Describe the problem/error/question
Hey guys,
I’m fairly new to n8n, and one of the first tasks I’d like to implement is a fairly monstrous workflow, that MOSTLY works - when I run it in test mode one node after another.
When trying to run an entire workflow, the google sheets > append row fails because it loses connection to the spreadsheet node. Bringing spreadsheet creation closer to the appending node does not help. Please advise.
What is the error message (if any)?
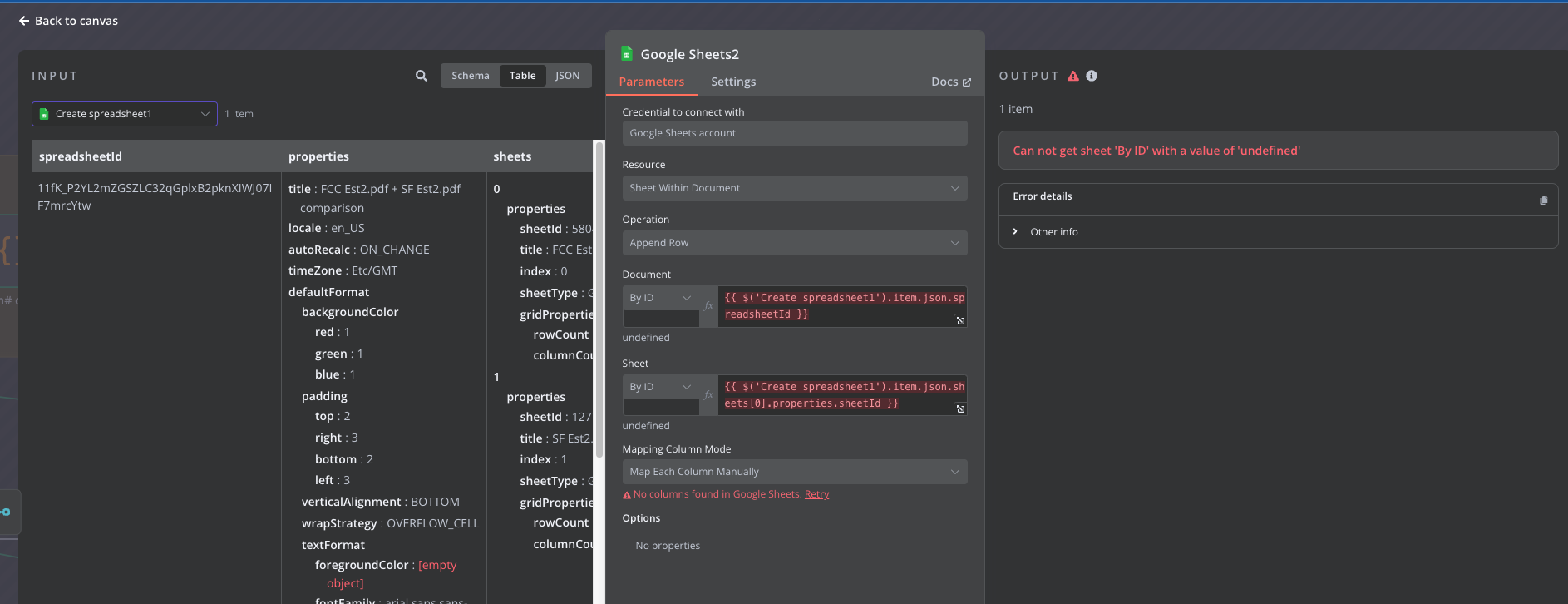
Please share your workflow
{
“nodes”: [
{
“parameters”: {
“formTitle”: “Compare estimates”,
“formFields”: {
“values”: [
{
“fieldLabel”: “Farrand estimate”,
“fieldType”: “file”,
“multipleFiles”: false,
“acceptFileTypes”: “.pdf”
},
{
“fieldLabel”: “Alternative estimate”,
“fieldType”: “file”,
“multipleFiles”: false,
“acceptFileTypes”: “.pdf”
}
]
},
“options”: {}
},
“type”: “n8n-nodes-base.formTrigger”,
“typeVersion”: 2.2,
“position”: [
-420,
420
],
“id”: “4a2eb047-38d5-4101-8caf-af4bcb51e830”,
“name”: “On form submission1”,
“webhookId”: “7c217359-6da7-45e2-970d-2fa3c3b952e7”
},
{
“parameters”: {
“jsCode”: “// Step 1: Retrieve outputUrls and ensure it’s handled safely\nlet outputUrls = items[0]?.json?.outputUrl || ;\n\n// Step 2: Ensure outputUrls is parsed and always an array\nif (typeof outputUrls === "string") {\n try {\n outputUrls = JSON.parse(outputUrls);\n } catch (error) {\n throw new Error("Failed to parse outputUrls: " + error.message);\n }\n}\n\nif (!Array.isArray(outputUrls)) {\n outputUrls = ; // Default to empty array if not valid\n}\n\n// Step 3: Generate the image blocks from outputUrls\nconst imageBlocks = outputUrls.map(url => ({\n type: "image_url",\n image_url: { url }\n}));\n\n// Step 4: Sanitize extracted text if imageBlocks is empty\nlet sanitizedText = "";\nif (imageBlocks.length === 0) {\n const extractedText = items[0]?.json?.[‘Extracted Text’] || "";\n sanitizedText = extractedText\n .replace(/\n+/g, ’ ') // Normalize newlines into spaces\n .replace(/\\/g, ‘’) // Remove escape backslashes\n .replace(/"/g, ‘\\"’) // Escape double quotes\n .replace(/^\s+|\s+$/g, ‘’); // Trim leading/trailing whitespace\n}\n\n\n// Step 5: Return either imageBlocks or sanitized text\nif (imageBlocks.length > 0) {\n return [{ json: { imageBlocks } }];\n} else {\n return [{ json: { sanitizedText } }];\n}\n”
},
“id”: “771545eb-169c-4ce5-a8d2-4af16c17b894”,
“name”: “Create Image Code Blocks2”,
“type”: “n8n-nodes-base.code”,
“typeVersion”: 2,
“position”: [
2180,
180
]
},
{
“parameters”: {
“assignments”: {
“assignments”: [
{
“id”: “387fb9f5-a847-4386-be88-333259482ceb”,
“name”: “outputUrl”,
“value”: “={{ $(‘pdfrest Convert PDF to Image2’).item.json.outputUrl }}”,
“type”: “string”
}
]
},
“options”: {}
},
“id”: “13eff039-b333-4929-85a9-13592420033c”,
“name”: “Page(s)2”,
“type”: “n8n-nodes-base.set”,
“typeVersion”: 3.4,
“position”: [
1960,
180
]
},
{
“parameters”: {
“method”: “POST”,
“url”: “https://api.pdfrest.com/jpg”,
“authentication”: “genericCredentialType”,
“genericAuthType”: “httpHeaderAuth”,
“sendHeaders”: true,
“headerParameters”: {
“parameters”: [
{
“name”: “Accept”,
“value”: “application/json”
}
]
},
“sendBody”: true,
“contentType”: “multipart-form-data”,
“bodyParameters”: {
“parameters”: [
{
“parameterType”: “formBinaryData”,
“name”: “file”,
“inputDataFieldName”: “Farrand_estimate”
}
]
},
“options”: {}
},
“id”: “36ad0bd1-e0ca-4788-a86c-49c9475890f0”,
“name”: “pdfrest Convert PDF to Image2”,
“type”: “n8n-nodes-base.httpRequest”,
“typeVersion”: 4.2,
“position”: [
1560,
180
],
“credentials”: {
“httpHeaderAuth”: {
“id”: “ST5l7fbzL5aaTZok”,
“name”: “Header Auth account 2”
}
}
},
{
“parameters”: {
“assignments”: {
“assignments”: [
{
“id”: “e26750d4-2817-4175-bbb7-470700c75591”,
“name”: “use_openai_vision”,
“value”: true,
“type”: “boolean”
}
]
},
“options”: {}
},
“id”: “c162d2fa-ddf8-4803-92c6-2a8962ba4edf”,
“name”: “Set Extraction Method2”,
“type”: “n8n-nodes-base.set”,
“typeVersion”: 3.4,
“position”: [
1760,
180
]
},
{
“parameters”: {
“fieldToSplitOut”: “components_listed”,
“options”: {}
},
“type”: “n8n-nodes-base.splitOut”,
“typeVersion”: 1,
“position”: [
3000,
180
],
“id”: “9d5df6a7-8506-4edf-9732-5496eb8c2c17”,
“name”: “Split Out4”
},
{
“parameters”: {
“method”: “POST”,
“url”: “https://api.openai.com/v1/chat/completions”,
“authentication”: “predefinedCredentialType”,
“nodeCredentialType”: “openAiApi”,
“sendHeaders”: true,
“headerParameters”: {
“parameters”: [
{
“name”: “=Content-Type”,
“value”: “application/json”
}
]
},
“sendBody”: true,
“specifyBody”: “json”,
“jsonBody”: “={\n "model": "gpt-4o",\n "messages": [\n {\n "role": "system",\n "content": "You are an expert in image analysis and structured data extraction. You will be given an image and should determine the 1. Name of insurance company providing an estimate 2. Columns included in the estimate (they maybe abbreviated or not. Look through all images to find a table that contains items like QUANTITY, UNIT, TAX, O&P, RCV, etc. 3. List of components included in the estimate. This might be something like a room that has been damaged, like BATHROOM, individual part of the building such as GARAGE ROOF, area such as DECK. Your main clue in identifying component properly is that right after it, you’ll see a table with columns you found in step 2, such as QUANTITY, UNIT, TAX etc. Each component is broken down into smaller items in the table. Your goal at this step is to identify ALL BIGGER COMPONENTS, not smaller ones inside the tables. Do not include things like Total and Grand Total"\n },\n {\n "role": "user",\n "content": [\n {\n "type": "text",\n "text": "1. Name of insurance company providing an estimate 2. Columns included in the estimate (they maybe abbreviated or not. Look through all images to find a table that contains items like QUANTITY, UNIT, TAX, O&P, RCV, etc. 3. List of rooms/ bigger components included in the estimate. {{ ($(‘Set Extraction Method2’).item.json.use_openai_vision) === false ? $(‘Create Image Code Blocks2’).item.json.sanitizedText : ‘’ }}"\n }\n {{ $(‘Set Extraction Method2’).item.json.use_openai_vision === true ? ‘,’ + JSON.stringify($(‘Create Image Code Blocks2’).item.json.imageBlocks).slice(1, -1) : ‘’ }}\n ]\n }\n ],\n"response_format": {\n "type": "json_schema",\n "json_schema": {\n "name": "insurance_estimate_analysis",\n "schema": {\n "type": "object",\n "properties": {\n "insurance_company": {\n "type": "string",\n "description": "Name of the insurance company providing the estimate"\n },\n "columns_detected": {\n "type": "array",\n "items": { "type": "string" },\n "description": "List of column headers detected in the estimate. These may include examples like QUANTITY, UNIT, TAX, O&P, RCV, etc."\n },\n "components_listed": {\n "type": "array",\n "items": { "type": "string" },\n "description": "List of rooms/house parts/areas/items mentioned in the estimate (e.g., Kitchen, Garage Door, Metal Railing)"\n },\n "confidence_score": {\n "type": "number",\n "description": "Confidence level of the extracted data"\n },\n "analysis_details": {\n "type": "object",\n "properties": {\n "detected_text": {\n "type": "array",\n "items": { "type": "string" },\n "description": "Raw detected text snippets relevant to the analysis"\n },\n "reasoning": {\n "type": "string",\n "description": "Explanation of how the information was extracted"\n },\n "timestamp": {\n "type": "string",\n "description": "Timestamp of when the analysis was performed"\n }\n },\n "required": ["detected_text", "reasoning", "timestamp"],\n "additionalProperties": false\n }\n },\n "required": ["insurance_company", "columns_detected", "components_listed", "confidence_score", "analysis_details"],\n "additionalProperties": false\n },\n "strict": true\n }\n }\n}\n”,
“options”: {}
},
“id”: “5eccf5f8-8c1b-4bc5-9b3f-bd66d7ba277b”,
“name”: “OpenAI column schema and rooms extractor2”,
“type”: “n8n-nodes-base.httpRequest”,
“position”: [
2500,
180
],
“typeVersion”: 4.2,
“credentials”: {
“openAiApi”: {
“id”: “byg8juGxFcMZoKaN”,
“name”: “OpenAi account”
}
}
},
{
“parameters”: {
“method”: “POST”,
“url”: “https://api.openai.com/v1/chat/completions”,
“authentication”: “predefinedCredentialType”,
“nodeCredentialType”: “openAiApi”,
“sendHeaders”: true,
“headerParameters”: {
“parameters”: [
{
“name”: “=Content-Type”,
“value”: “application/json”
}
]
},
“sendBody”: true,
“specifyBody”: “json”,
“jsonBody”: “={\n "model": "gpt-4o",\n "messages": [\n {\n "role": "system",\n "content": "You are an AI assistant specializing in extracting structured data from files. You will be given structured data from a previous extraction, which includes a component and detected column headers from an insurance estimate. Your task is to: Take a look at the document again. Identify items listed in the table ONLY ASSOCIATED WITH THE GIVEN COMPONENT. Extract values for each item by mapping them to the detected columns. Ensure each item’s values are structured in a table-like format where column names serve as keys, and their corresponding values are extracted from the estimate. Examples of Components and Items: Component: Kitchen; Item: Drywall Repair; Item: Paint; Component: Roof; Item: Shingle Replacement; Item: Flashing Repair; Component: Exterior; Item: Siding Repair; Item: Window Replacement; Your output should be a structured JSON where the component contains a list of items, and each item is mapped to the detected columns. Note: sometimes parts values of a particular column might make more sense in the next column. Example: Quantity: 105 SF, Unit: 0.47 . To keep the output data consistent, it is imperative that you prioritize how visually close 105 and SF are on the document, above the fact that SF makes for sense in the Unit column. In this example the correct value for Unit is thus 0.47, not SF, and correct Quantity value is 105 SF. Different quantity letter suffixes may include EA, LF, SQ, SF, etc. Do not add them to Unit, add them to Quantity, especially when these letters are closer to quantity "\n },\n {\n "role": "user",\n "content": [\n {\n "type": "text",\n "text": "Take a look at the attached document and find estimate tables for each component. Extract each individual item for {{ $(‘Split Out4’).item.json.components_listed }} component and map it to corresponding set of values listed here {{ $(‘add item# columnn2’).item.json.columns }}. ONLY EXTRACT ITEMS THAT BELONG TO THE GIVEN COMPONENT . {{ ($(‘Set Extraction Method2’).item.json.use_openai_vision) === false ? $(‘Create Image Code Blocks2’).item.json.sanitizedText : ‘’ }}"\n }\n {{ $(‘Set Extraction Method2’).item.json.use_openai_vision === true ? ‘,’ + JSON.stringify($(‘Create Image Code Blocks2’).item.json.imageBlocks).slice(1, -1) : ‘’ }}\n ]\n }\n ],\n"response_format": {\n "type": "json_schema",\n "json_schema": {\n "name": "insurance_estimate_items",\n "schema": {\n "type": "object",\n "properties": {\n "insurance_company": {\n "type": "string",\n "description": "Name of the insurance company providing the estimate"\n },\n "columns_detected": {\n "type": "array",\n "items": { "type": "string" },\n "description": "List of column headers detected in the estimate. These may include examples like QUANTITY, UNIT, TAX, O&P, RCV, etc."\n },\n "component_name": {\n "type": "string",\n "description": "The name of the component (e.g., Kitchen, Roof, Exterior)"\n },\n "items": {\n "type": "array",\n "items": {\n "type": "object",\n "properties": {\n "item_name": {\n "type": "string",\n "description": "Name of the item (e.g., Drywall Repair, Shingle Replacement, Window Replacement)"\n },\n "values": {\n "type": "object",\n "description": "A mapping of column names to their respective values for this item",\n "additionalProperties": {\n "type": "string",\n "description": "Value corresponding to a detected column for this item"\n }\n }\n },\n "required": ["item_name"],\n "additionalProperties": false\n }\n },\n "confidence_score": {\n "type": "number",\n "description": "Confidence level of the extracted data"\n },\n "analysis_details": {\n "type": "object",\n "properties": {\n "detected_text": {\n "type": "array",\n "items": { "type": "string" },\n "description": "Raw detected text snippets relevant to the analysis"\n },\n "reasoning": {\n "type": "string",\n "description": "Explanation of how the information was extracted"\n },\n "timestamp": {\n "type": "string",\n "description": "Timestamp of when the analysis was performed"\n }\n },\n "required": ["detected_text", "reasoning", "timestamp"],\n "additionalProperties": false\n }\n },\n "required": ["insurance_company", "columns_detected", "component_name", "items", "confidence_score", "analysis_details"],\n "additionalProperties": false\n },\n "strict": true\n }\n}\n}”,
“options”: {}
},
“id”: “97142f91-c6c8-475f-b6b3-50fc66ff6dad”,
“name”: “OpenAI per Room Data Extractor2”,
“type”: “n8n-nodes-base.httpRequest”,
“position”: [
3160,
180
],
“typeVersion”: 4.2,
“credentials”: {
“openAiApi”: {
“id”: “byg8juGxFcMZoKaN”,
“name”: “OpenAi account”
}
}
},
{
“parameters”: {
“jsCode”: “item = JSON.parse($input.first().json.choices[0].message.content);\nreturn item;”
},
“type”: “n8n-nodes-base.code”,
“typeVersion”: 2,
“position”: [
2660,
180
],
“id”: “ed42da10-c147-413c-8079-74e867cce914”,
“name”: “Parse room/column schema2”
},
{
“parameters”: {
“mode”: “runOnceForEachItem”,
“jsCode”: “item = JSON.parse($json.choices[0].message.content);\nreturn item;”
},
“type”: “n8n-nodes-base.code”,
“typeVersion”: 2,
“position”: [
3320,
180
],
“id”: “5e79842b-6656-48c1-bb39-284f6e04ee64”,
“name”: “Parse data extractor output2”
},
{
“parameters”: {
“resource”: “folder”,
“name”: “=Estimate from {{ $(‘On form submission1’).item.json.submittedAt }}”,
“driveId”: {
“__rl”: true,
“mode”: “list”,
“value”: “My Drive”
},
“folderId”: {
“__rl”: true,
“value”: “1XInjejqgqZNzX12-GaiRhf5puq9hQc8T”,
“mode”: “list”,
“cachedResultName”: “Farrand estimate”,
“cachedResultUrl”: “https://drive.google.com/drive/folders/1XInjejqgqZNzX12-GaiRhf5puq9hQc8T”
},
“options”: {}
},
“type”: “n8n-nodes-base.googleDrive”,
“typeVersion”: 3,
“position”: [
-180,
40
],
“id”: “cb02db71-6455-4aaa-a77f-51d95b5080d4”,
“name”: “Create folder1”,
“executeOnce”: true,
“credentials”: {
“googleDriveOAuth2Api”: {
“id”: “9NSelEY5CvojldOr”,
“name”: “Google Drive account”
}
}
},
{
“parameters”: {
“resource”: “spreadsheet”,
“title”: “={{ $(‘On form submission1’).item.json[‘Farrand estimate’].filename }} + {{ $(‘On form submission1’).item.json[‘Alternative estimate’].filename }} comparison”,
“sheetsUi”: {
“sheetValues”: [
{
“title”: “={{ $(‘On form submission1’).item.json[‘Farrand estimate’].filename }}”
},
{
“title”: “={{ $(‘On form submission1’).item.json[‘Alternative estimate’].filename }}”
}
]
},
“options”: {}
},
“type”: “n8n-nodes-base.googleSheets”,
“typeVersion”: 4.5,
“position”: [
20,
40
],
“id”: “e18263ee-4d5b-4691-8d55-daef0d434bea”,
“name”: “Create spreadsheet1”,
“credentials”: {
“googleSheetsOAuth2Api”: {
“id”: “fEHvaHKTR8gnvU30”,
“name”: “Google Sheets account”
}
}
},
{
“parameters”: {
“operation”: “move”,
“fileId”: {
“__rl”: true,
“value”: “={{ $json.spreadsheetId }}”,
“mode”: “id”
},
“driveId”: {
“__rl”: true,
“mode”: “list”,
“value”: “My Drive”
},
“folderId”: {
“__rl”: true,
“value”: “={{ $(‘Create folder1’).item.json.id }}”,
“mode”: “id”
}
},
“type”: “n8n-nodes-base.googleDrive”,
“typeVersion”: 3,
“position”: [
220,
200
],
“id”: “752c0720-4fa0-44b6-9ffe-95e2a065994b”,
“name”: “Move spreadsheet1”,
“executeOnce”: true,
“credentials”: {
“googleDriveOAuth2Api”: {
“id”: “9NSelEY5CvojldOr”,
“name”: “Google Drive account”
}
}
},
{
“parameters”: {
“operation”: “append”,
“documentId”: {
“__rl”: true,
“value”: “={{ $(‘Create spreadsheet1’).item.json.spreadsheetId }}”,
“mode”: “id”
},
“sheetName”: {
“__rl”: true,
“value”: “={{ $(‘Create spreadsheet1’).item.json.sheets[0].properties.sheetId }}”,
“mode”: “id”
},
“columns”: {
“mappingMode”: “defineBelow”,
“value”: {},
“matchingColumns”: ,
“schema”: ,
“attemptToConvertTypes”: false,
“convertFieldsToString”: false
},
“options”: {}
},
“type”: “n8n-nodes-base.googleSheets”,
“typeVersion”: 4.5,
“position”: [
4200,
440
],
“id”: “263fab3d-28bf-4c46-a26b-e448a6c353f0”,
“name”: “Google Sheets2”,
“credentials”: {
“googleSheetsOAuth2Api”: {
“id”: “fEHvaHKTR8gnvU30”,
“name”: “Google Sheets account”
}
}
},
{
“parameters”: {
“mode”: “runOnceForEachItem”,
“jsCode”: “function transformData(componentName, items) {\n let transformed = items.map(item => {\n return {\n "COMPONENT NAME": componentName,\n "ITEM NAME": item.item_name,\n …item.values\n };\n });\n\n // Add an empty row with the same keys to mark the end\n if (transformed.length > 0) {\n let emptyRow = Object.keys(transformed[0]).reduce((acc, key) => {\n acc[key] = "";\n return acc;\n }, {});\n transformed.push(emptyRow);\n }\n\n return { json: { data: transformed } };\n}\n\n\nlet result = transformData($json.component_name , $json.items);\nreturn result;”
},
“id”: “e61b9171-bf07-4968-b71e-8758bf24a373”,
“name”: “Header2”,
“type”: “n8n-nodes-base.code”,
“typeVersion”: 1,
“position”: [
3580,
280
]
},
{
“parameters”: {
“fieldToSplitOut”: “data”,
“options”: {}
},
“type”: “n8n-nodes-base.splitOut”,
“typeVersion”: 1,
“position”: [
3760,
280
],
“id”: “aa6de20b-c89a-4994-be33-8dedc2c8a1a2”,
“name”: “Split Out5”
},
{
“parameters”: {
“jsCode”: “return { \n json: { \n columns: ["item#", …$input.first().json.columns_detected], \n components_listed: $input.first().json.components_listed\n } \n };”
},
“type”: “n8n-nodes-base.code”,
“typeVersion”: 2,
“position”: [
2840,
180
],
“id”: “d6083c78-f11a-4f33-a737-346763a1b8c7”,
“name”: “add item# columnn2”
},
{
“parameters”: {
“content”: “Data extraction pipeline”,
“height”: 274,
“width”: 990
},
“id”: “63cd0abd-9c67-4e17-b068-6a88fb3e19af”,
“name”: “Sticky Note10”,
“type”: “n8n-nodes-base.stickyNote”,
“typeVersion”: 1,
“position”: [
2440,
100
]
},
{
“parameters”: {
“content”: “Image manipulation pipeline 1”,
“height”: 274,
“width”: 850
},
“id”: “82ce48e9-fc3e-4198-92f0-e2defdf22bc3”,
“name”: “Sticky Note11”,
“type”: “n8n-nodes-base.stickyNote”,
“typeVersion”: 1,
“position”: [
1500,
100
]
},
{
“parameters”: {
“mode”: “chooseBranch”,
“useDataOfInput”: 2
},
“type”: “n8n-nodes-base.merge”,
“typeVersion”: 3,
“position”: [
400,
400
],
“id”: “b3a689a6-9785-4143-91b0-a63f11049ee0”,
“name”: “Merge8”
},
{
“parameters”: {
“name”: “={{ $json.fileName }}”,
“driveId”: {
“__rl”: true,
“value”: “My Drive”,
“mode”: “list”,
“cachedResultName”: “My Drive”,
“cachedResultUrl”: “https://drive.google.com/drive/my-drive”
},
“folderId”: {
“__rl”: true,
“value”: “={{ $json.id }}”,
“mode”: “id”
},
“options”: {}
},
“type”: “n8n-nodes-base.googleDrive”,
“typeVersion”: 3,
“position”: [
960,
60
],
“id”: “ad4f5be1-662a-4bf8-b602-2277848b5aa6”,
“name”: “Google Drive1”,
“credentials”: {
“googleDriveOAuth2Api”: {
“id”: “9NSelEY5CvojldOr”,
“name”: “Google Drive account”
}
}
},
{
“parameters”: {
“functionCode”: “let results = ;\n\nfor (item of items) {\n for (key of Object.keys(item.binary)) {\n results.push({\n json: {\n fileName: item.binary[key].fileName\n },\n binary: {\n data: item.binary[key],\n }\n });\n }\n}\n\nreturn results;”
},
“name”: “Split Up Binary Data1”,
“type”: “n8n-nodes-base.function”,
“position”: [
600,
400
],
“typeVersion”: 1,
“id”: “2d361b8c-772b-46e4-876c-a79cc750c0a6”
},
{
“parameters”: {
“mode”: “combine”,
“combineBy”: “combineAll”,
“options”: {}
},
“type”: “n8n-nodes-base.merge”,
“typeVersion”: 3,
“position”: [
780,
60
],
“id”: “168cdaec-aa82-455c-bc90-af9aa9a70b7d”,
“name”: “Merge9”
},
{
“parameters”: {
“mode”: “combine”,
“combineBy”: “combineAll”,
“options”: {}
},
“type”: “n8n-nodes-base.merge”,
“typeVersion”: 3,
“position”: [
1320,
380
],
“id”: “318bb23a-8883-42fb-afe4-273227eb560c”,
“name”: “Merge10”
},
{
“parameters”: {
“fieldsToAggregate”: {
“fieldToAggregate”: [
{}
]
},
“options”: {}
},
“type”: “n8n-nodes-base.aggregate”,
“typeVersion”: 1,
“position”: [
1120,
60
],
“id”: “75547528-0416-486e-b6a9-69ea747ea557”,
“name”: “Aggregate1”
},
{
“parameters”: {
“mode”: “chooseBranch”
},
“type”: “n8n-nodes-base.merge”,
“typeVersion”: 3,
“position”: [
4000,
420
],
“id”: “21a71f8a-7884-43dc-bfc8-2294bca2ff11”,
“name”: “Merge3”
}
],
“connections”: {
“On form submission1”: {
“main”: [
[
{
“node”: “Create folder1”,
“type”: “main”,
“index”: 0
},
{
“node”: “Merge8”,
“type”: “main”,
“index”: 1
}
]
]
},
“Create Image Code Blocks2”: {
“main”: [
[
{
“node”: “OpenAI column schema and rooms extractor2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Page(s)2”: {
“main”: [
[
{
“node”: “Create Image Code Blocks2”,
“type”: “main”,
“index”: 0
}
]
]
},
“pdfrest Convert PDF to Image2”: {
“main”: [
[
{
“node”: “Set Extraction Method2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Set Extraction Method2”: {
“main”: [
[
{
“node”: “Page(s)2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Split Out4”: {
“main”: [
[
{
“node”: “OpenAI per Room Data Extractor2”,
“type”: “main”,
“index”: 0
}
]
]
},
“OpenAI column schema and rooms extractor2”: {
“main”: [
[
{
“node”: “Parse room/column schema2”,
“type”: “main”,
“index”: 0
}
]
]
},
“OpenAI per Room Data Extractor2”: {
“main”: [
[
{
“node”: “Parse data extractor output2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Parse room/column schema2”: {
“main”: [
[
{
“node”: “add item# columnn2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Parse data extractor output2”: {
“main”: [
[
{
“node”: “Header2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Create folder1”: {
“main”: [
[
{
“node”: “Create spreadsheet1”,
“type”: “main”,
“index”: 0
},
{
“node”: “Merge9”,
“type”: “main”,
“index”: 0
}
]
]
},
“Create spreadsheet1”: {
“main”: [
[
{
“node”: “Move spreadsheet1”,
“type”: “main”,
“index”: 0
},
{
“node”: “Merge3”,
“type”: “main”,
“index”: 1
}
]
]
},
“Move spreadsheet1”: {
“main”: [
[
{
“node”: “Merge8”,
“type”: “main”,
“index”: 0
}
]
]
},
“Google Sheets2”: {
“main”: [
]
},
“Header2”: {
“main”: [
[
{
“node”: “Split Out5”,
“type”: “main”,
“index”: 0
}
]
]
},
“Split Out5”: {
“main”: [
[
{
“node”: “Merge3”,
“type”: “main”,
“index”: 0
}
]
]
},
“add item# columnn2”: {
“main”: [
[
{
“node”: “Split Out4”,
“type”: “main”,
“index”: 0
}
]
]
},
“Merge8”: {
“main”: [
[
{
“node”: “Split Up Binary Data1”,
“type”: “main”,
“index”: 0
},
{
“node”: “Merge10”,
“type”: “main”,
“index”: 1
}
]
]
},
“Google Drive1”: {
“main”: [
[
{
“node”: “Aggregate1”,
“type”: “main”,
“index”: 0
}
]
]
},
“Split Up Binary Data1”: {
“main”: [
[
{
“node”: “Merge9”,
“type”: “main”,
“index”: 1
}
]
]
},
“Merge9”: {
“main”: [
[
{
“node”: “Google Drive1”,
“type”: “main”,
“index”: 0
}
]
]
},
“Merge10”: {
“main”: [
[
{
“node”: “pdfrest Convert PDF to Image2”,
“type”: “main”,
“index”: 0
}
]
]
},
“Aggregate1”: {
“main”: [
[
{
“node”: “Merge10”,
“type”: “main”,
“index”: 0
}
]
]
},
“Merge3”: {
“main”: [
[
{
“node”: “Google Sheets2”,
“type”: “main”,
“index”: 0
}
]
]
}
},
“pinData”: {},
“meta”: {
“instanceId”: “3fb372c7820b1b79287f0b2b12ee67005450d731fdd2da3a00ff942844b7607f”
}
}
Share the output returned by the last node
Information on your n8n setup
- *n8n version: 1.80.5 cloud
- **Database (default: SQLite): not used
- **Running n8n via (Docker, npm, n8n cloud, desktop app): Cloud
- **Operating system: MacOS