Hi all,
I’m running into a persistent issue with a workflow that processes daily sales data and updates a menu registry in a Postgres database. I’ve tried several approaches, but keep hitting a wall with memory bloat and workflow stalls. I’d appreciate any advice or best practices from the community!
Workflow Overview
-
Step 1: The workflow queries for a single day that needs processing (status
pendingorin_progress). -
Step 2: It fetches all sales for that day (typically 500–1000 items).
-
Step 3: It aggregates and processes those sales, then updates the
menu_registrytable (which only has a few hundred items total). -
Step 4: It updates a few other related tables.
-
Step 5: The workflow loops to process the next day.
The Problem
-
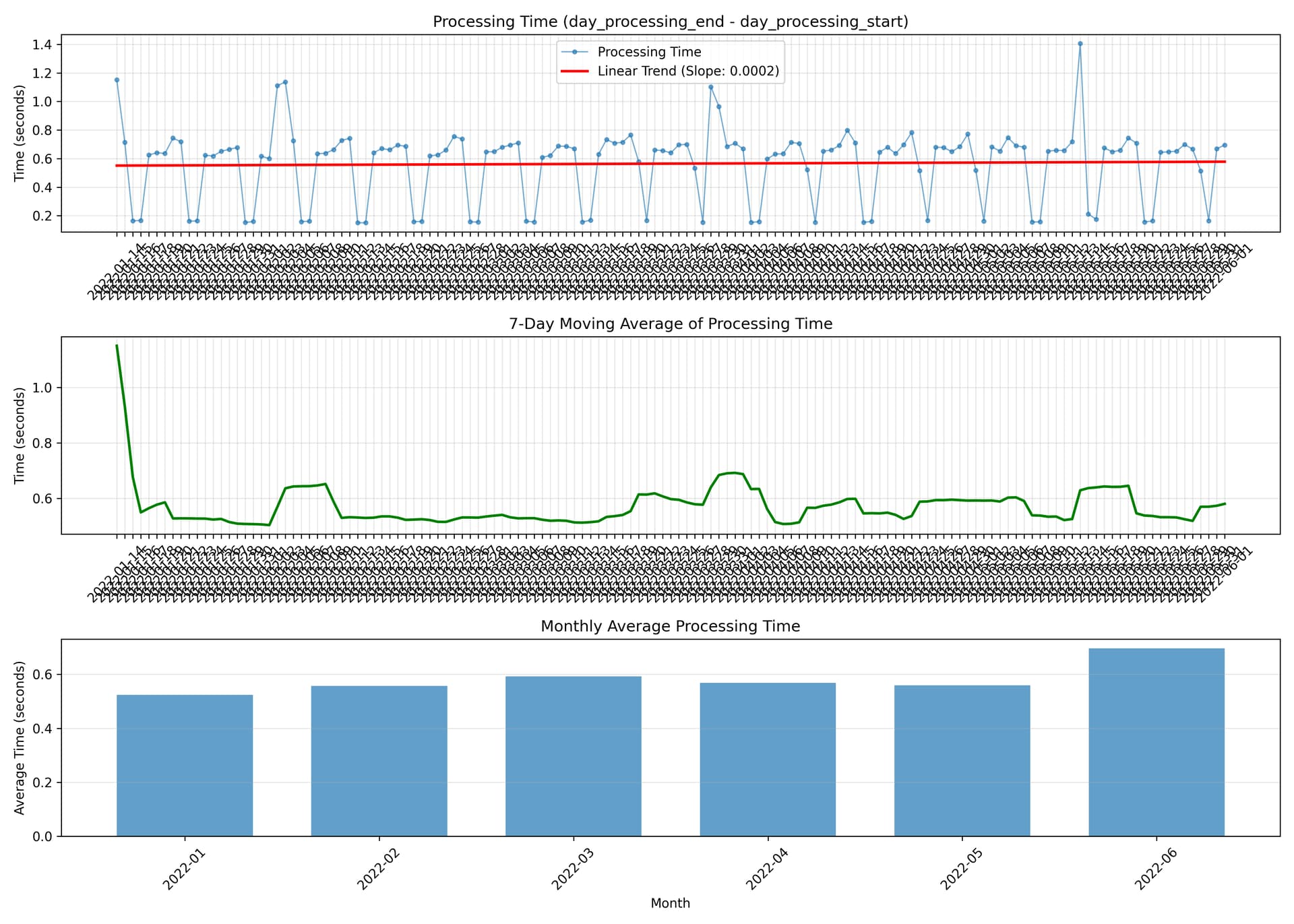
When I first start the workflow, it runs very quickly—processing 13 days the first minute. Then 7 the second. Then by minute 6 it’s only getting through 2 a minute.
-
As it continues, it slows down dramatically. Eventually, it gets stuck and can’t move to the next day.
-
I can see in the n8n UI that one node (usually after aggregation or registry update) is holding hundreds of thousands of items in memory.
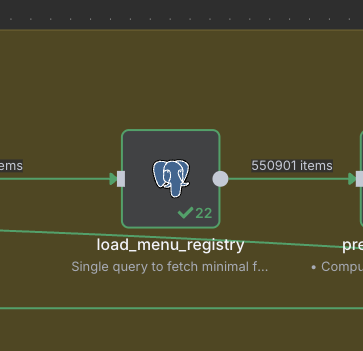
- The database itself is not growing out of control; the
menu_registrytable remains a few hundred rows.
1. Single Workflow Approach
-
The workflow loops internally, processing one day at a time.
-
Memory usage grows with each loop, even though each day’s data is small.
-
Eventually, the workflow stalls and must be killed.
2. Two-Workflow Approach
-
I split the process:
-
Orchestrator Workflow: Finds the next day to process and calls the “day processor” workflow.
-
Day Processor Workflow: Receives a date, processes that day’s sales, updates the registry and other tables.
-
The orchestrator would sometimes trigger the day processor for hundreds of days at once, causing a massive spike in executions and making the system unresponsive. I had to restart the server to recover.
What I’m Looking For
-
How can I design this workflow (or pair of workflows) so that each day is processed independently, memory is released after each day, and the system doesn’t get bogged down over time?
-
Is there a best practice for batch processing in n8n to avoid memory bloat when looping over many days?
-
How should I structure the data passing between workflows to avoid accidental accumulation?
-
Are there any workflow patterns or node configurations that can help with this scenario?
Extra Context
-
I’ve checked the database: no runaway growth or duplication.
-
The problem seems to be with how n8n accumulates items in memory as the workflow loops.
-
I’m using Postgres nodes, Code nodes, and some aggregation logic.
Any advice, examples, or references to similar issues would be greatly appreciated!
Thanks in advance,
Michael
Information on your n8n setup
- 1.91.2 self hosted
- Supabase Postgres
- Running n8n via Docker
- Ubuntu