I am trying to get a markdown file that is synced to github over to fibery. but i am already hitting a wall by getting the markdown file content.
I did try two ways: download from google drive and get from github. both times i end up with a data node that has the name and filetype - but when i view it its empty. what am i doing wrong here? how can I access the markdown text content? i can get the name, i can get the id - but i can not get the content as text (by adding binary to json i get an error ERROR: Unexpected token A in JSON at position 2)
actually what I want to achieve: Whenever a new markdown file is added to the repo:
get its name and content,
optional (read the YAML frontmatter and extract the data fields as Key:values)
create a new entry in fibery database with the name as name and the content as description
optional (fill key columns :values)
thankful for any tipps or hints into the right documentation. thanks!
Can you share the workflow you currently have? I had a quick go with a markdown file and I can get the data loaded by using Binary to JSON with Set All Data disabled.
The tricky bit from here will be extracting the YAML as we don’t have an inbuilt node for that so it might need some work with a code node or a community node.
wow @Jon , that helped a lot! i get the data out now.
now its about to get that into fibery. and as there is no build in tool i am trying to use the javascript node but also here my limits are reached fast.
in this javascript i could use the data and use regex to find the key:value pairs and safe that to the fields in the json that is passed.
here is a code example:
const Fibery = require('fibery-unofficial');
const fibery = new Fibery({host: "YOUR_ACCOUNT.fibery.io", token: YOUR_TOKEN});
await fibery.entity.createBatch([
{
'type': 'Project/Activity',
'entity': {
'Activity/name': $json.name //that way I hope to get the name from the google drive downloaded file
}
}
]);
and i would add something like:
var MDdata = $json.data;
const properties = ["Activity", "Contact", "Type", "Date", "Time", "completed"];
const regex = new RegExp(`(${properties.join('|')})::\\s*(.*)`, 'g');
const matches = MDdata.matchAll(regex);
const extractedValues = {};
for (const match of matches) {
const property = match[1];
const value = match[2];
extractedValues[property] = value;
}
const jsonOutput = JSON.stringify(extractedValues, null, 2);
and then get the values out of the jsonOutput to put in the entity fields
but i cant get the first part working cause it gets no access to fibery-unofficial … (i did leave out my fibery data here of course ) is this because i run this locally on my mac? or is there another way to trigger the fibery api? they have a curl version too:
demo:
If you wanted to use the Fibery package in n8n you would need to build a custom docker image that includes it and set the NODE_FUNCTION_ALLOW_EXTERNAL env option to include it. If you have curl commands you can use them in the HTTP Request node as well which may make life a bit easier when you get to that part.
i am pretty close now. i have a javascript ill share here later that extracts all the key:values from my mixed bag of frontmatter and inline stuff. that works amazingly well.
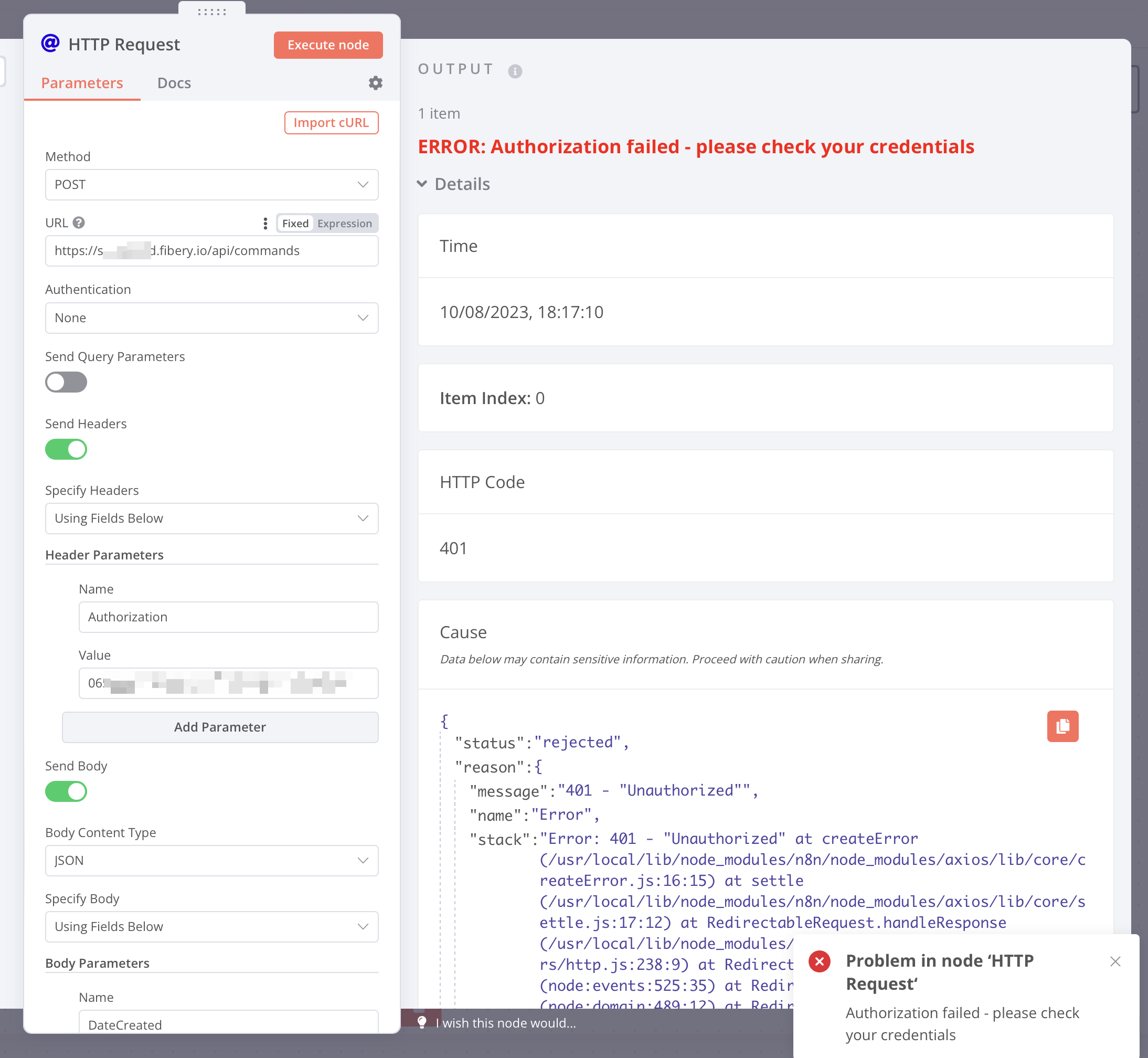
how would i transform the base text cURL (see aboves posting) into your form, so that i dont get permission denied errors?
there are some properties handed over in the curl that the “import curl” is translating into your form, but i cant check if thats where a mismatch is happening)
following javascript is looking for the frontmatter (— frontmatter —) and gets all key:values from there; then gets the key::value inline datapoints (marked by double colon)
and last gets a special section called “meta” that is at the bottom (in a callout where every line starts with > ).
if data is doubled it takes the key:values from the meta (overwrites what it had first)
this is due to a non standard configuration i setup back in the days when YAML frontmatter wasnt handled well in obsidian. that changed in the last 1.4 update though.
var mdData = $json.data;
// Split the markdown content into sections
const sections = mdData.split(/\n---\n/);
// Extract data from frontmatter section
const metaData = {};
const frontmatterLines = sections[0].split('\n');
frontmatterLines.forEach(line => {
const match = line.match(/^\s*([^:]+):\s*(.*)$/);
if (match) {
const key = match[1].trim();
const value = match[2].trim();
metaData[key] = value;
}
});
const sectionsBody = sections[1].split('> [!Meta]');
const bodyLines = sectionsBody[0].split('\n');
bodyLines.forEach(line => {
const match = line.match(/^\s*([^:]+)::\s*(.*)$/);
if (match) {
const key = match[1].trim();
const value = match[2].trim();
metaData[key] = value;
}
});
const metaLines = sectionsBody[1].split('\n');
metaLines.forEach(line => {
const match = line.match(/^\s*> ([^:]+)::\s*(.*)$/);
if (match) {
const key = match[1].trim();
const value = match[2].trim();
metaData[key] = value;
}
});
return(metaData);
In your Authorization header value add Token before it so the value would be something like Token 06xxx it would be safer to set up a header credential under the Authentication section once you have it working as well.
it was another few hours of headache as the tool gave me errors about wrong json and other things. but in the end i figured it out and now it works. thanks!!
for those who are interested here is my workflow - i removed all tokens and secrets.
it takes new files from a folder in google drive
extracts the meta from the YAML Frontmatter, and then from the body of the file
Frontmatter= key: value
Body= key:: value
MetaSection (callout called [!Meta])= key:: value
then it creates a new entity in a Section in Fibery called “KNOWLEDGE” in a DB called “Activities”;
finally it puts the whole document in a rich text field.