GOAL: I am setting up a high-volume lead enrichment workflow. My goal is to extract clean contact data (personal phone number, personal email, etc.) from raw skip-trace results.
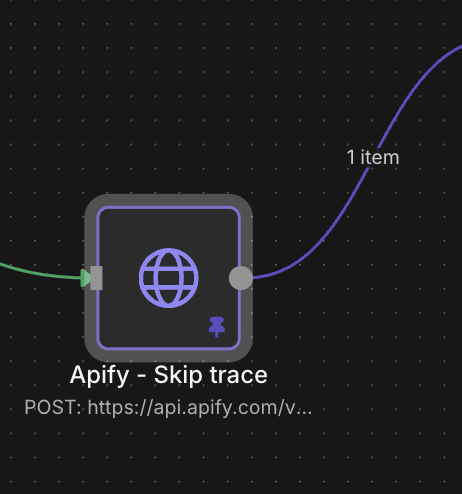
THE DATA CONFLICT: I’m pretty sure the problem is caused by the Apify Skip Trace HTTP request returning a massive, complex JSON object which includes the main profile, but also nested arrays of contradictory data (relatives, associates, multiple addresses, 5 different phone numbers, etc.).
THE PROBLEM
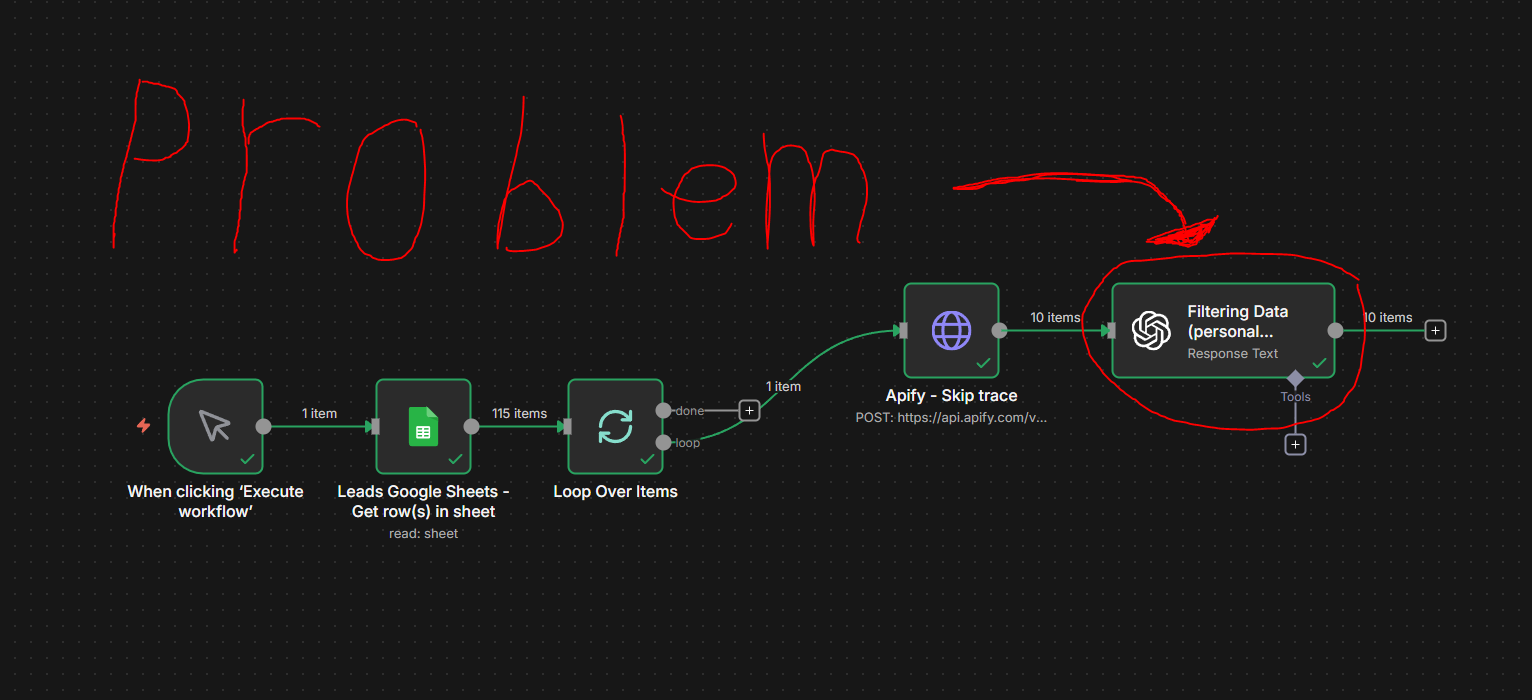
I need help creating a reliable way to transform the raw, messy JSON data from an Apify Skip Trace actor into a clean and prioritized list using the OpenAI Node (GPT-4o-mini).
The goal is to automate the judgment AI (GPT-4o-mini) to find the personal phone numbers and emails.
1. The Input Problem
The raw data coming from the Apify (Skip Trace) node is, I think, one large JSON payload with too many options and conflicting information:
-
Multiple phone numbers (Phone-1, Phone-2, etc.) — some are landlines, some are wireless.
-
Multiple email addresses (personal and corporate).
-
Nested arrays containing related people and previous addresses, which makes parsing difficult.
2. The Required AI Logic (The Judgment)
My primary difficulty is instructing the AI to judge and rank the data based on quality. I need the AI to perform the following comparison and sorting:
| Output Field | Data Priority (Highest to Lowest) |
|---|---|
| Phone 1 (Best) | Wireless (mobile) + most recent “last reported” date |
| Phone 2 (Backup) | Next best phone (reliable landline or older mobile) |
| Email 1 (Personal) | Domain is private (e.g., Gmail, Yahoo) |
| Email 2 (Work) | Corporate domain (e.g., @company.com) |
3. Output Goal
I need the AI to return only the prioritized fields in a clean, structured object that can be imported directly into my workflow.
The final output should contain:
-
Name (already available in my data)
-
Title at the Company (already available in my data)
-
Company Name (already available in my data)
-
Phone 1 — the phone number the AI determines is most likely to be the person’s primary personal day-to-day phone number
-
Phone 2 — a secondary personal phone number, if one exists — based on the AI’s ranking
-
Email 1 — the most likely personal email address (ex: [email protected])
-
Email 2 — the second-most likely personal email address
-
Work Email (already available in my data)
In short:
How can I get the AI to reliably read skip-trace data and then make an informed judgment to identify the most likely personal phone numbers and personal emails?
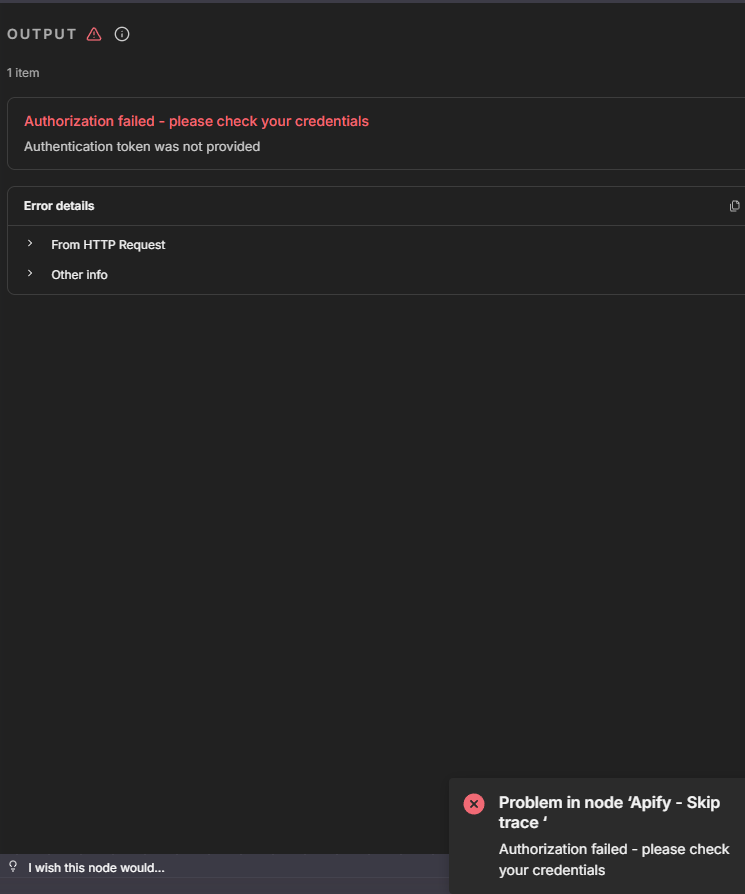
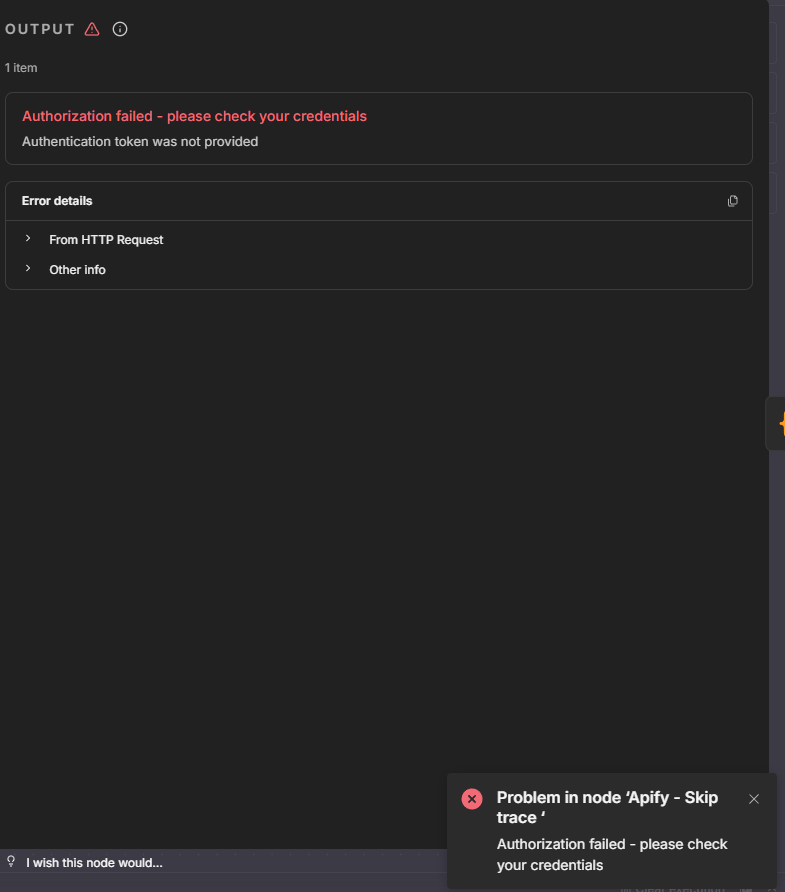
4. Field: What is the error message (if any)?
The AI (GPT-4o-mini) either returns fictitious data (e.g., “John Doe”) or fails to produce valid JSON. I’m not sure why, but it could be because the input data is too large and ambiguous.
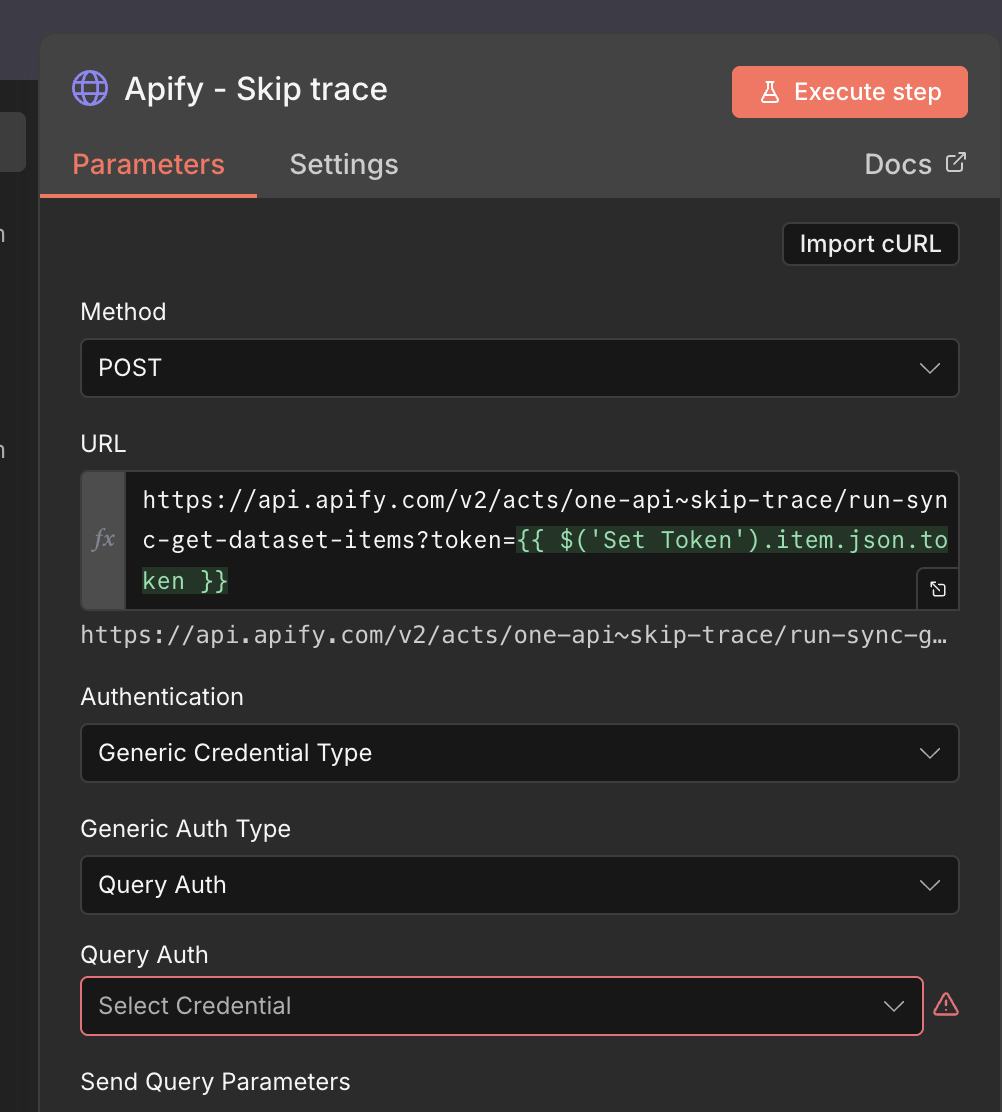
5. here is a screenshot of my workflow:
Please reach out if you need any clarification on anything. Any help is appreciated, and thank you so much in advance.