Hello everyone,
I have a problem on N8N, when my process runs with more than 12,000 rows of data already using split in batch, also the node call workflow id, my server bug, there is the error if the figure, also I can no longer access my server until two hours later.
URL : N8N SERVER 502 Bad Gateway error
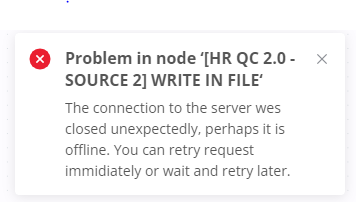
The node [HR QC 2.0 - SOURCE 2] WRITE IN FILE takes over 50 minutes to complete
Can you help me?
Thanks.
.env
QUEUE_BULL_REDIS_HOST=redis
COMPOSE_HTTP_TIMEOUT=3600
Set the logging level to ‘debug’
N8N_LOG_LEVEL=debug
Set log output to both console
N8N_LOG_OUTPUT=console
Set a 50 MB maximum size for each log file
N8N_LOG_FILE_MAXSIZE=500
EXECUTIONS_DATA_SAVE_ON_ERROR=all
EXECUTIONS_DATA_SAVE_ON_PROGRESS=false
EXECUTIONS_DATA_SAVE_ON_SUCCESS=none
EXECUTIONS_DATA_SAVE_MANUAL_EXECUTIONS=false
EXECUTIONS_DATA_PRUNE=true
EXECUTIONS_DATA_MAX_AGE=168
EXECUTIONS_DATA_PRUNE_MAX_COUNT=50000
docker-compose.yml
version: ‘3.1’
services:
postgres:
image: postgres:11
container_name: postgres
restart: always
ports:
- 5435:5432
env_file: - .env
volumes: - /opt/n8n-XXX/data/database/postgresql:/var/lib/postgresql/data
networks: - servernet
redis:
image: redis:6-alpine
container_name: redis
restart: always
volumes:
- redis_storage:/data
healthcheck:
test: [“CMD”, “redis-cli”, “ping”]
interval: 5s
timeout: 20s
retries: 10
mongo:
image: mongo:4.4
env_file:
- .env
ports: - “27018:27017”
networks: - servernet
volumes: - my-mongo-volume:/data
n8n:
image: n8nio/n8n:1.5.1
labels:
- io.portainer.accesscontrol.teams=developpement
restart: always
env_file: - .env
ports: - 5678:5678
extra_hosts: - “DNS.XXX.XXX:IP.XX.XXX.XXX”
links: - postgres
- redis
- mongo
labels: - traefik.enable=true
- traefik.http.routers.n8n.rule=Host(${SUBDOMAIN}.${DOMAIN_NAME})
- traefik.http.routers.n8n.tls=true
- traefik.http.routers.n8n.entrypoints=web,websecure
- traefik.http.routers.n8n.tls.certresolver=mytlschallenge
- traefik.http.middlewares.n8n.headers.SSLRedirect=true
- traefik.http.middlewares.n8n.headers.STSSeconds=315360000
- traefik.http.middlewares.n8n.headers.browserXSSFilter=true
- traefik.http.middlewares.n8n.headers.contentTypeNosniff=true
- traefik.http.middlewares.n8n.headers.forceSTSHeader=true
- traefik.http.middlewares.n8n.headers.SSLHost=${DOMAIN_NAME}
- traefik.http.middlewares.n8n.headers.STSIncludeSubdomains=true
- traefik.http.middlewares.n8n.headers.STSPreload=true
- traefik.http.routers.n8n.middlewares=n8n@docker
volumes: - /opt/n8n_XX:/home/node/
- /opt/sftp-n8n/data/uploads:/home/data
command: “start”
depends_on: - postgres
- redis
- mongo
networks: - servernet
networks:
servernet:
driver: bridge
volumes:
n8n_storage:
redis_storage:
my-mongo-volume:
external: false
Information on your n8n setup
n8n 1.8.2
Database using:Postgresql
**third-party database: Baserow
Running n8n with the execution process [own(default), main]:own
Running n8n via [Docker, npm, n8n.cloud, desktop app]:Docker