I’m working on an n8n workflow and facing two issues that I need help with:
Importing a Microsoft Word File (.docx) & Passing it to an Agent
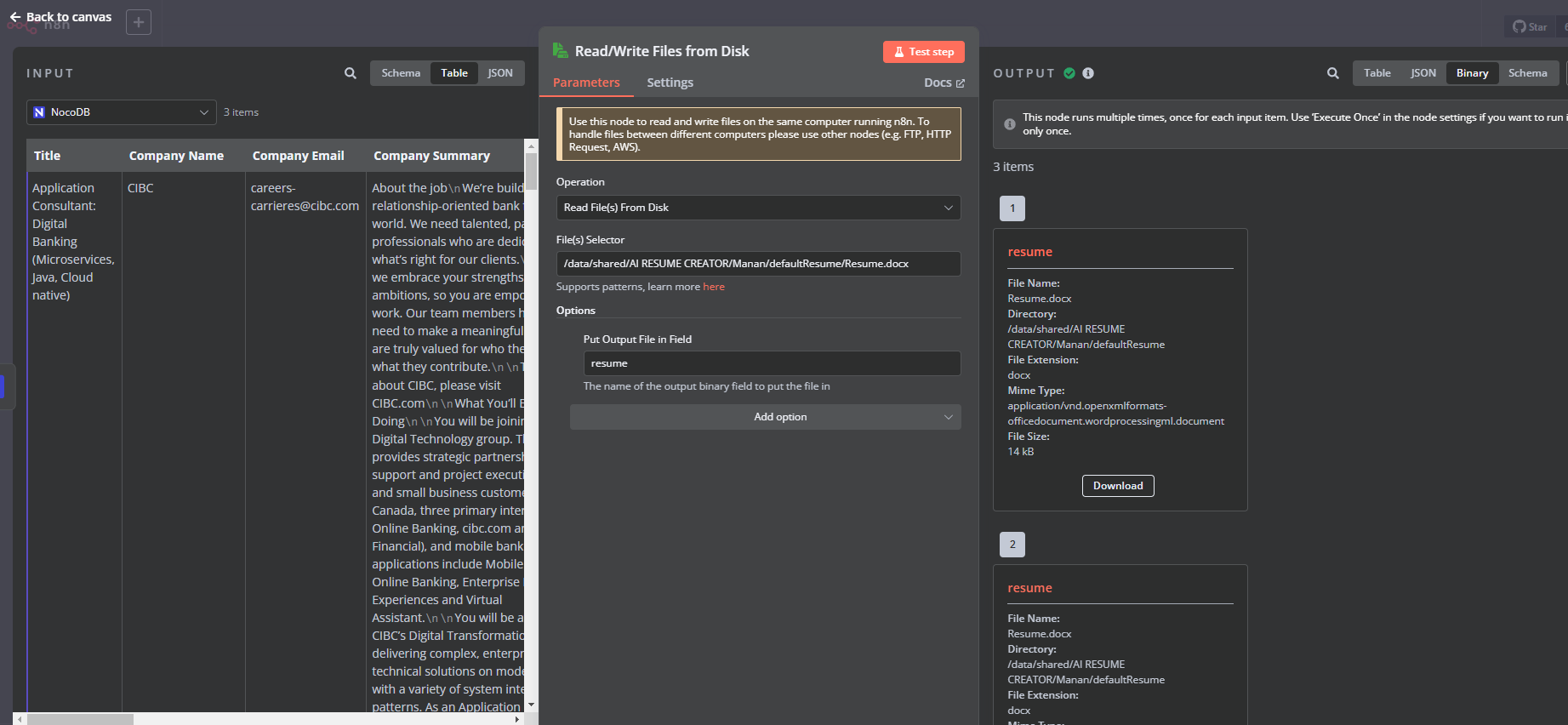
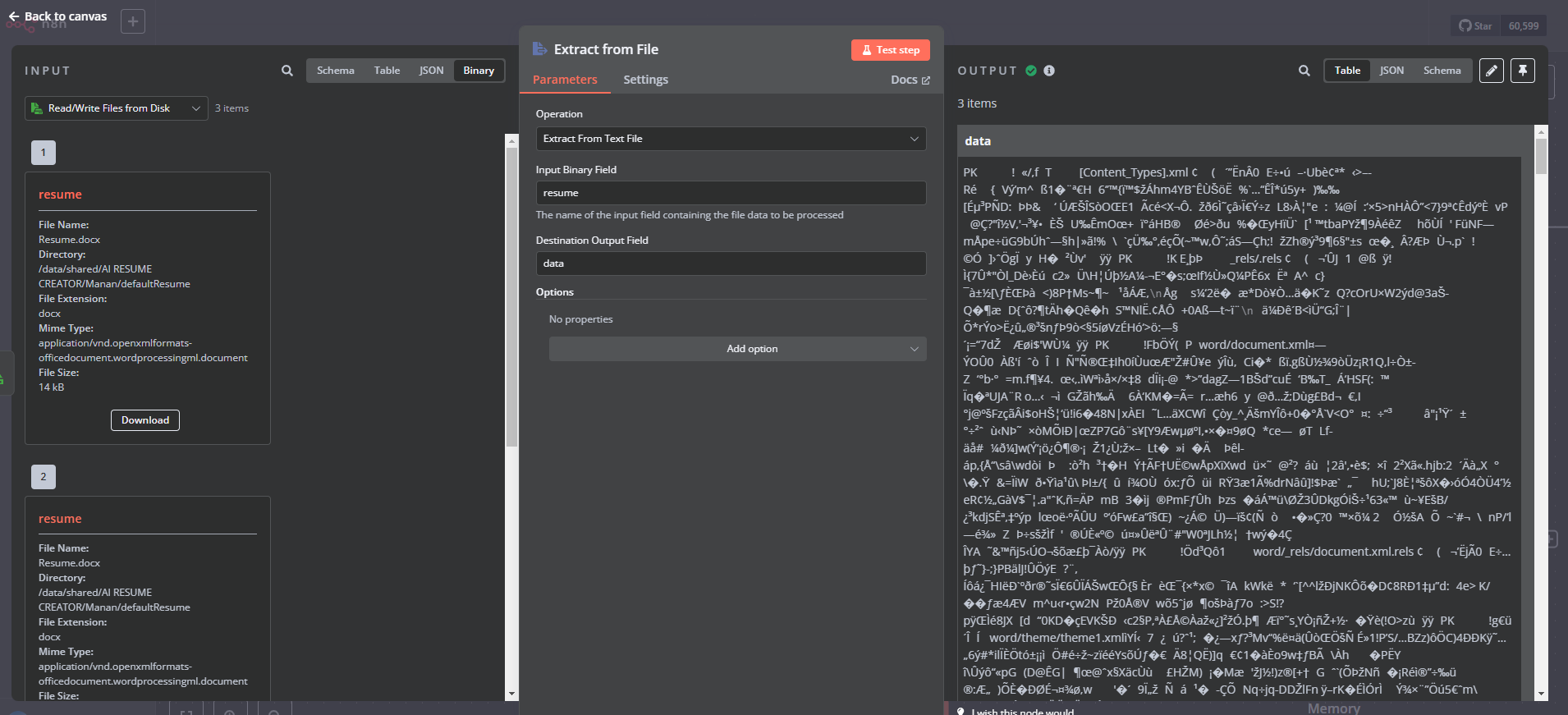
I am trying to import a .docx file, extract the text, and pass it to an AI agent. However, instead of readable text, I am getting random characters or gibberish output.
Using the Read Binary File node and converting it to text.
Using a Function node to process it.
Attempting to extract text properly but getting an incorrect format.
Have also used encoding utf-8, utf-16 but nothing works
How can I properly extract text from a Word file and pass it to my agent?
LLM Chain (Groq - DeepSeek) Not Returning Full Text
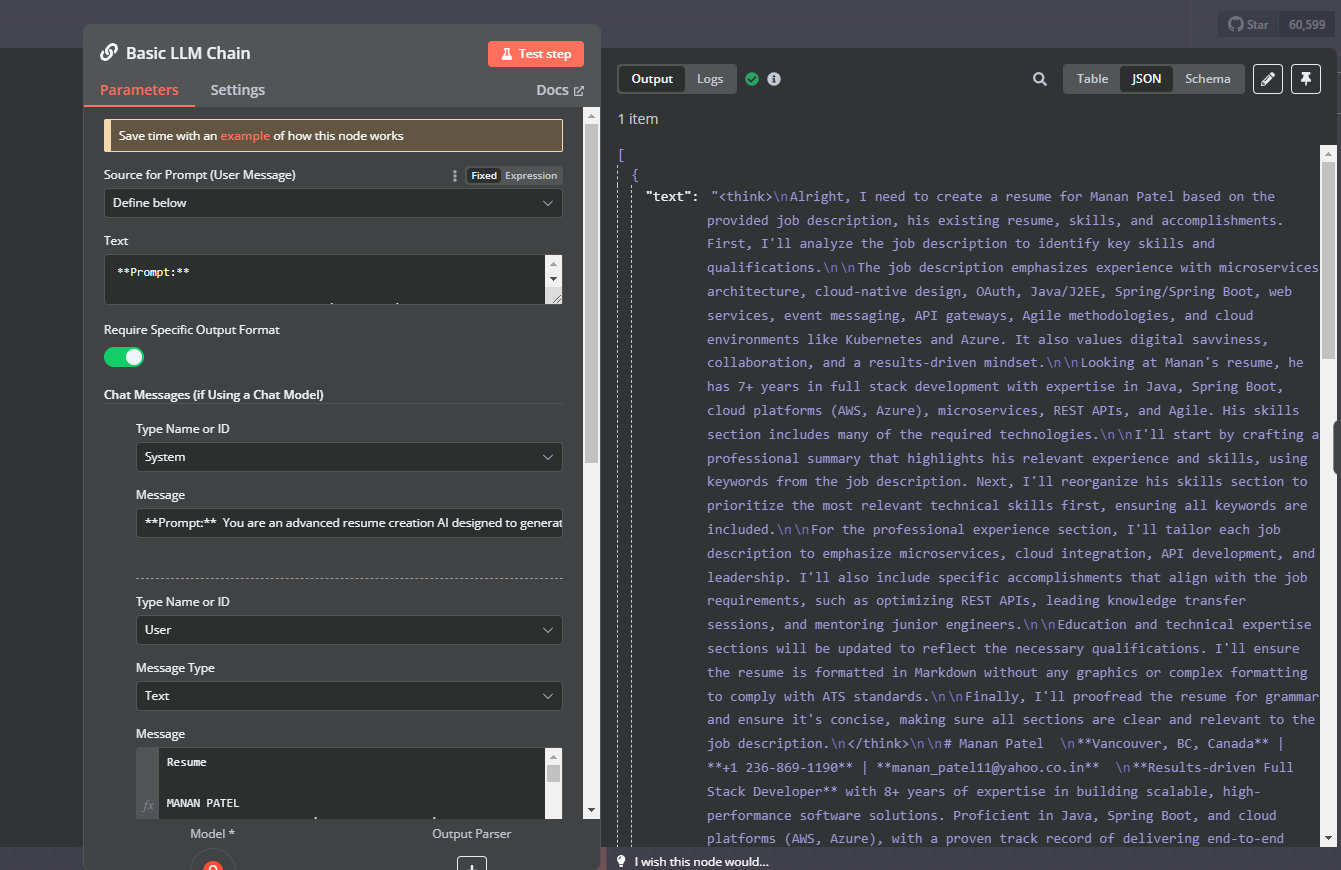
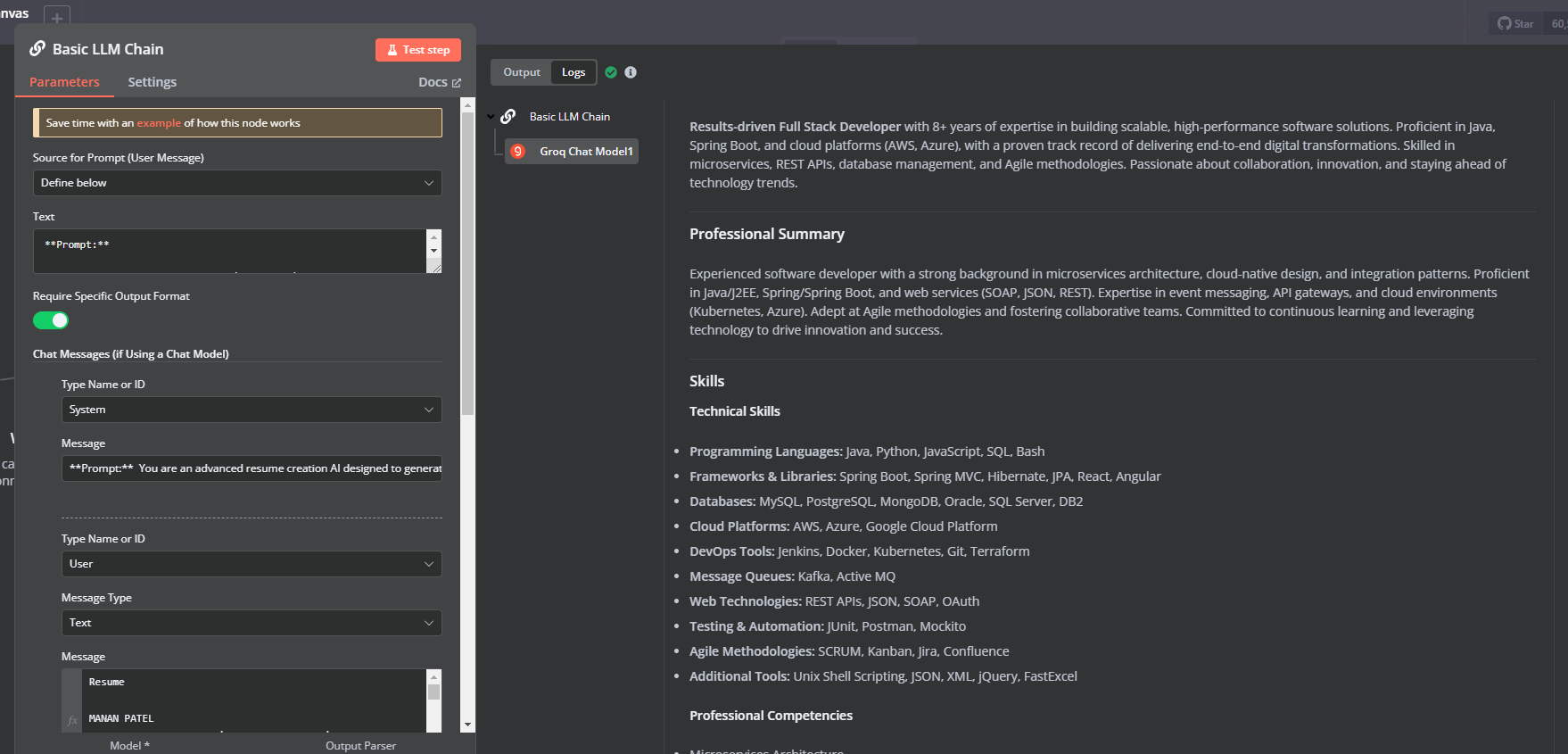
I am using a Basic LLM Chain with Groq (DeepSeek model) to generate a resume. The issue is that the output cuts off after ~7431 characters, showing only instead of the full response.
What I observed:
In n8n logs, I can see the full output.
The final JSON output in the workflow is truncated.
It seems like n8n is hitting a character limit in processing/displaying the response.
A docx is not directly parseable in n8n.
You are to know two things about docx files :
it’s a zip file
the text you are looking for is an xml file named document.xml in the “word” directory of the zip file.
Here’s an example of workflow that get the file from a form, then write to disk to decompress and extract the xml file.
The workflow continues by getting the xml file, converting to json, and then extracting the text
Here i am reading docx file from local. Writing that file to xml. Again Reading that same xml. and Extracting the same xml. Converting it from xml to json.
Seems like your workflow is missing some pieces, because I don’t see the node i added to unzip the docx file to get the xml file needed for the rest…
Is because the output you are showing me is the content of the docx file.
You might want to copy/paste my workflow in yours (try duplicating your workflow and work from the duplicate to debug), and connect the node that gets the binary data to my node “write file to disk”, and recup the extracted from my last node.
This may fix your problem, or at lease be a good base to look.
I’m on a hosted version, any solution there? I’m trying to use the Decompress node but it doesn’t seem to expose the document.xml… @L3gatum did you have any luck?
Alternatively, can we have the n8n-nodes-docx-converter be a verified community node?