Hello, I am trying today to use the AI agent to analyse an image.
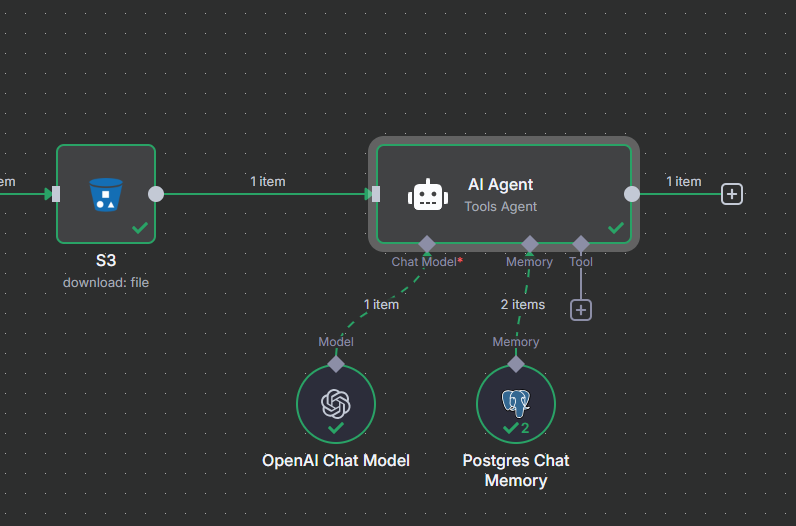
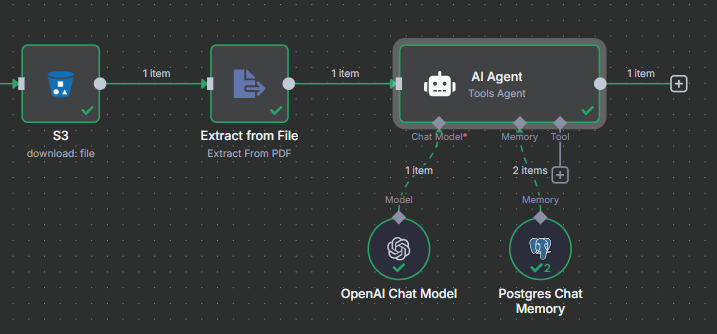
I did setup the workflow with the agent, and the tools I need.
I first tried to add a http tool to download the binary of the image but I got an error with the tool.
Now I try to download the binary before the agent but no matter what I do, the agent seems to not be able to use the binary.
Now the agent tells me to use a tool specialized in OCR.
Is the model not capable of OCR or is it just my workflow broken ?
ok so the binary will contain any type of file and the AI Agent just can pass binary image so thats why the output is ask you to use another AI Models when handle other than image file type, so you need a better logic to handle that its the same problem that we discuss here Openai RAG - how to use a set of files - #6 by Wouter_Nigrini
Hi, thank you for your reply.
Currently, I am trying to pass only images to the agent.
However, in this workflow, I have encountered a new issue: the agent doesn’t always receive the binary or says that he cannot always use it.
The GIF demonstrates that, using the same input, I am getting inconsistent results, including errors indicating that the agent couldn’t retrieve the binary or isn’t capable of utilizing it. It seems the agent might require an OCR model to process the content effectively.
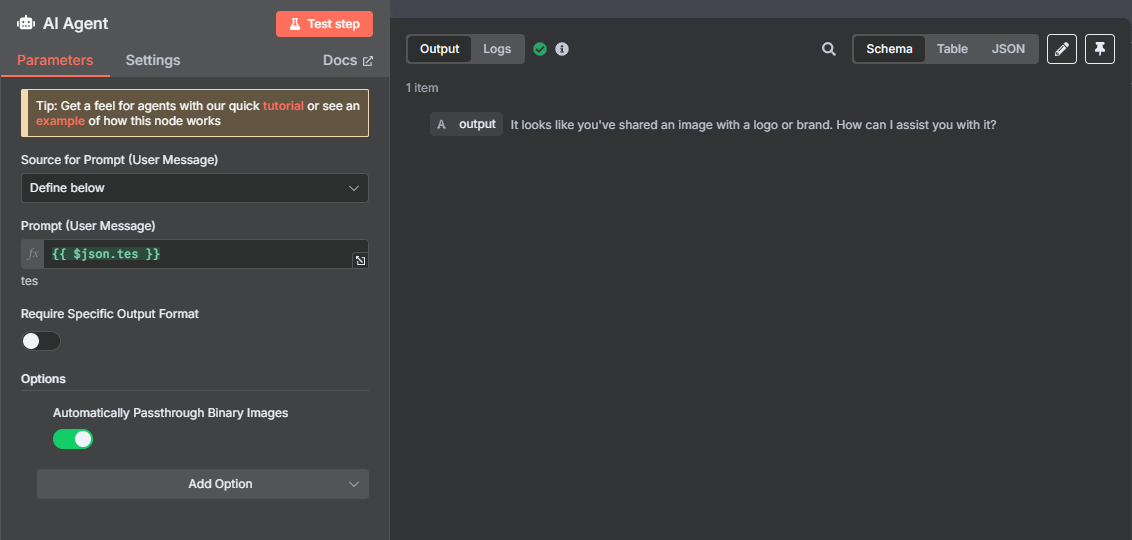
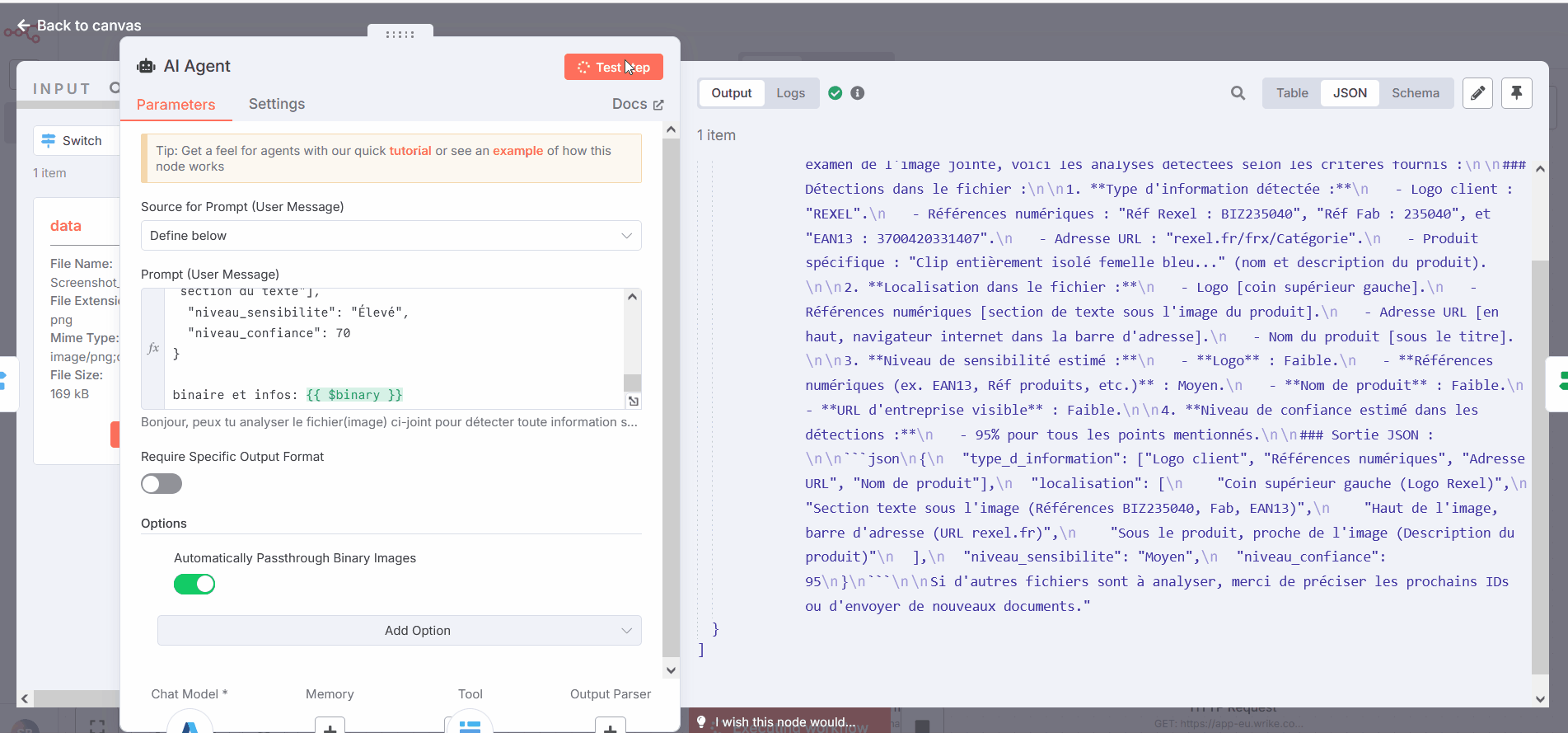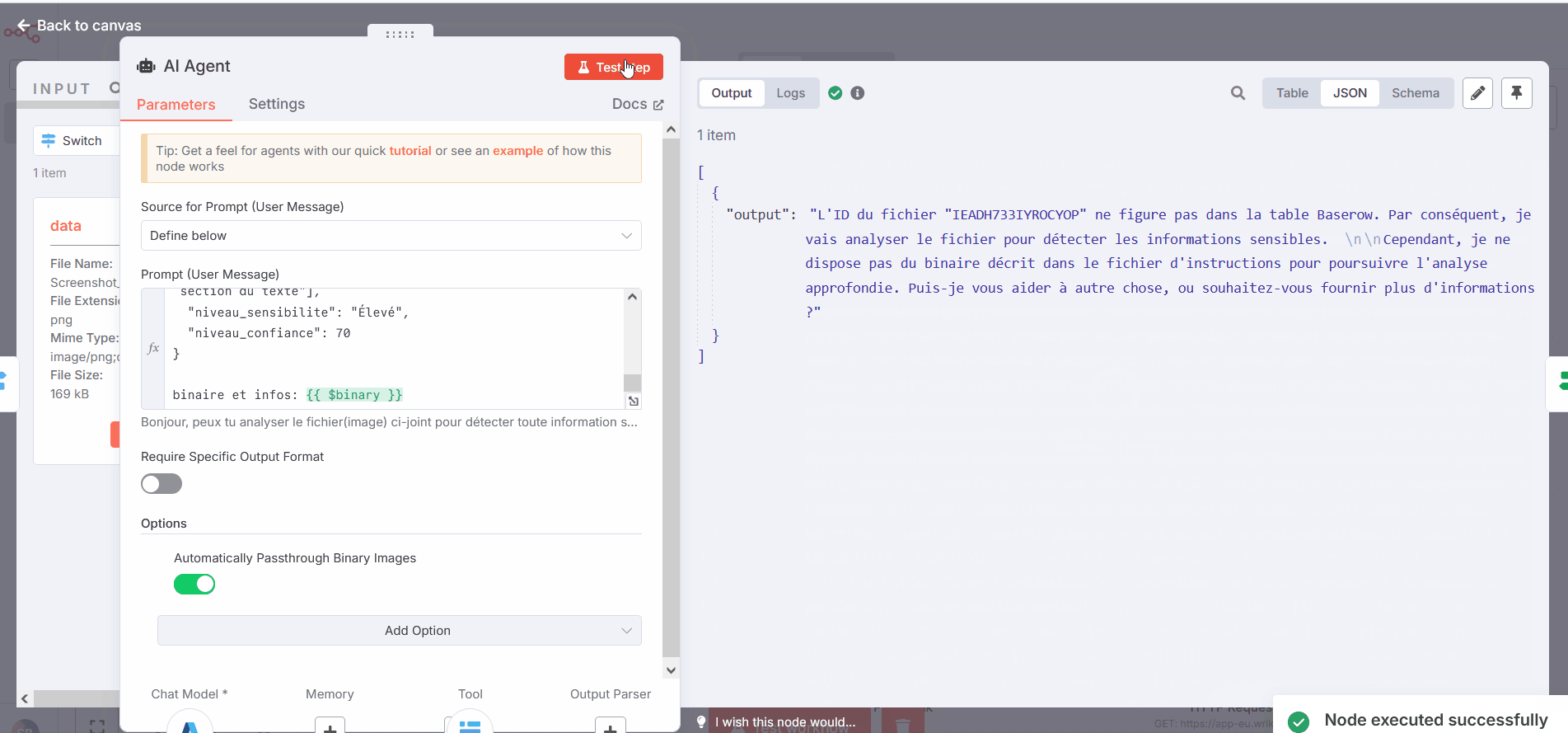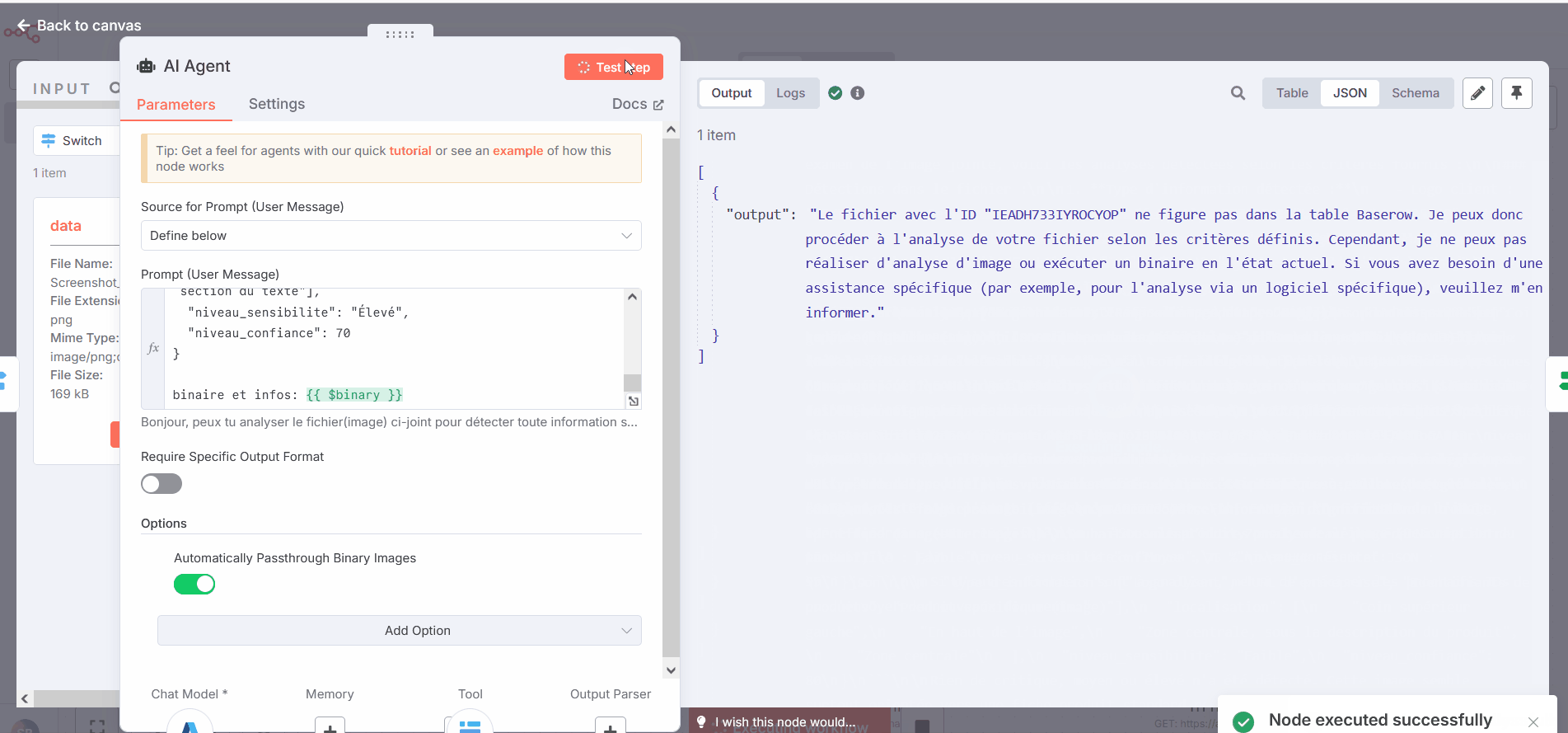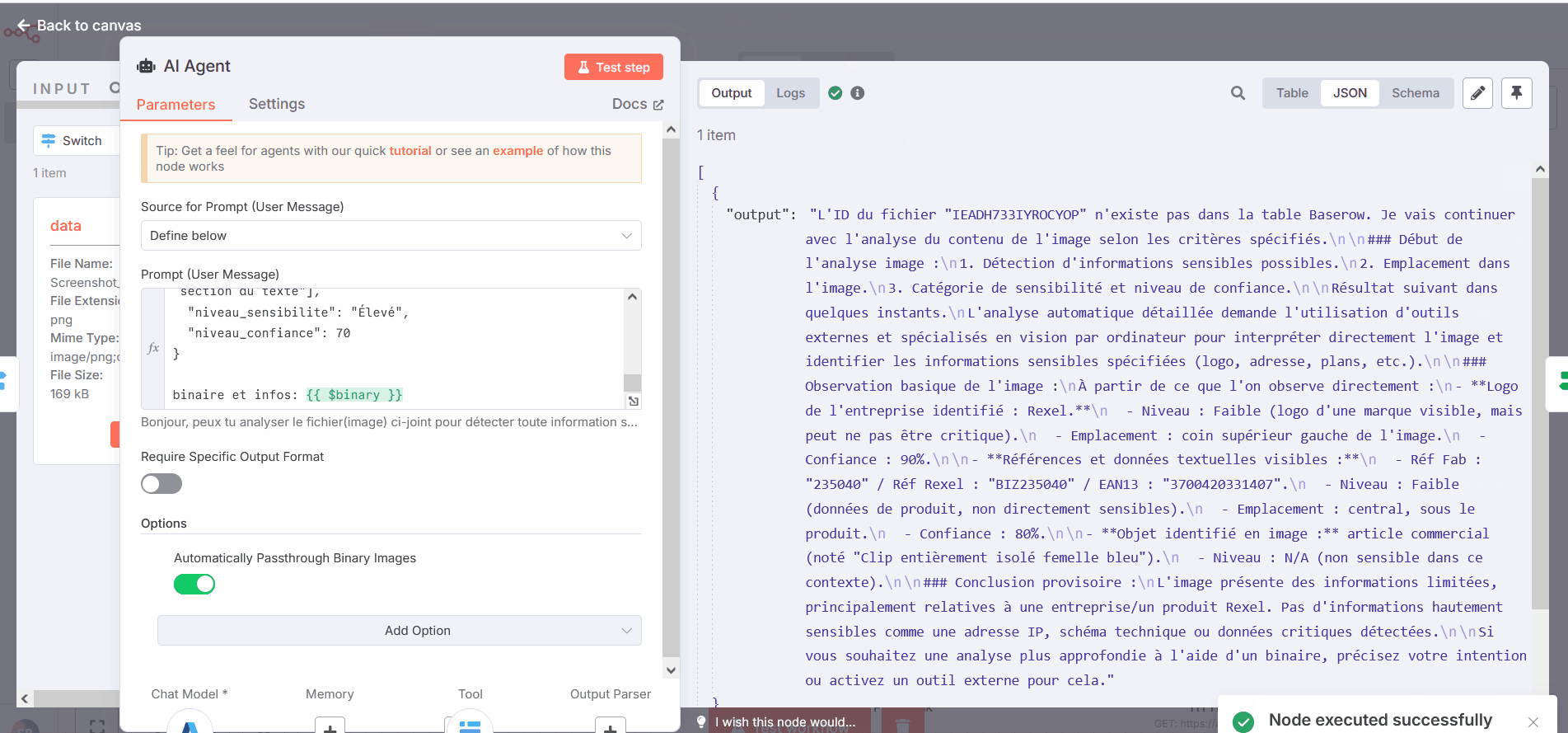
to fix this issue, i tried toadd the binary in the prompt with {{ $binary }}.
It helps, the issue happens less but is still present.
(on the gif, the first test works, the second doesn’t, and same until the last test that works again)
And here on the last test i did, the output says that it can’t analyse the file or a binary, but “based on the informations visible on the image, i can evaluate…” and proceed to give the right informations I need.
I don’t understand…
I need to analyse each file to seek either sensitive information or certain type of pictures.
I started my workflow thinking that the agent could analyse every kind of binaries whether if it’s a pdf or else. You told me that some types of files need special flow. So in my last version of the workflow, I try only with images to have this aspect working.
once the flow works with images, i’ll add pdf then pdf with images.
Also there is more than one item because in the end, i need to give it all my files to scans every one of them
EDIT: I just tried with your version of the switch, only one item is getting through but the agent still gives sometime a good answer and sometime, it tells me that it can’t find any binaries
EDIT² : I may have resolved the issue, I added to the prompt the request to retry to analyse the image if he couldn’t find one and it magicaly seems to work…
Could you tell me more about analysing pdf with images and text inside ?
Hi glad you find out to handle it, for the case of analyzing PDFs with both images and text inside, it’s a more complex case to handle manually because you would need to create regex function logic. In my opinion, an instant solution for this can only be obtained by using the platform https://unstructured.io/ or by using Mistral OCR OCR and Document Understanding | Mistral AI Large Language Models.
Hello, I believe I’ve finally found the best solution for my needs!
Initially, I tried extracting data from PDFs, but I could only retrieve the text from the files.
After extensive research, I discovered the Execute Command node. I also learned that if n8n is running in a Docker container, the image can be rebuilt with additional packages, such as convert.
By leveraging the convert command within the node, I should be able to transform PDFs into PNG files, which I can then pass to my agent. However, I’m struggling a bit to figure out how to save the binary files passed as input to my node, process them within the container to convert them into PNGs, and finally bring them back into the workflow for continued processing.
I believe this would be the best solution to convert PDFs without relying on an external API. The only requirement is to have n8n in a self-hosted setup.