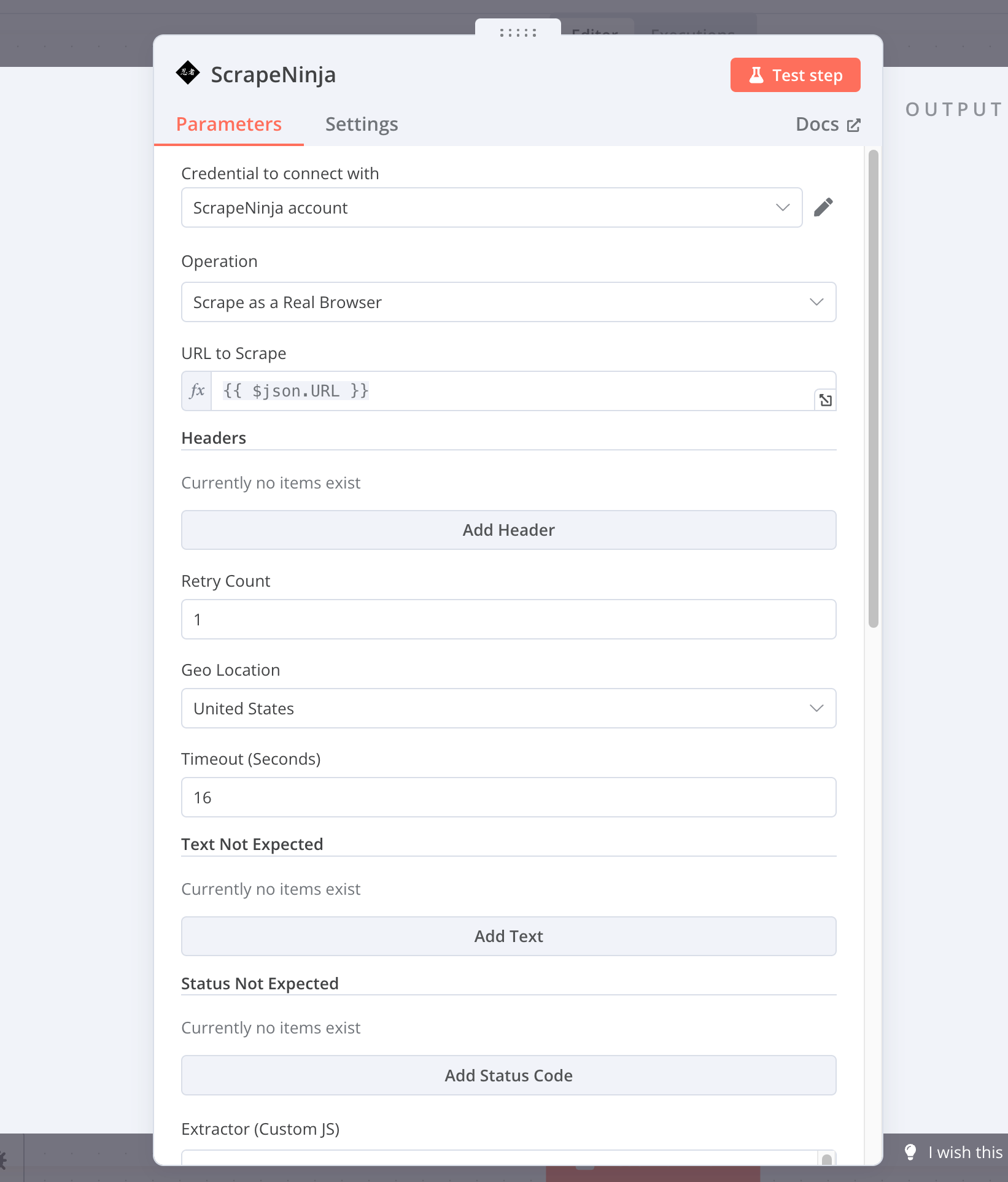
ScrapeNinja is a web scraping API SaaS that can run a real browser and capture website screenshots. I use it with n8n every day to scrape thousands of web pages and extract useful data.
Ever since I published my first n8n web scraping tutorials using the ScrapeNinja API (via the n8n HTTP request node), I’ve received tons of questions from n8n users — understandably so, because ScrapeNinja offers many parameters to control proxies, browser behavior, and more. Putting all these params into big JSON object to send into API endpoint of ScrapeNinja, all via n8n HTTP node, was not exactly user-friendly.
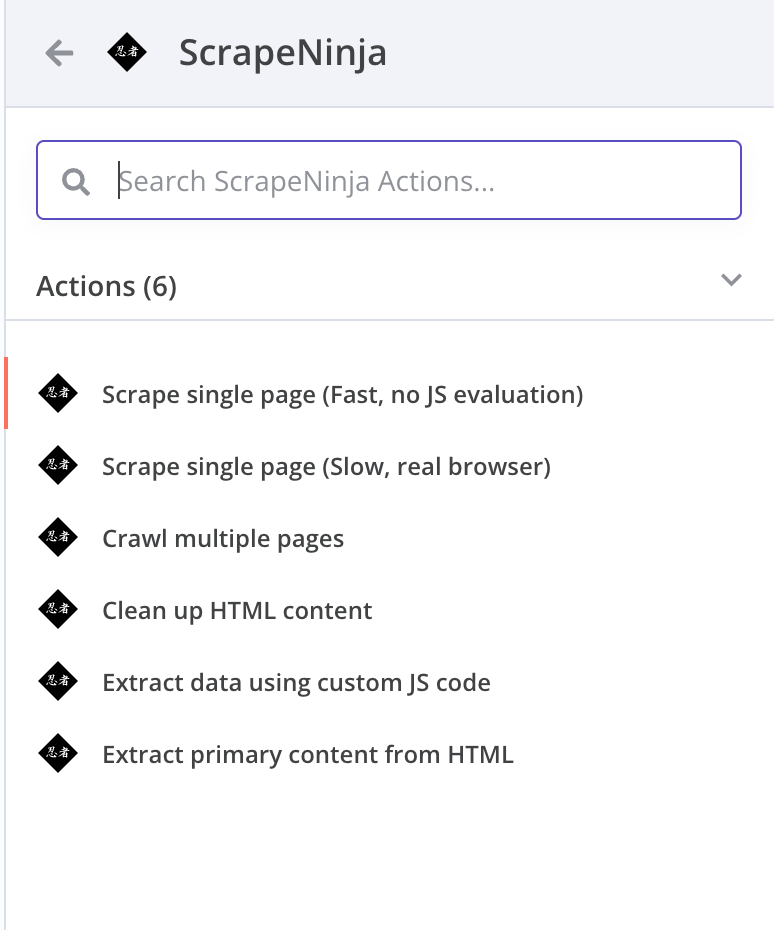
I’m now launching an official ScrapeNinja n8n integration: a full-fledged activity node. Check out the repo on npm:
To install it on self-hosted n8n, open Settings → Community Nodes, enter “n8n-nodes-scrapeninja”, install, and start scraping! Two modes are available:
• /scrape: A fast scraper using raw network requests.
• /scrape-js: Runs a real browser with JS evaluation (and can capture screenshots).
Both modes share many parameters, and you can switch between them easily. They’re also fully compatible with the awesome JS extractor feature, which lets you write a snippet of JavaScript to pull specific data from a page’s HTML:
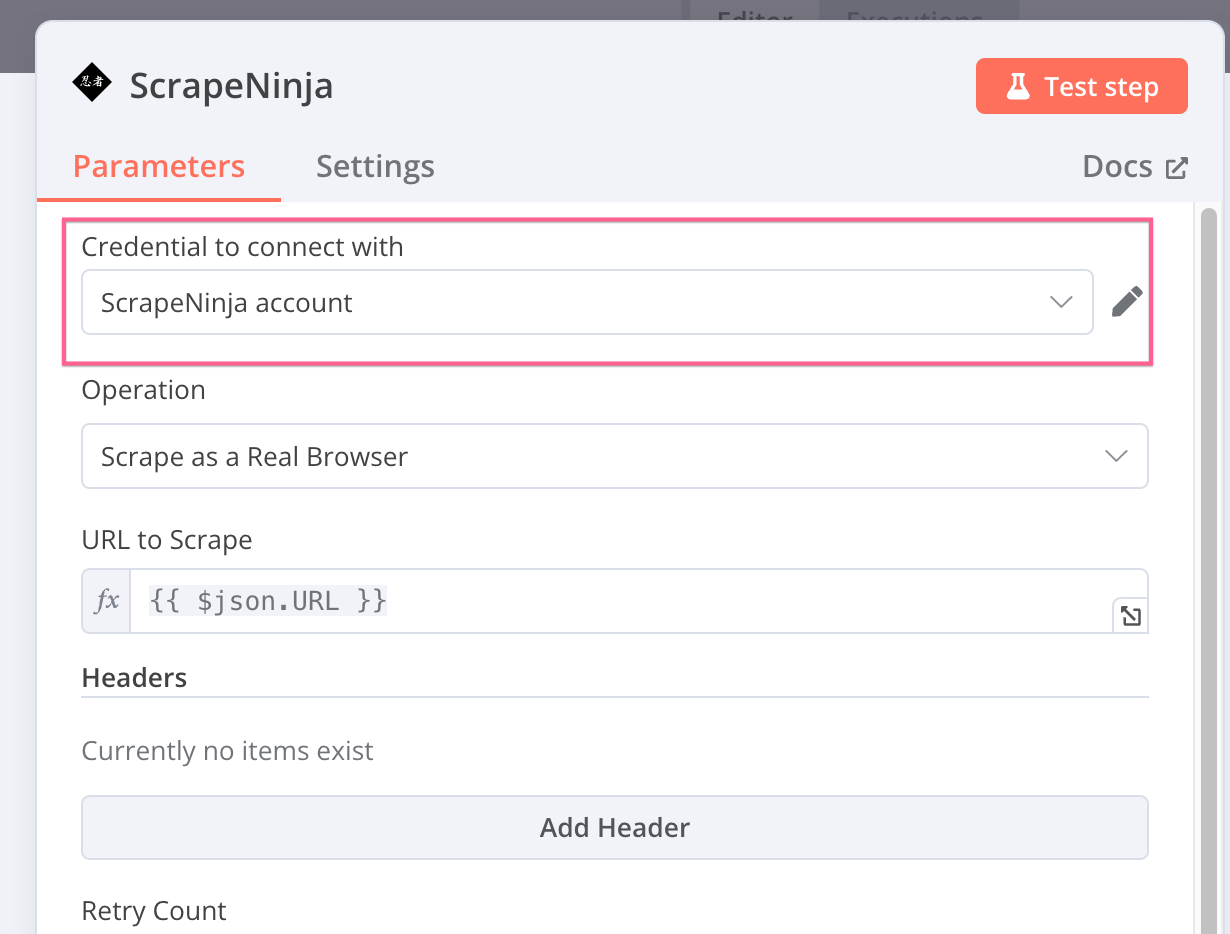
It turns out some users still experience this - but I thought I have fixed this for all new installs. What n8n version are you using, can you try to update to the latest one or just restart your n8n instance? I am still not sure why this happens.
If you have n8n logs, please send them to me - it should have some “warn” or “error” regarding credentials. I appreciate your feedback!
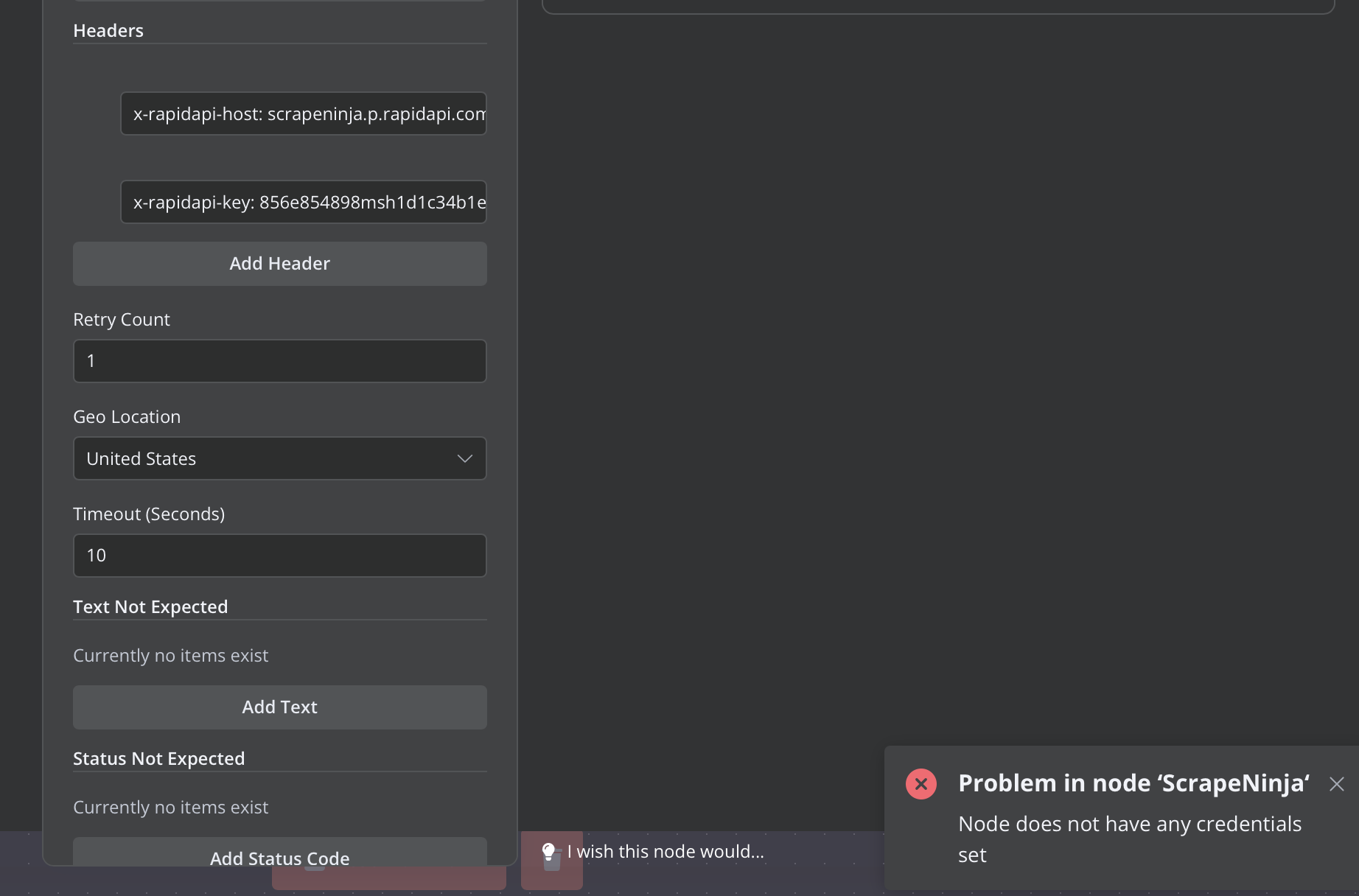
2|n8n | Failed to load Custom API options for the node “n8n-nodes-scrapeninja.scrapeNinja”: Unknown credential name “scrapeninjaApi”
If I start the workflow:
| Node does not have any credentials set
2|n8n | Error: Node does not have any credentials set
2|n8n | at new NodeOperationError (/usr/local/lib/node_modules/n8n/node_modules/n8n-workflow/src/errors/node-operation.error.ts:22:12)
2|n8n | at ExecuteContext._getCredentials (/usr/local/lib/node_modules/n8n/node_modules/n8n-core/src/execution-engine/node-execution-context/node-execution-context.ts:237:12)
2|n8n | at ExecuteContext.getCredentials (/usr/local/lib/node_modules/n8n/node_modules/n8n-core/src/execution-engine/node-execution-context/base-execute-context.ts:96:21)
2|n8n | at ExecuteContext.execute (/root/.n8n/nodes/node_modules/n8n-nodes-scrapeninja/nodes/ScrapeNinja/ScrapeNinja.node.ts:311:34)
2|n8n | at WorkflowExecute.runNode (/usr/local/lib/node_modules/n8n/node_modules/n8n-core/src/execution-engine/workflow-execute.ts:1097:31)
2|n8n | at /usr/local/lib/node_modules/n8n/node_modules/n8n-core/src/execution-engine/workflow-execute.ts:1505:38
2|n8n | at processTicksAndRejections (node:internal/process/task_queues:95:5)
2|n8n | at /usr/local/lib/node_modules/n8n/node_modules/n8n-core/src/execution-engine/workflow-execute.ts:2066:11
I have just pushed an update to ScrapeNinja n8n node (v0.3.0) which could eventually turn n8n into a serious web scraping machine.
New operation: extract primary content from HTML - uses the awesome Mozilla readability package, which smartly extracts primary text corpus from a page.
New operation: cleanup HTML. Uses the Cheerio package to smartly traverse through HTML and omit things which are not strictly important, like script tags, iframes, various html attributes, onClick handlers, html comments, and whitespace. This is especially useful for later LLM processing stages where every token counts.
Custom extractor JS evaluation. This is I think the most impactful feature. Now, you can leverage LLM inside n8n workflow to generate JS extractor code, which is later evaluated securely by this node so you get clean JSON data from ANY web page! Self-healing web scrapers are now trivial to build.
Wait, here is the best part: all these new features are completely local and do not require ScrapeNinja API key (you will need some LLM for code generation to work, obviously)
To install ScrapeNinja n8n node, in your self-hosted instance, go to Settings → Community nodes, enter “n8n-nodes-scrapeninja”, and try scraping something. Make sure you are using at least v0.3.0. Let me know how it goes!
I was cooking something amazing this week: ScrapeNinja Recursive Web Crawler, packed into an n8n community node.
It is a full-fledged, open-source recursive web crawler that traverses websites according to page URL rules and stores all pages in a Postgres database.
It uses ScrapeNinja web scraping engines (via API) to scrape each HTML page, extract all links from the page, feed them into a queue, and re-iterate until the page limit is reached or there are no more unique links to crawl.
Here’s my primary use case: building knowledge bases. I want to crawl all the documentation of a product (30-50-70 pages), extract the primary content from each page, and convert it into one huge Markdown document that can later be fed into an LLM. This is a real-world scenario: ScrapeNinja now features a compiled Markdown file (knowledge base) containing all the docs, which you can easily download and insert into the LLM of your choice to integrate ScrapeNinja into any project where you need reliable web scraping.
Yes, you read it right - I used the ScrapeNinja web crawler to crawl ScrapeNinja docs. I need your feedback on the ScrapeNinja n8n crawler! Note that it is an experimental release and this tool is advanced and powerful. I made sure to output detailed crawler logs as node JSON output; you can also poll the Postgres crawler_logs table to track the crawler node run (as it can take many minutes to finish). I am using cloud Supabase as a Postgres instance and I can recommend it for everyone.
To install it on self-hosted n8n, open Settings → Community Nodes, enter “n8n-nodes-scrapeninja”, install, and start scraping! The crawler node requires ScrapeNinja API key. Make sure your ScrapeNinja n8n node version is at least 0.4.0
I was just thinking about needing a tool to do this today!
I’m quite new to all this n8n etc so was thinking that what i really needed was a way to crawl all websites related to a topic i want to train an llm in and somehow get it in a format that i can use to do it directly
Thanks!
Important note: instead of compiling a huge markdown file, better way to use crawled pages is to save cleaned up body content back into PostgreSQL and then use LLM to convert each page into vector embedding.
Now, once we have embeddings in db, we can implement, lets say, a chatbot trigger which will use Tools agent to go to Postgres as a vector store and answer questions by finding relevant embeddings (so, we re-use crawled data knowledge inside a chatbot). Let me know if you need an example of such workflow, I am happy to share some implementations!
Have just been using Scrape Ninja to get prices from various competitors so my team can determine where our prices should sit.
So far working really well and the extractor once you get your head around it works really well. I used the tools on the website but found the new AI component did not work that well. I used deepseek and told it I wanted out for Cheerio and provided the template. Since then it has been churning out really good code to put into the extractor. As each compeditor has a different website I have a different flow for them.
All driven by a baserow table what has the compeditor, the URL of the product and a multiplier as we work in prices per KG and some need abit of tweaking.
Hey David,
When you refer to AI component which didnt work well for you, which one are you talking about?
I assume you tried to generate extractor code via Cheerio LLM Generator & Sandbox and didn’t generate good code for you, but then you tried to use Deepseek R1 directly (passing HTML into it) and it managed to generate better code for extractor func, is that right?
Hi Anthony. Thanks correct. In hindsight I think it was because given the example prompt I was not really giving the AI enough data. What I did with DeepSeek was provide it with the base sample of the extractor. The a sample of the HTML document that I had found the relevant data in and asked it to create teh extractor. After abit of refining hit on being able to create them quite quickly.
They may not all be perfect for every page within a site, but it was a good learning experience that I know understand how the extractor works so can really push it when I get edge cases.
JUst a totally different aside the documentation says that there are other nodes now available but I don’t see them. Are the only available in the latest version of n8n? I am self hosted. Cheers
Thanks David, your feedback is so valuable.
I am really curious if another approach would work better in your case:
Use ScrapeNinja basic scrape operation to get full HTML.
Use ScrapeNinja Extract primary content operation node (locally executed)
to smartly retrieve HTML of only primary text on a page (get rid of navbars, sidebars, footer, etc)
Step #2 allows to massively cut down costs on LLMs (by reducing prompt) and with modern LLMs with big context windows this approach might be “good enough” for a lot of use cases.
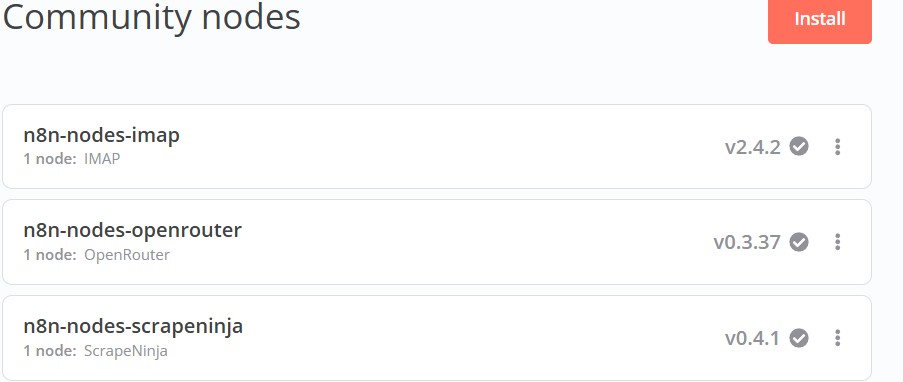
Regarding your missing ScrapeNina operations: make sure you run at least v0.4.1 (in “Community nodes” section) - here is how the list of ops should look like:
Hi Anthony.
Thanks for the information, as I’m only extracting a single figure (the price) from the page the size is not an issue. However being able to extract locally might clean up the whole flow abit.
I checked and I am on the correct version of the node.