We’re currently leveraging n8n at scale for both batch and real-time data processing, and we’d appreciate your guidance on a few architectural and performance-related considerations we’re encountering in production-like workloads.
Below is a high-level overview of our use cases and the specific challenges where we’d value your insights:
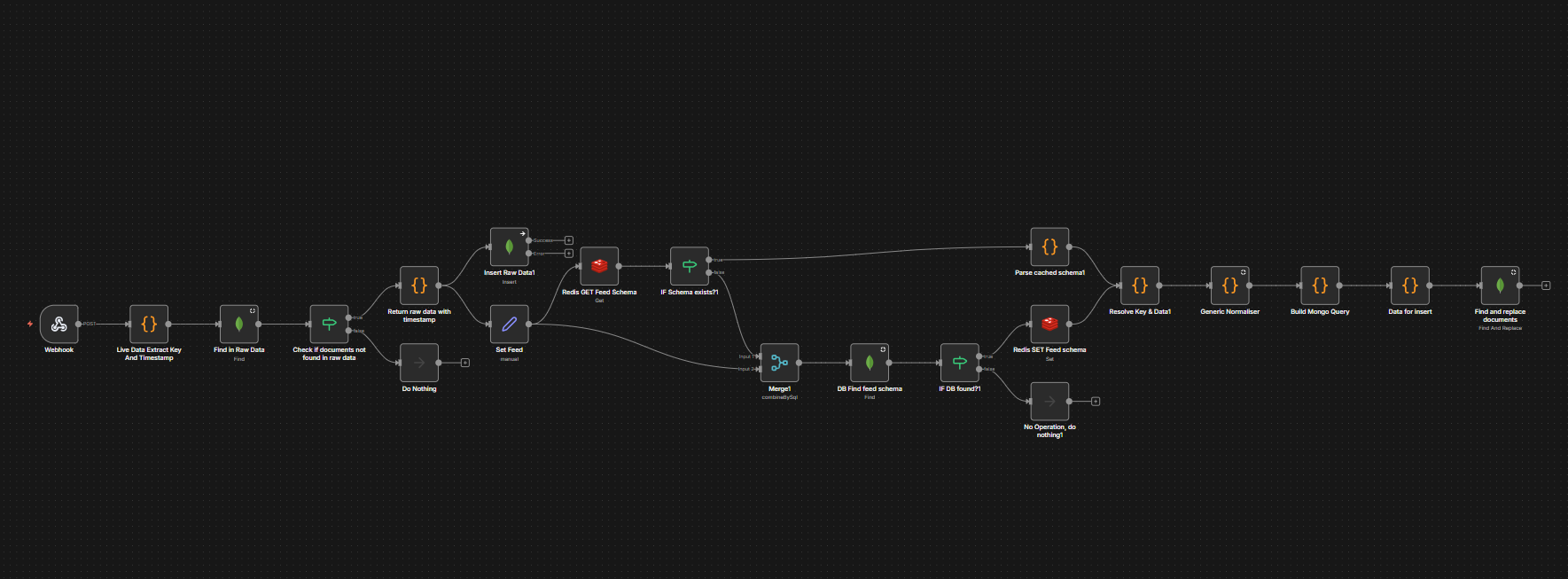
1. High-Volume Data Normalization & Deduplication
We have multiple workflows responsible for:
· Pulling data from external data sources
· Normalising the payloads
· Performing deduplication logic
· Persisting the final data into MongoDB
While we are already:
· Using bulk inserts
· Processing data in controlled batches
…we are still observing long execution times for some workflows.
Key question:
Are there recommended workflow patterns, node configurations, or architectural best practices in n8n to optimise large-scale normalisation and deduplication workloads beyond batching and bulk writes?
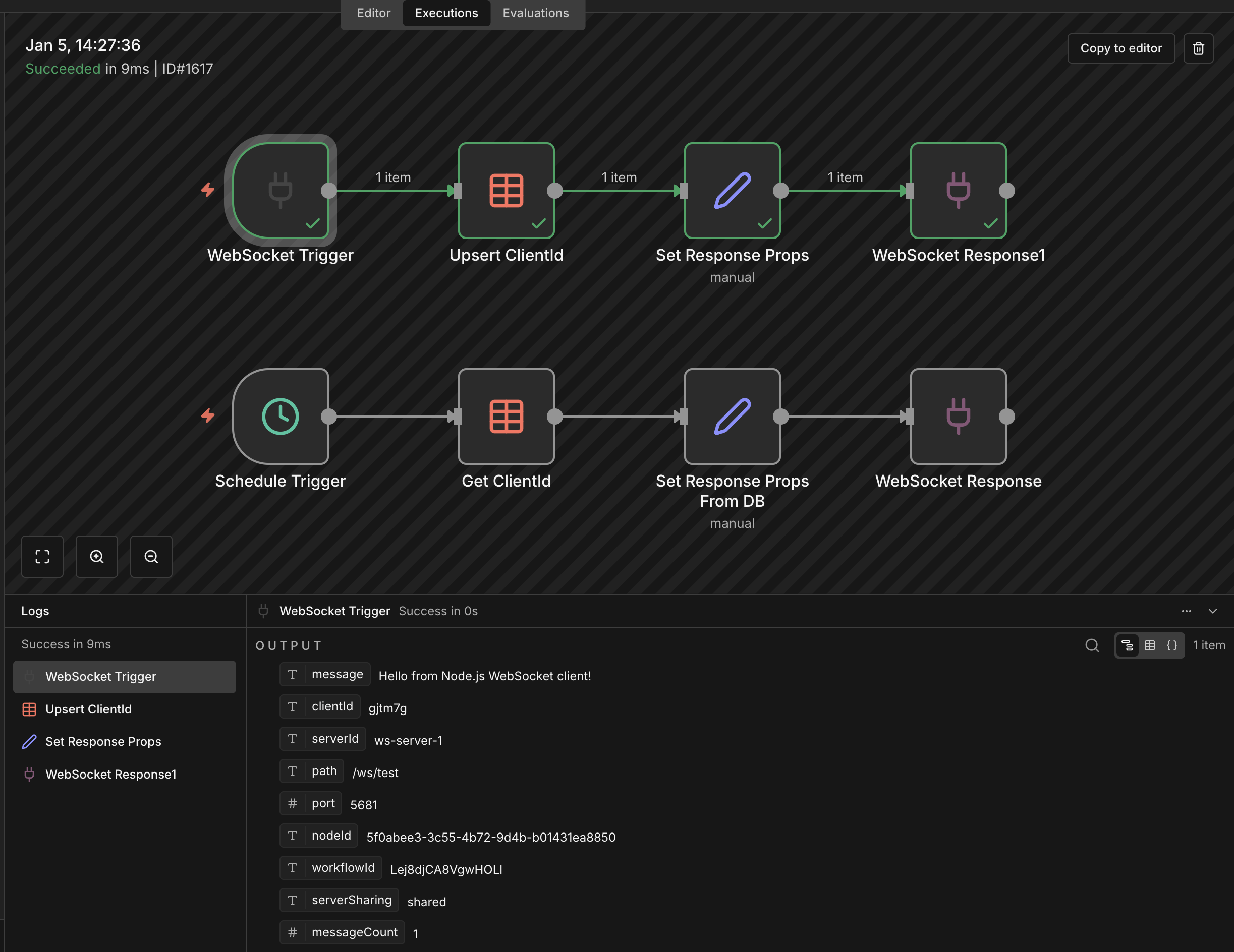
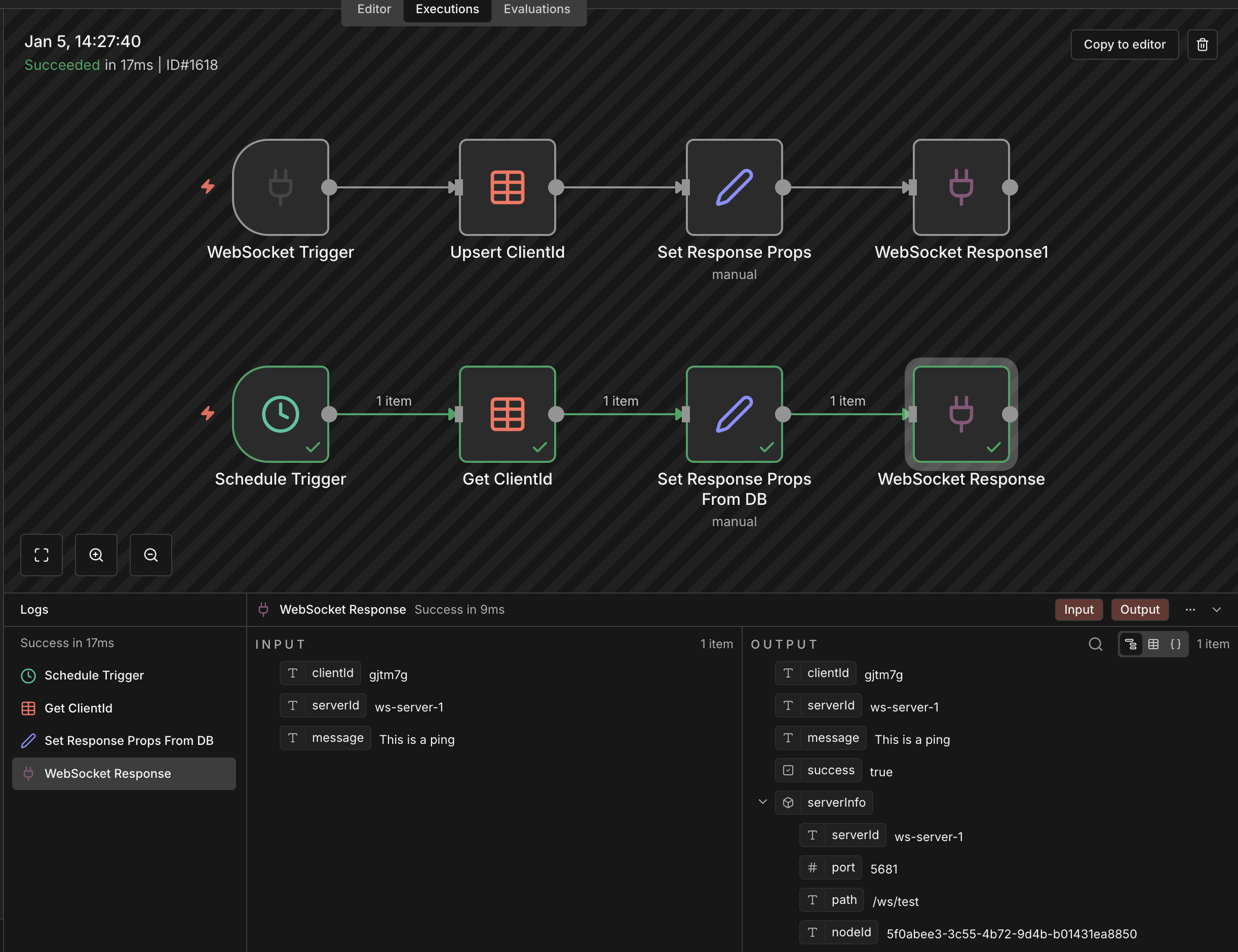
2. WebSocket-Based Live Data & Latency
We also operate real-time workflows driven by WebSocket feeds.
In certain scenarios, even for a single incoming event, we’ve observed:
· End-to-end processing delays of up to ~13 seconds
Key question:
Are there known bottlenecks or best practices when using n8n with WebSockets to minimise latency—especially for near-real-time event processing?
3. Handling High-Frequency Data Streams
Some of our incoming data streams are:
· High-frequency
· Time-sensitive
· Continuous in nature
Key question:
What is the recommended approach in n8n for:
· Maintaining performance under high-frequency event loads?
· Horizontally or vertically scaling such workflows?
Are there patterns where n8n should primarily orchestrate rather than process every event synchronously?
4. Large Batch Inserts Taking >2 Minutes
In some cases, when inserting very large datasets into MongoDB (even in batches), workflows are taking 2+ minutes to complete.
Key question:
Are there any known n8n-level limits, execution time thresholds, or configuration optimisations (execution mode, queue mode, worker setup, etc.) that could help reduce execution time for large batch operations?
5. Redis for Frequently Accessed Data
We are already using Redis to cache frequently accessed data and reduce DB load.
Key question:
Are there recommended n8n patterns or anti-patterns when integrating Redis for:
· Caching
· Deduplication
· Rate-limiting
· High-throughput workflows?
What We’re Looking For
We’re primarily seeking:
· Best-practice architectural guidance
· Scaling recommendations
· Performance optimisation strategies
· Any real-world references or examples where n8n is used at similar scale