Hey Nikos_Bosse
Im Actually not working on that Worklfow anymore now im working on antoher one and im really struggling so if you have any adivce if it’s a serivce you offer and i need to pay i really don’t have the money to make that invsetment but here is the workflow
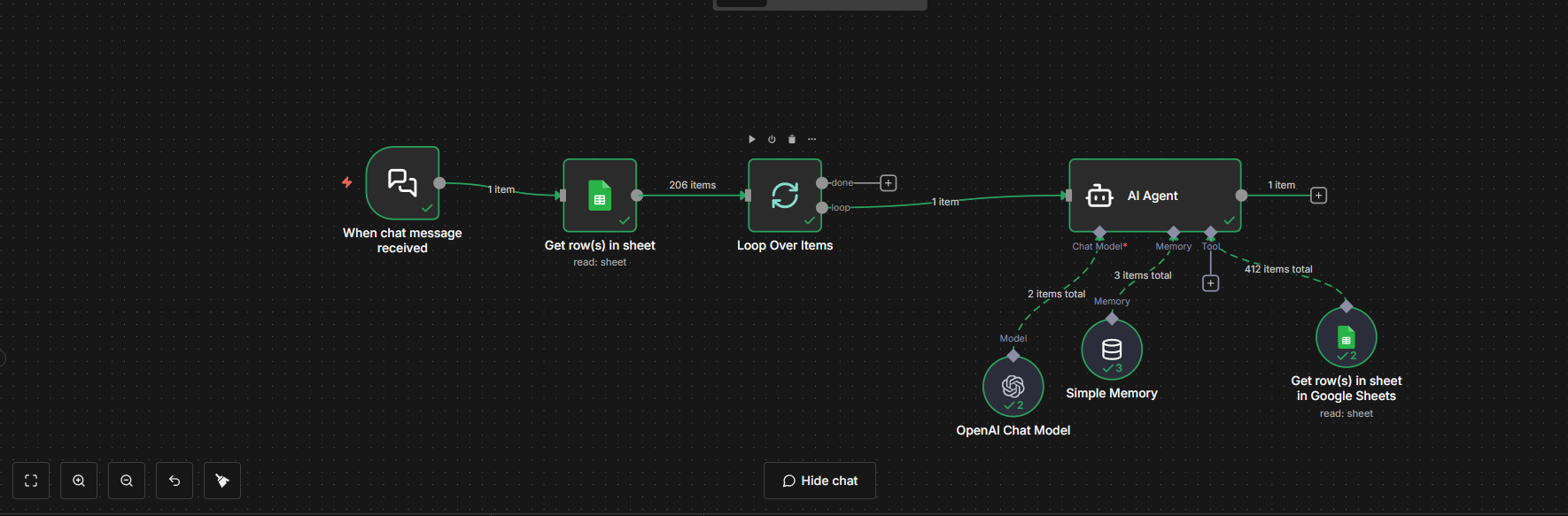
I’m building a cold-calling research workflow in n8n and I’m running into a confusing issue with the OpenAI (ChatGPT) node that I can’t seem to resolve.
Workflow (very simple i think)
-
Manual Trigger
-
Google Sheets (1 row at a time)
-
OpenAI Chat Model node
No extra parsing or transformations.
The problem
I’m using a prompt that works perfectly when I run it directly in the ChatGPT UI (chat.openai.com), but when I use the exact same prompt inside the n8n OpenAI node, the output becomes very generic and full of "N/A" values.
Example
Prompt intent
Research a real business and return structured JSON with:
-
Design project / business name
-
Focus area
-
Social media platform, activity level, and followers
Result in ChatGPT UI (correct, detailed, fact-checked)
{
"Design Project": "7 Plates Cafe - Chicago, IL",
"Focus Area": "Hospitality & Commercial Interior Design",
"Social Media Presence": {
"Platform": "Instagram",
"Activity Level": "High",
"Followers": "Approx. 6.9K+"
}
}
This output is accurate and matches real-world data.
Result in n8n OpenAI node (same prompt)
{
"Design Project": "N/A",
"Focus Area": "Interior Design",
"Social Media Presence": {
"Platform": "Twitter",
"Activity Level": "Low",
"Followers": "N/A"
}
}
This happens consistently across different businesses.
What I’ve already checked
-
Tried different models (GPT-4 / GPT-4o)
-
Adjusted temperature
-
Tested JSON vs text output
-
Confirmed prompt content is identical
-
No output parsers or extra nodes involved
Question
Is there a known difference in:
-
Inference behavior
-
Entity resolution
-
Or safety defaults
between the ChatGPT UI and the OpenAI API used by n8n, that would cause the model to return conservative "N/A" placeholders unless explicitly instructed otherwise?
If so, is there a recommended way in n8n to:
-
Enable more confident inference, or
-
Match ChatGPT UI behavior more closely for research-style prompts?
Any guidance or examples would be greatly appreciated ![]()