node:internal/process/promises:265
triggerUncaughtException(err, true /* fromPromise */);
^
Error: This socket has been ended by the other party
at Socket.writeAfterFIN [as write] (node:net:474:14)
at JSStreamSocket.doWrite (node:internal/js_stream_socket:175:19)
at JSStream.onwrite (node:internal/js_stream_socket:33:57)
at TLSSocket.Socket._final (node:net:443:28)
at callFinal (node:internal/streams/writable:694:27)
at prefinish (node:internal/streams/writable:723:7)
at finishMaybe (node:internal/streams/writable:733:5)
at TLSSocket.Writable.end (node:internal/streams/writable:631:5)
at TLSSocket.Socket.end (node:net:609:31)
at endWritableNT (node:internal/streams/readable:1372:12)
at processTicksAndRejections (node:internal/process/task_queues:82:21) {
code: 'EPIPE',
source: 'socket'
}
I have 3 active workspaces: read IMAP, Telegram(webhook) and Execute Command (bash).
Workflow Executions filtered with errors don’t helps to find problem by time of restart container. Last error was two days ago.
I’ve got a similar error. My self-hosted n8n is restarting every 3-5 minutes. And I also use the EmailReadImap node as a trigger. Actually, the error seems to origin there. This is my log that always looks like this before a restart:
2022-05-16T15:30:33.541Z | debug | Received child process message of type processHook for execution ID 113026. {"executionId":"113026","file":"WorkflowRunner.js"}
2022-05-16T15:30:33.542Z | debug | Executing hook (hookFunctionsSave) {"executionId":"113026","workflowId":14,"file":"WorkflowExecuteAdditionalData.js","function":"workflowExecuteAfter"}
2022-05-16T15:30:33.543Z | debug | Save execution data to database for execution ID 113026 {"executionId":"113026","workflowId":14,"finished":true,"stoppedAt":"2022-05-16T15:30:33.539Z","file":"WorkflowExecuteAdditionalData.js","function":"workflowExecuteAfter"}
2022-05-16T15:30:33.548Z | debug | Received child process message of type end for execution ID 113026. {"executionId":"113026","file":"WorkflowRunner.js"}
2022-05-16T15:30:33.552Z | debug | Executing hook (hookFunctionsPush) {"executionId":"113026","workflowId":14,"file":"WorkflowExecuteAdditionalData.js","function":"workflowExecuteAfter"}
2022-05-16T15:31:27.377Z | debug | Wait tracker querying database for waiting executions {"file":"WaitTracker.js","function":"getwaitingExecutions"}
2022-05-16T15:32:24.589Z | verbose | IMAP connection was reset - reconnecting. {"file":"EmailReadImap.node.js"}
2022-05-16T15:32:25.755Z | debug | Querying for new messages on node "EmailReadImap" {"searchCriteria":["UNSEEN",["UID","10661:*"]],"file":"EmailReadImap.node.js","function":"onmail"}
node:internal/process/promises:279
triggerUncaughtException(err, true /* fromPromise */);
^
Error: read ECONNRESET
at TCP.onStreamRead (node:internal/stream_base_commons:217:20) {
errno: -104,
code: 'ECONNRESET',
syscall: 'read',
source: 'socket'
}
2022-05-16T15:32:35.932Z | info | Initializing n8n process {"file":"start.js"}
Looking into the code, I cannot definitely say at what place the error happens, but it seems like there’s a uncaught promise rejection or something like that.
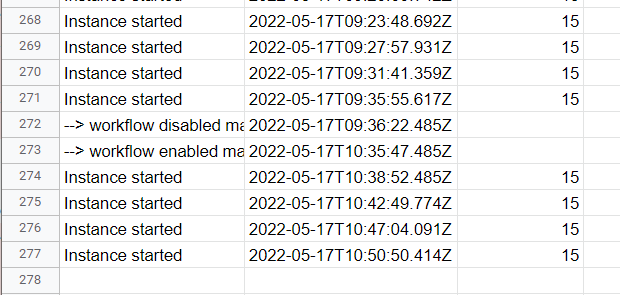
I’ve had the workflow disabled for an hour now. While it was disabled, there were no restarts. Aber re-enabling the workflow, it began to restart again:
Thanks for confirming both of you. Tbh, I don’t quite know what might cause this (I did even set up a test imap server on my end and killed it, have it join and leave my network for a few hours today, but n8n just wouldn’t crash)
I’ll add this to our bug tracker for a closer look by our engineering team though, hopefully they have some better idea of what might be going on.
Just a wild guess, but I want to share my observation…
I found these lines in [email protected] (notice the comment in L34):
In n8n’s EmailReadImap node you’re calling connection.end() in multiple occasions and also have an error event handling…
…but that’s without the check whether it was ended purposely. Also, I don’t know if it is correct to throw an error, even if the connection was successfully reconnected.