”: {
“legend”: {
“calcs”: ,
“displayMode”: “list”,
“placement”: “bottom”,
“showLegend”: true
},
“tooltip”: {
“mode”: “single”,
“sort”: “none”
}
},
“targets”: [
{
“expr”: “sum(rate(n8n_process_cpu_seconds_total{job=“n8n”}[5m])) or on() vector(0)”,
“instant”: false,
“legendFormat”: “cpu s/s”,
“refId”: “A”
}
],
“title”: “CPU (user+system) rate 5m”,
“type”: “timeseries”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“color”: {
“mode”: “palette-classic”
},
“custom”: {
“axisBorderShow”: false,
“axisCenteredZero”: false,
“axisColorMode”: “text”,
“axisLabel”: “”,
“axisPlacement”: “auto”,
“barAlignment”: 0,
“drawStyle”: “line”,
“fillOpacity”: 0,
“gradientMode”: “none”,
“hideFrom”: {
“legend”: false,
“tooltip”: false,
“viz”: false
},
“insertNulls”: false,
“lineInterpolation”: “linear”,
“lineWidth”: 1,
“pointSize”: 5,
“scaleDistribution”: {
“type”: “linear”
},
“showPoints”: “auto”,
“spanNulls”: false,
“stacking”: {
“group”: “A”,
“mode”: “none”
},
“thresholdsStyle”: {
“mode”: “off”
}
},
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 6,
“w”: 12,
“x”: 0,
“y”: 14
},
“id”: 6,
“options”: {
“legend”: {
“calcs”: ,
“displayMode”: “list”,
“placement”: “bottom”,
“showLegend”: true
},
“tooltip”: {
“mode”: “single”,
“sort”: “none”
}
},
“targets”: [
{
“expr”: “sum(rate(n8n_scaling_mode_queue_jobs_completed{job=“n8n”}[5m])) or on() vector(0)”,
“instant”: false,
“legendFormat”: “completed/s”,
“refId”: “A”
}
],
“title”: “Throughput (jobs completed/s) – 5m”,
“type”: “timeseries”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“color”: {
“mode”: “palette-classic”
},
“custom”: {
“axisBorderShow”: false,
“axisCenteredZero”: false,
“axisColorMode”: “text”,
“axisLabel”: “”,
“axisPlacement”: “auto”,
“barAlignment”: 0,
“drawStyle”: “line”,
“fillOpacity”: 0,
“gradientMode”: “none”,
“hideFrom”: {
“legend”: false,
“tooltip”: false,
“viz”: false
},
“insertNulls”: false,
“lineInterpolation”: “linear”,
“lineWidth”: 1,
“pointSize”: 5,
“scaleDistribution”: {
“type”: “linear”
},
“showPoints”: “auto”,
“spanNulls”: false,
“stacking”: {
“group”: “A”,
“mode”: “none”
},
“thresholdsStyle”: {
“mode”: “off”
}
},
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 6,
“w”: 12,
“x”: 12,
“y”: 14
},
“id”: 7,
“options”: {
“legend”: {
“calcs”: ,
“displayMode”: “list”,
“placement”: “bottom”,
“showLegend”: true
},
“tooltip”: {
“mode”: “single”,
“sort”: “none”
}
},
“targets”: [
{
“expr”: “sum(rate(n8n_scaling_mode_queue_jobs_failed{job=“n8n”}[5m])) or on() vector(0)”,
“instant”: false,
“legendFormat”: “failed/s”,
“refId”: “A”
}
],
“title”: “Error rate (jobs failed/s) – 5m”,
“type”: “timeseries”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“color”: {
“mode”: “palette-classic”
},
“custom”: {
“axisBorderShow”: false,
“axisCenteredZero”: false,
“axisColorMode”: “text”,
“axisLabel”: “”,
“axisPlacement”: “auto”,
“barAlignment”: 0,
“drawStyle”: “line”,
“fillOpacity”: 0,
“gradientMode”: “none”,
“hideFrom”: {
“legend”: false,
“tooltip”: false,
“viz”: false
},
“insertNulls”: false,
“lineInterpolation”: “linear”,
“lineWidth”: 1,
“pointSize”: 5,
“scaleDistribution”: {
“type”: “linear”
},
“showPoints”: “auto”,
“spanNulls”: false,
“stacking”: {
“group”: “A”,
“mode”: “none”
},
“thresholdsStyle”: {
“mode”: “off”
}
},
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “s”
},
“overrides”:
},
“gridPos”: {
“h”: 7,
“w”: 12,
“x”: 0,
“y”: 20
},
“id”: 12,
“options”: {
“legend”: {
“calcs”: ,
“displayMode”: “list”,
“placement”: “bottom”,
“showLegend”: true
},
“tooltip”: {
“mode”: “single”,
“sort”: “none”
}
},
“targets”: [
{
“expr”: “sum(rate(n8n_nodejs_gc_duration_seconds_sum{job=“n8n”,kind=“major”}[5m])) / sum(rate(n8n_nodejs_gc_duration_seconds_count{job=“n8n”,kind=“major”}[5m]))”,
“instant”: false,
“legendFormat”: “major avg”,
“refId”: “A”
},
{
“expr”: “sum(rate(n8n_nodejs_gc_duration_seconds_sum{job=“n8n”,kind=“minor”}[5m])) / sum(rate(n8n_nodejs_gc_duration_seconds_count{job=“n8n”,kind=“minor”}[5m]))”,
“instant”: false,
“legendFormat”: “minor avg”,
“refId”: “B”
},
{
“expr”: “sum(rate(n8n_nodejs_gc_duration_seconds_sum{job=“n8n”,kind=“incremental”}[5m])) / sum(rate(n8n_nodejs_gc_duration_seconds_count{job=“n8n”,kind=“incremental”}[5m]))”,
“instant”: false,
“legendFormat”: “incremental avg”,
“refId”: “C”
}
],
“title”: “GC avg duration by kind (5m)”,
“type”: “timeseries”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“color”: {
“mode”: “palette-classic”
},
“custom”: {
“axisBorderShow”: false,
“axisCenteredZero”: false,
“axisColorMode”: “text”,
“axisLabel”: “”,
“axisPlacement”: “auto”,
“barAlignment”: 0,
“drawStyle”: “line”,
“fillOpacity”: 0,
“gradientMode”: “none”,
“hideFrom”: {
“legend”: false,
“tooltip”: false,
“viz”: false
},
“insertNulls”: false,
“lineInterpolation”: “linear”,
“lineWidth”: 1,
“pointSize”: 5,
“scaleDistribution”: {
“type”: “linear”
},
“showPoints”: “auto”,
“spanNulls”: false,
“stacking”: {
“group”: “A”,
“mode”: “none”
},
“thresholdsStyle”: {
“mode”: “off”
}
},
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”,
“value”: null
},
{
“color”: “red”,
“value”: 80
}
]
}
},
“overrides”:
},
“gridPos”: {
“h”: 7,
“w”: 12,
“x”: 12,
“y”: 20
},
“id”: 13,
“options”: {
“legend”: {
“calcs”: ,
“displayMode”: “list”,
“placement”: “bottom”,
“showLegend”: true
},
“tooltip”: {
“mode”: “single”,
“sort”: “none”
}
},
“targets”: [
{
“expr”: “sum(rate(n8n_nodejs_gc_duration_seconds_count{job=“n8n”,kind=“major”}[5m]))”,
“instant”: false,
“legendFormat”: “major”,
“refId”: “A”
},
{
“expr”: “sum(rate(n8n_nodejs_gc_duration_seconds_count{job=“n8n”,kind=“minor”}[5m]))”,
“instant”: false,
“legendFormat”: “minor”,
“refId”: “B”
},
{
“expr”: “sum(rate(n8n_nodejs_gc_duration_seconds_count{job=“n8n”,kind=“incremental”}[5m]))”,
“instant”: false,
“legendFormat”: “incremental”,
“refId”: “C”
}
],
“title”: “GC ops/sec by kind (5m)”,
“type”: “timeseries”
},
{
“datasource”: {
“type”: “prometheus”,
“uid”: “fexiz7ad9tfcwc”
},
“fieldConfig”: {
“defaults”: {
“color”: {
“mode”: “palette-classic”
},
“custom”: {
“axisBorderShow”: false,
“axisCenteredZero”: false,
“axisColorMode”: “text”,
“axisLabel”: “”,
“axisPlacement”: “auto”,
“barAlignment”: 0,
“drawStyle”: “line”,
“fillOpacity”: 0,
“gradientMode”: “none”,
“hideFrom”: {
“legend”: false,
“tooltip”: false,
“viz”: false
},
“insertNulls”: false,
“lineInterpolation”: “linear”,
“lineWidth”: 1,
“pointSize”: 5,
“scaleDistribution”: {
“type”: “linear”
},
“showPoints”: “auto”,
“spanNulls”: false,
“stacking”: {
“group”: “A”,
“mode”: “none”
},
“thresholdsStyle”: {
“mode”: “off”
}
},
“mappings”: ,
“thresholds”: {
“mode”: “absolute”,
“steps”: [
{
“color”: “green”
},
{
“color”: “red”,
“value”: 80
}
]
},
“unit”: “bytes”
},
“overrides”:
},
“gridPos”: {
“h”: 6,
“w”: 24,
“x”: 0,
“y”: 27
},
“id”: 14,
“options”: {
“legend”: {
“calcs”: ,
“displayMode”: “list”,
“placement”: “bottom”,
“showLegend”: true
},
“tooltip”: {
“mode”: “single”,
“sort”: “none”
}
},
“targets”: [
{
“expr”: “sum(n8n_nodejs_heap_size_used_bytes{job=“n8n”})”,
“instant”: false,
“legendFormat”: “heap used”,
“refId”: “A”
},
{
“expr”: “sum(n8n_nodejs_heap_size_total_bytes{job=“n8n”})”,
“instant”: false,
“legendFormat”: “heap total”,
“refId”: “B”
}
],
“title”: “Heap Used vs Total”,
“type”: “timeseries”
}
],
“refresh”: “1h”,
“schemaVersion”: 39,
“tags”: [
“n8n”,
“queue”,
“ops”
],
“templating”: {
“list”:
},
“time”: {
“from”: “now-1h”,
“to”: “now”
},
“timepicker”: {},
“timezone”: “”,
“title”: “n8n Queue Mode - Core Monitoring”,
“uid”: “eexjd5bayrif4d”,
“version”: 8,
“weekStart”: “”
}