HEy,
I’m trying to load PDF to supabase but the extract from PDF node says that it doesn’t receive binary data.
I’ve tried a lot of different things but it doesn’t work.
Help apprecciated!
HEy,
I’m trying to load PDF to supabase but the extract from PDF node says that it doesn’t receive binary data.
I’ve tried a lot of different things but it doesn’t work.
Help apprecciated!
I’ve got a similar issue in the past an I solved putting the “Extract from File” node earlier in the workflow. I don’t really know why but it worked.
Hi @augustin
The Extract from PDF node only works if the incoming item contains binary data (for example binary.data). The error happens because the workflow is passing a URL, metadata, or text, not the actual PDF file.
Correct approach:
binary.data (application/pdf)
data![]() URLs, Supabase storage paths, or “List/Search” nodes do not work without downloading the file first.
URLs, Supabase storage paths, or “List/Search” nodes do not work without downloading the file first.
![]() Set nodes can remove binary data if Keep Binary Data is not enabled.
Set nodes can remove binary data if Keep Binary Data is not enabled.
If binary.data does not exist in the previous node, Extract from PDF will always fail.
Hi @augustin, welcome!
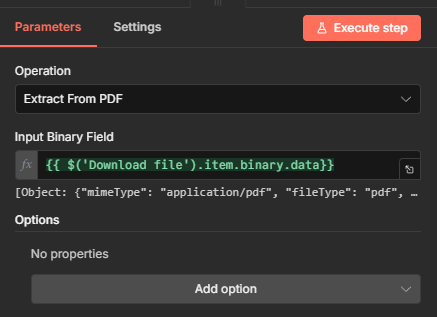
You can use expressions to reference binary:
{{ $('Download file').item.binary.data}}
give it a try!