Hi all,
Please be patient - I am new to this and learning by doing.
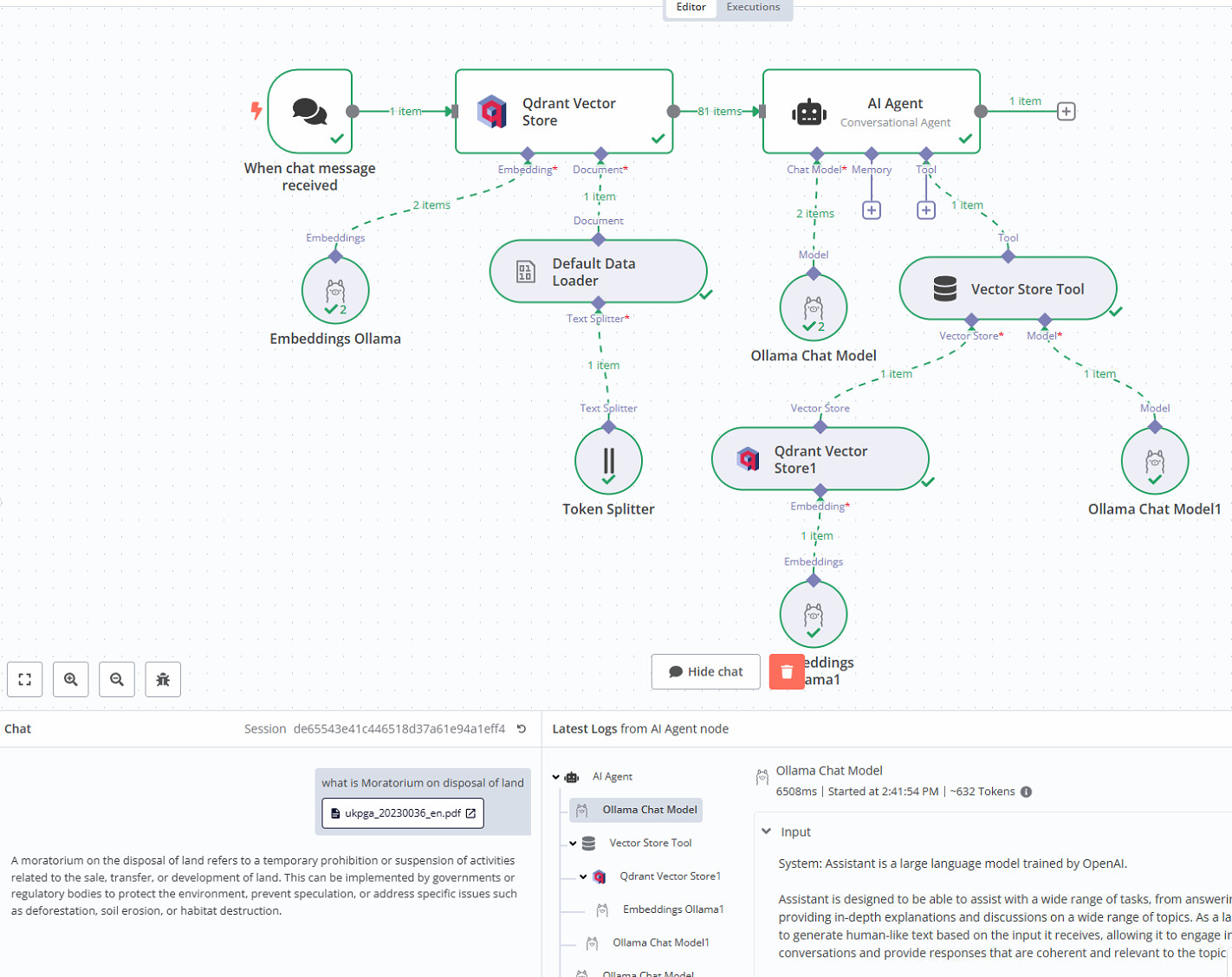
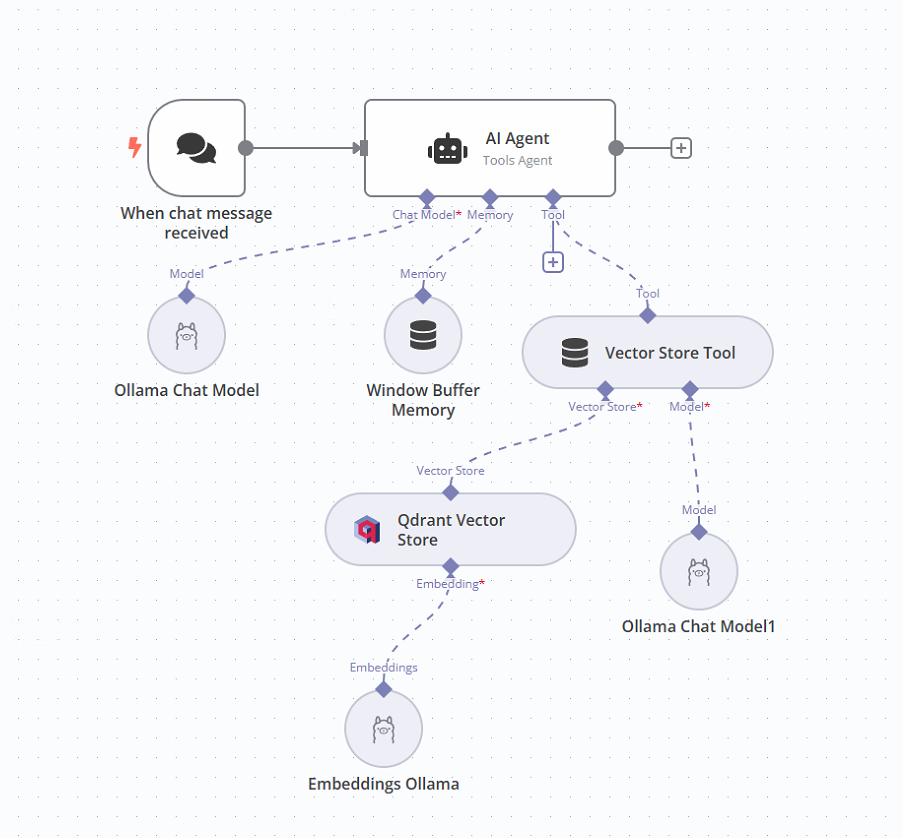
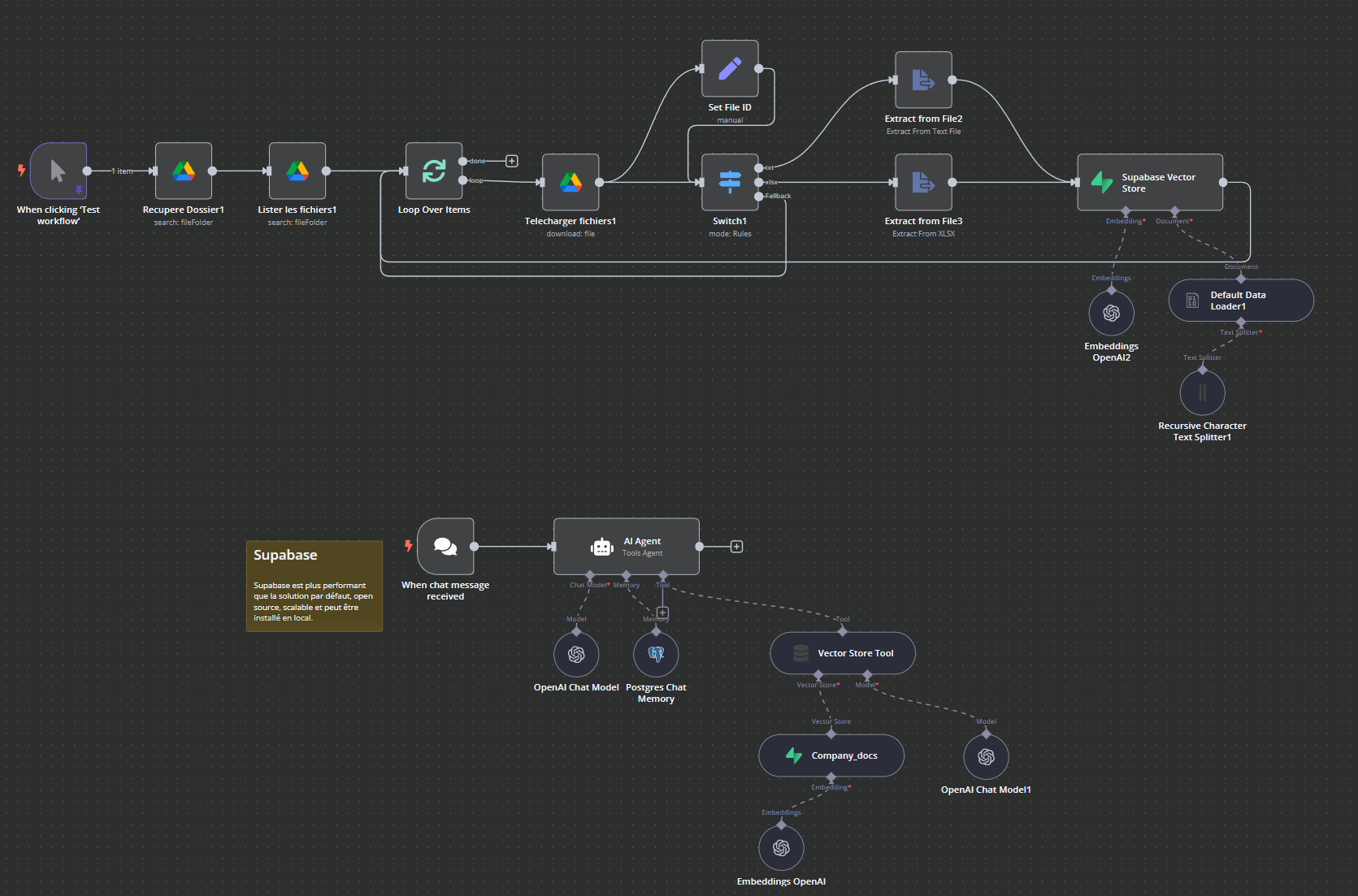
I installed GitHub - n8n-io/self-hosted-ai-starter-kit: The Self-hosted AI Starter Kit is an open-source template that quickly sets up a local AI environment. Curated by n8n, it provides essential tools for creating secure, self-hosted AI workflows. (amazing btw) and I can run a query, with a file, and it does a good job answering. My workflow is attached. However, I want to upload a whole bunch of documents (I dont need document upload) and all answers have to be strictly be limited to the contents of the files. I dont know how to do this ![]() I tried a few times but failed miserably.
I tried a few times but failed miserably.
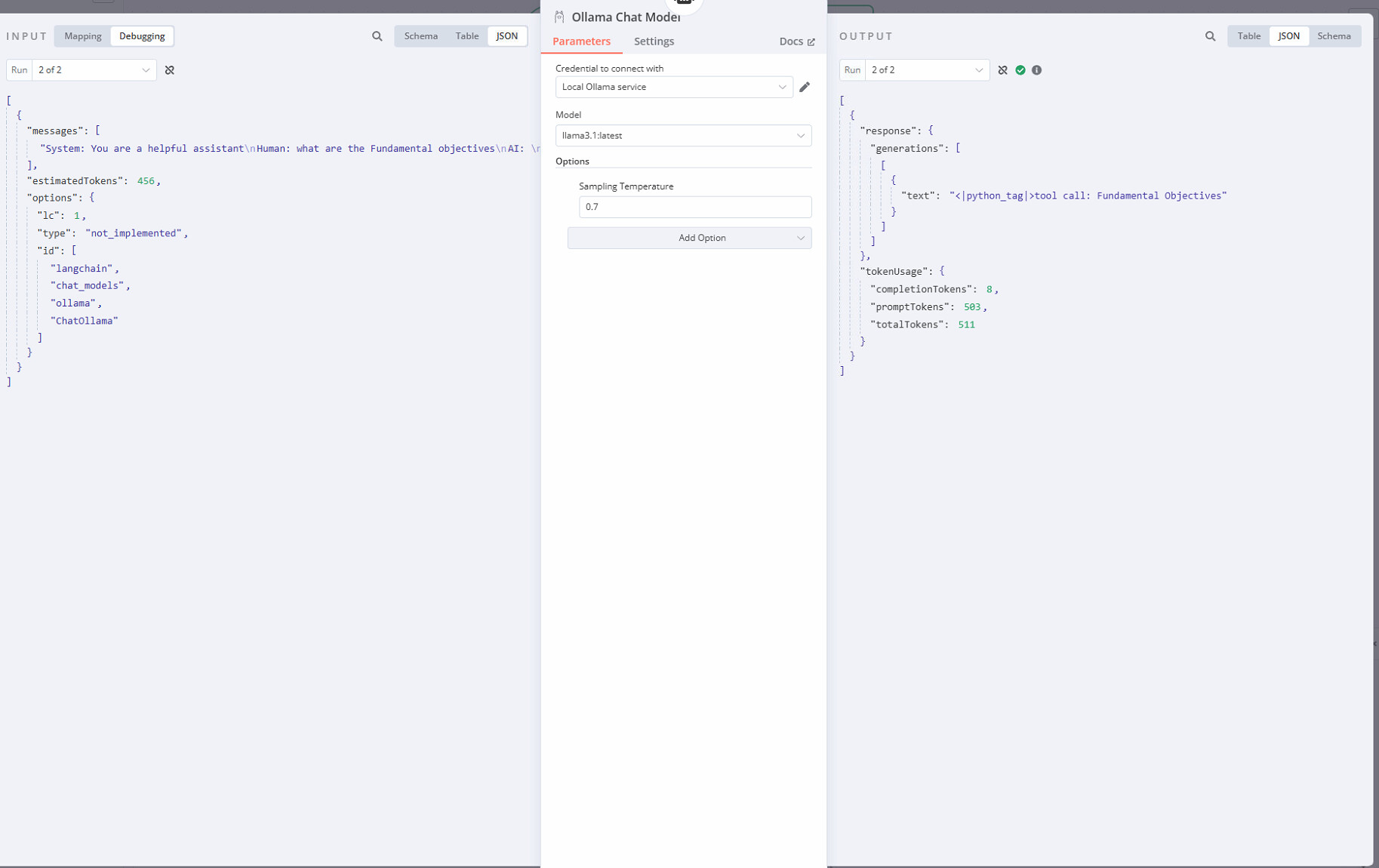
you will see my attempt in the second workflow without attachment but it is picking up one collection in the vectore store. It is reading it but I get
<|python_tag|>tool call: Fundamental Objectiv<
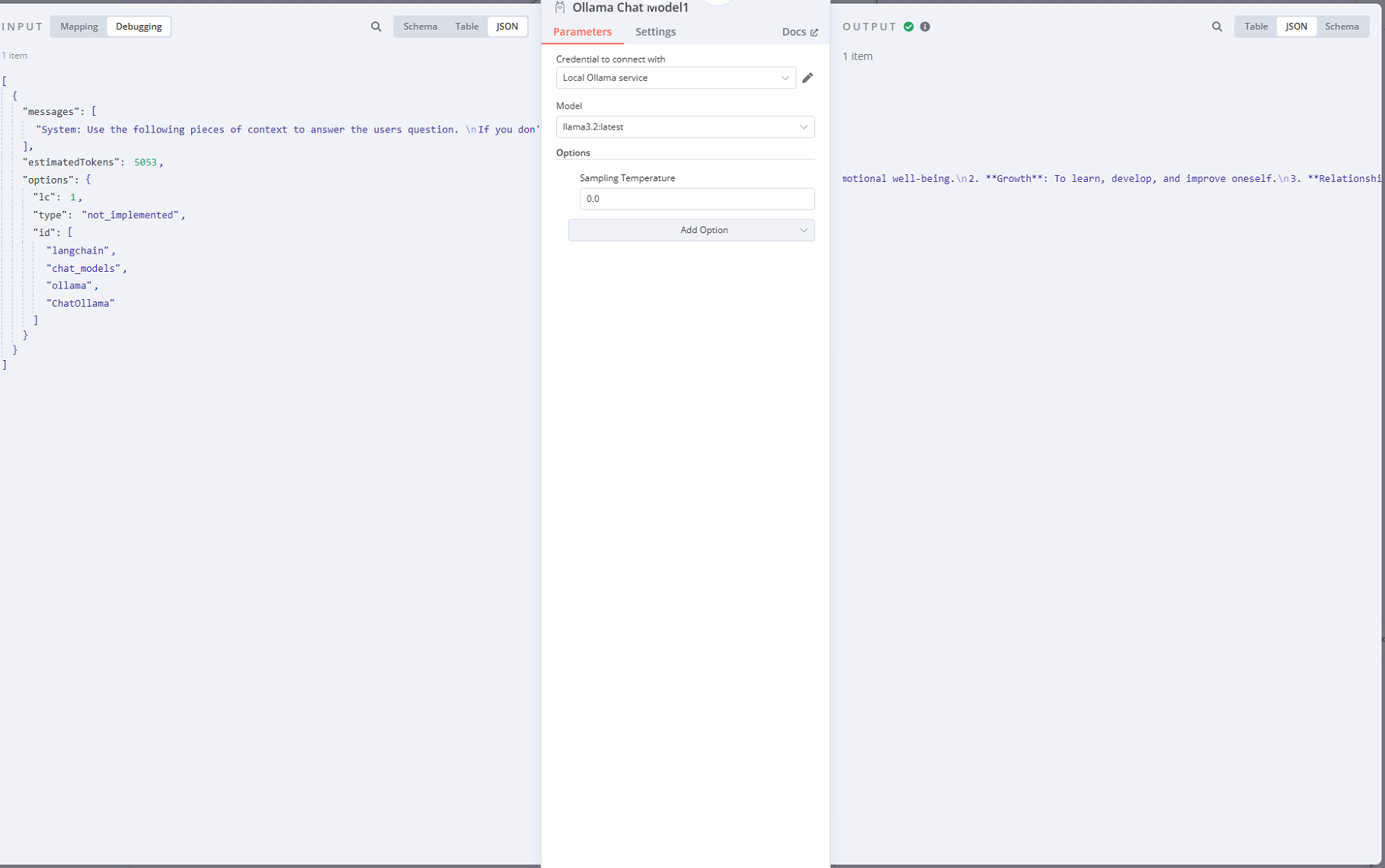
I can see the vector store is getting some data and the embeddings, but the ollama chat against that is showing some generic responses that are not specific to the document even though i have set temp to 0. Help!
has anyone done something similar that they can share. I am on a windows 11 pc with Nvidia