Describe the problem/error/question
I experiment analyzing big documents (5-10K tokens), use gpt-3.5-turbo-1106 for that. Found out when I input such amount of text, this model shows an error:
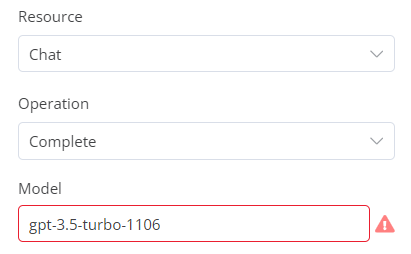
Anyway it still works. I checked several sizes to find the breaking level. It’s somewhere around 12,000 characters. Check out two nodes below.
What is the error message (if any)?
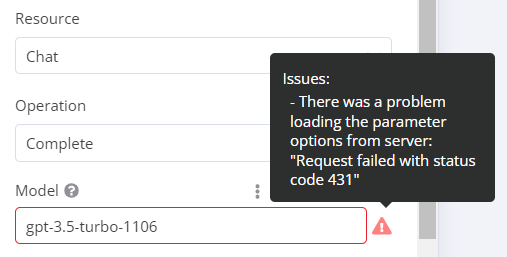
Please share your workflow
Information on your n8n setup
- n8n version: 1.21.1
- Database (default: SQLite): default
- n8n EXECUTIONS_PROCESS setting (default: own, main): default
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker compose
- Operating system: Ubuntu 22