Hello all,
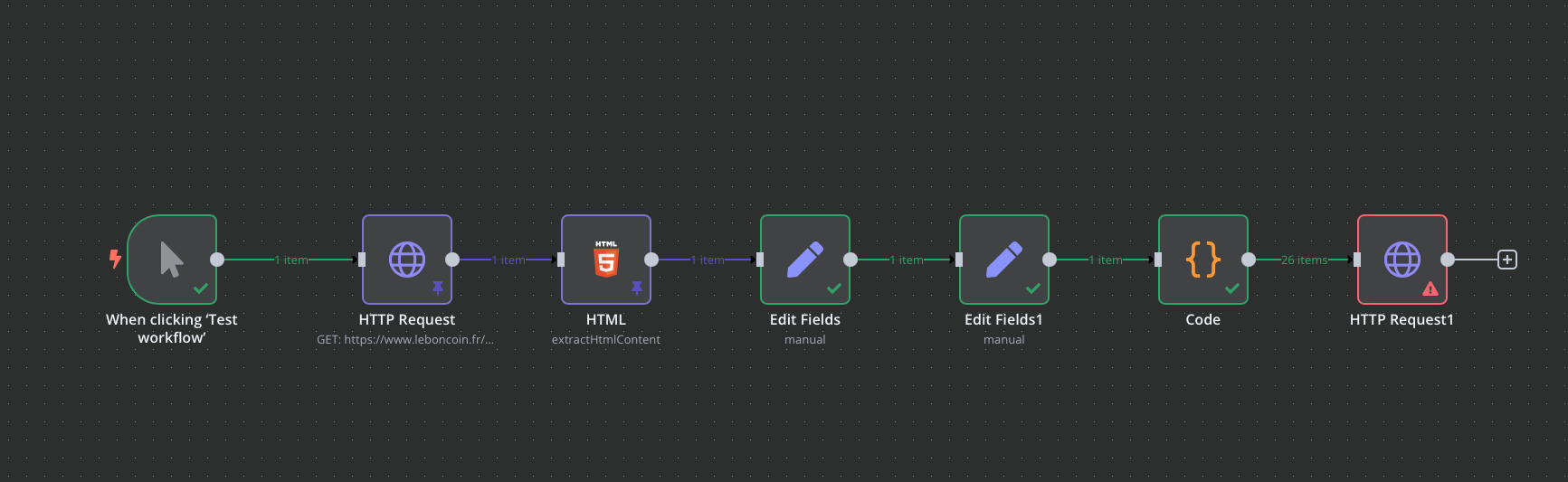
I’m new to n8n. I’m trying to make a request on the leboncoin.fr website.
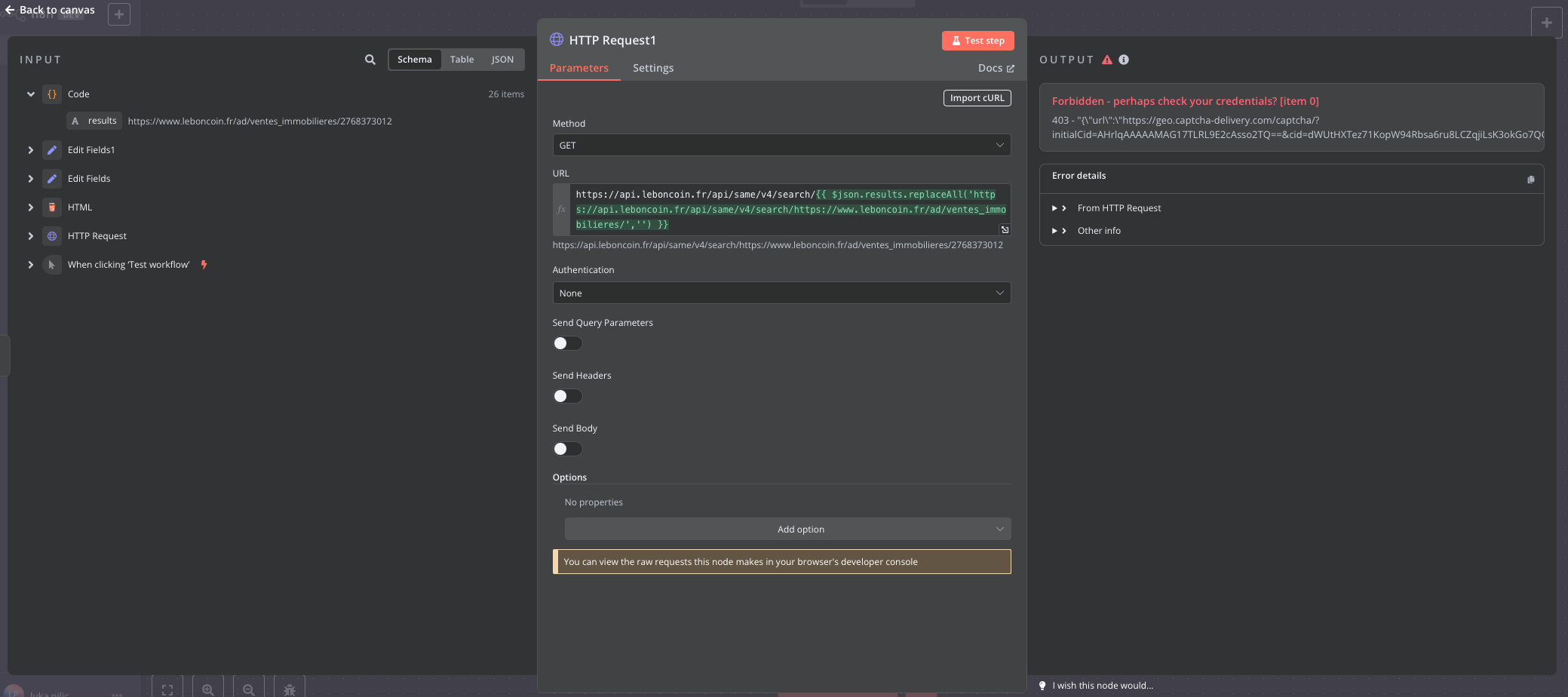
I’m stuck on a dynamic captcha on the site. I installed puppeteer on n8n and after several unsuccessful attempts it still doesn’t work. Do you have any ideas on how to do this? Have other people succeeded on a similar subject?
For the more curious, my goal is to do several filtered searches to find a house to buy in different areas, to retrieve the links according to these criteria on a google sheet for example or to send it to me in the form of a newsletter.
You will latest get blocked here due to datadome protection. If you do a lot of scraping, datadome is a bigger pain in the a** than Cloudflare. You could use a service like ZenRow, BrightData, etc which offers bypassing of datadome, etc.
Usually using puppeteer (even in stealth mode) isn´t sufficient due to some checks services like data dome do (e.g. are there any audio devices, fingerprinting etc)
These type of scraping integrations might work for some servers and not in others. Digital Ocean might work for a while, then need a proxy while AWS could simply not work. If it’s something you can spend a bit more on, try firecrawl!
[EN]
I’ve made good progress.
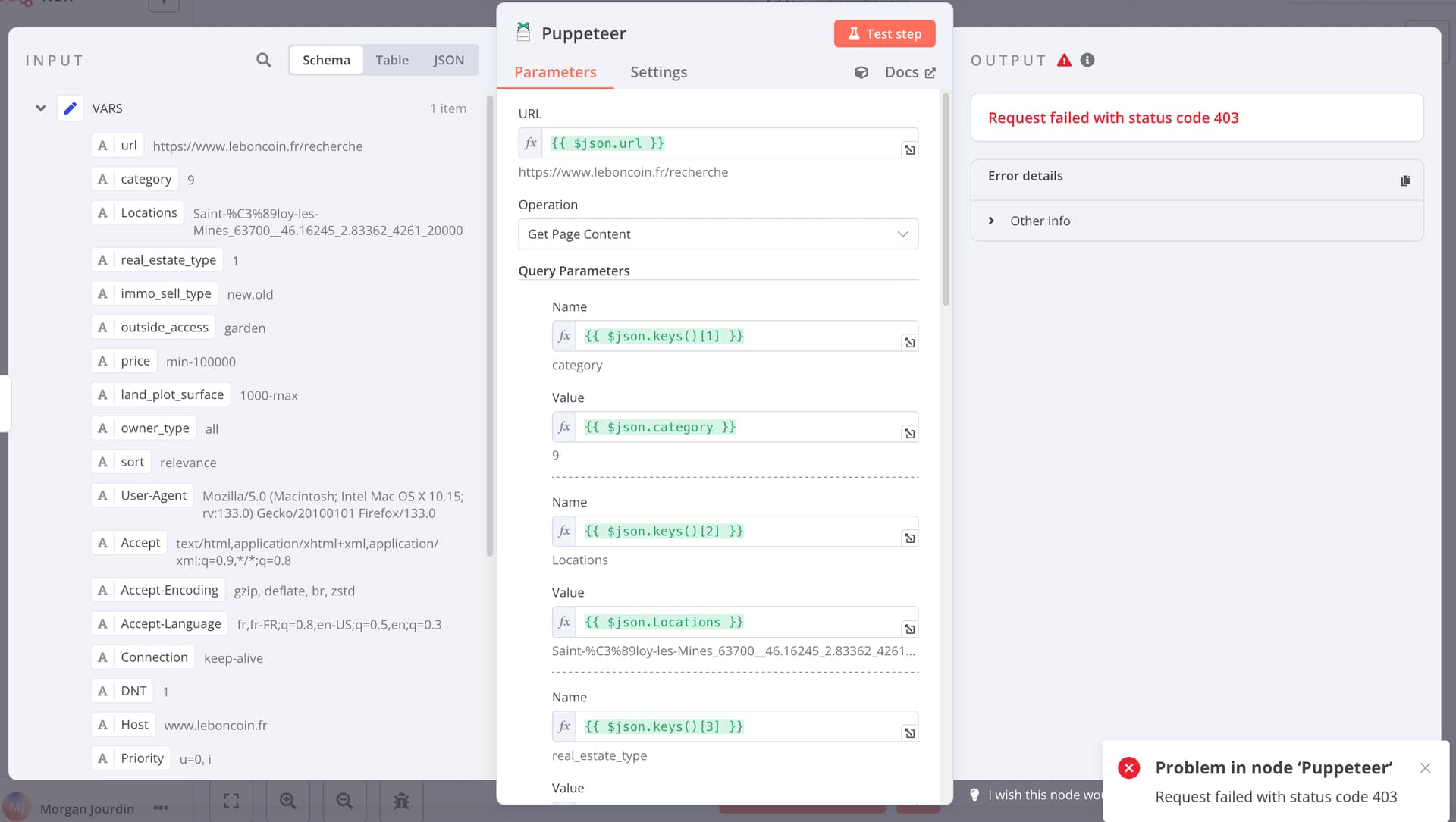
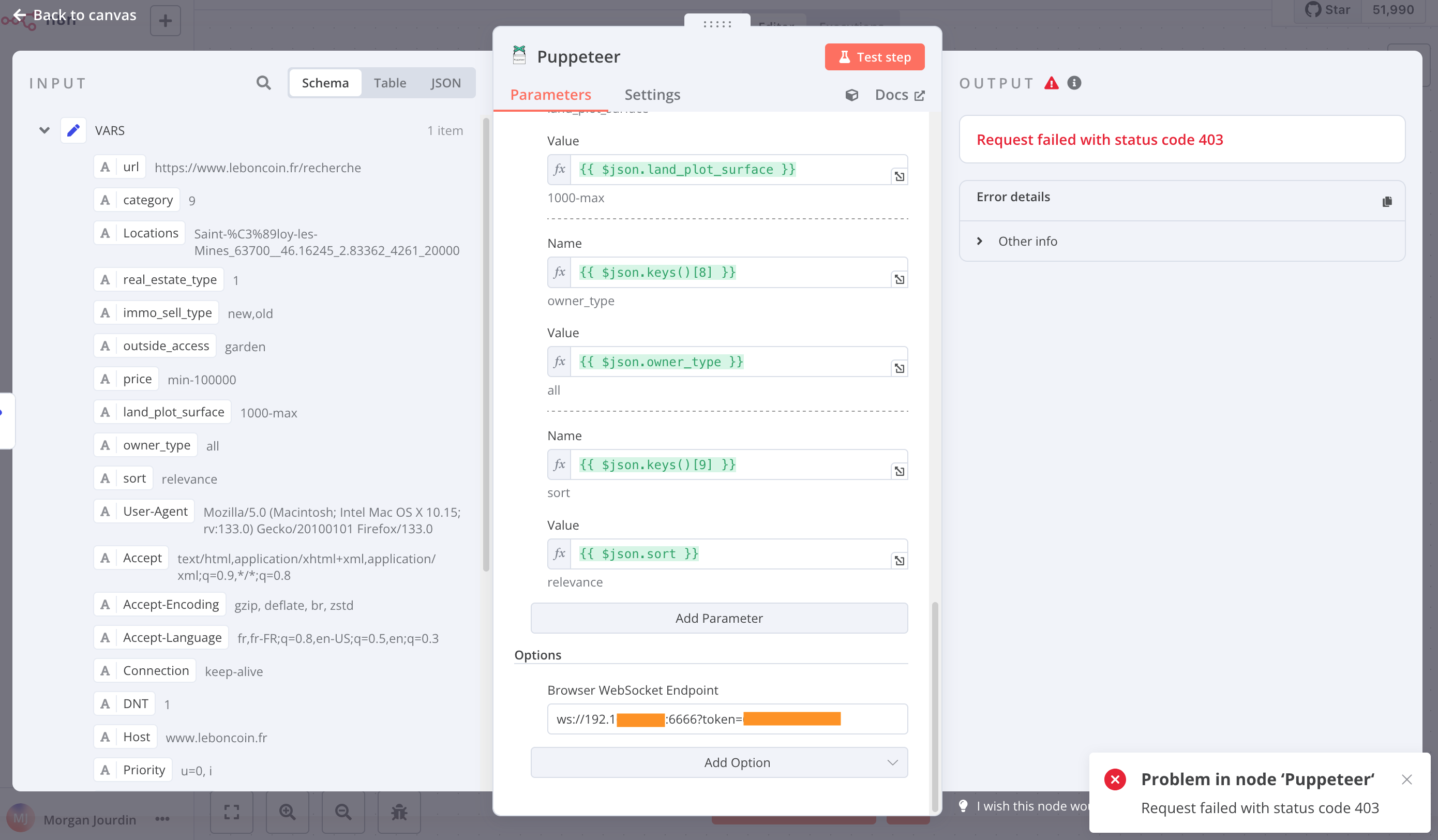
I manage to get to the site once and then I’m blocked. I understand that the captcha blocks the IP for a few hours.
As I need to go there once a day, that’s fine.
There’s a detection on the User-Agent. I created a docker instance with browserless then I put it in Browser WebSocket Endpoint in Puppeteer
[FR]
J’ai bien avancé.
J’arrive à me rendre sur le site une fois puis je suis bloqué. J’ai compris que le captcha bloquait l’IP pendant quelques heures.
Comme j’ai besoin de m’y rendre une fois par jour ca me va.
Il y a une detection sur le User-Agent.
J’ai également créé une instance docker avec browserless puis je l’ai mis dans Browser WebSocket Endpoint de Puppeteer